## Confusion Matrix Comparison: Model Performance
### Overview
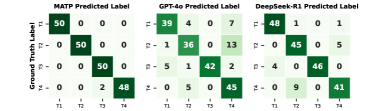
The image presents a comparison of confusion matrices for three different models: MATP, GPT-4o, and DeepSeek-R1. Each matrix visualizes the performance of the model in predicting labels, with the rows representing the ground truth labels and the columns representing the predicted labels. The values within each cell indicate the number of instances that fall into that particular combination of ground truth and predicted labels.
### Components/Axes
* **Title:** The image contains three separate confusion matrices, each with a title indicating the model: "MATP Predicted Label", "GPT-4o Predicted Label", and "DeepSeek-R1 Predicted Label".
* **Y-Axis Label:** "Ground Truth Label" (applies to all three matrices).
* **X-Axis Labels:** T1, T2, T3, T4 (applies to all three matrices).
* **Y-Axis Labels:** T1, T2, T3, T4 (applies to all three matrices).
* **Cell Values:** Each cell contains a numerical value representing the count of instances. The color of the cell indicates the magnitude of the value, with darker shades of green representing higher values.
### Detailed Analysis or ### Content Details
**1. MATP Predicted Label**
| | T1 | T2 | T3 | T4 |
| :---- | :-- | :-- | :-- | :-- |
| **T1** | 50 | 0 | 0 | 0 |
| **T2** | 0 | 50 | 0 | 0 |
| **T3** | 0 | 0 | 50 | 0 |
| **T4** | 0 | 0 | 2 | 48 |
* **Trend:** The MATP model shows perfect classification for T1, T2, and T3. It misclassifies 2 instances of T4 as T3.
**2. GPT-4o Predicted Label**
| | T1 | T2 | T3 | T4 |
| :---- | :-- | :-- | :-- | :-- |
| **T1** | 39 | 4 | 0 | 7 |
| **T2** | 1 | 36 | 0 | 13 |
| **T3** | 5 | 1 | 42 | 2 |
| **T4** | 0 | 5 | 0 | 45 |
* **Trend:** The GPT-4o model shows more varied performance. It has some confusion between all classes, with T1 and T2 being most frequently confused with T4.
**3. DeepSeek-R1 Predicted Label**
| | T1 | T2 | T3 | T4 |
| :---- | :-- | :-- | :-- | :-- |
| **T1** | 48 | 1 | 0 | 1 |
| **T2** | 0 | 45 | 0 | 5 |
| **T3** | 4 | 0 | 46 | 0 |
| **T4** | 0 | 9 | 0 | 41 |
* **Trend:** The DeepSeek-R1 model performs well, but has some confusion. T2 is confused with T4, T1 is confused with T2, and T4 is confused with T2.
### Key Observations
* **MATP:** Achieves perfect classification for T1, T2, and T3. It only misclassifies T4 instances as T3.
* **GPT-4o:** Shows more confusion across all classes, with a tendency to misclassify T1 and T2 as T4.
* **DeepSeek-R1:** Generally performs well, but exhibits some confusion between T1 and T2, and between T2 and T4.
### Interpretation
The confusion matrices provide a clear visual comparison of the performance of the three models. MATP appears to be the most accurate, achieving perfect classification for three out of the four classes. GPT-4o shows the most confusion, indicating that it struggles to accurately distinguish between the different classes. DeepSeek-R1 falls in between, performing reasonably well but with some noticeable confusion between specific pairs of classes.
The data suggests that MATP is the most reliable model for this particular classification task. The errors made by GPT-4o and DeepSeek-R1 could be further investigated to identify the specific characteristics of the instances that are being misclassified. This information could then be used to improve the performance of these models.