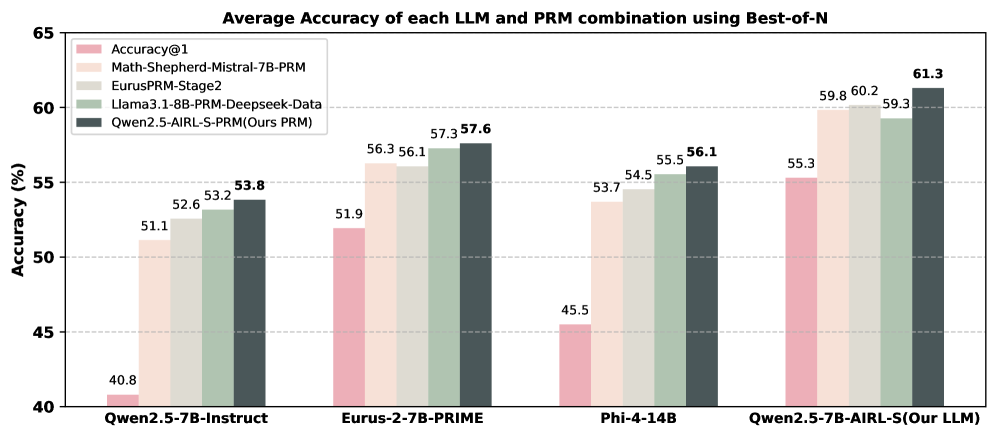
## Bar Chart: Average Accuracy of each LLM and PRM combination using Best-of-N
### Overview
The chart compares the average accuracy of different large language model (LLM) and prompt retrieval model (PRM) combinations across four LLM variants. Accuracy is measured using Best-of-N sampling, with results presented as percentages. The chart includes five data series: Accuracy@1 (baseline) and four PRM configurations.
### Components/Axes
- **X-axis**: LLM variants (categorical)
- Qwen2.5-7B-Instruct
- Eurus-2-7B-PRIME
- Phi-4-14B
- Qwen2.5-7B-AIRL-S (Our LLM)
- **Y-axis**: Accuracy (%) from 40 to 65
- **Legend**: Top-left corner with five entries:
- Pink: Accuracy@1 (baseline)
- Light orange: Math-Shepherd-Mistral-7B-PRM
- Light green: EurusPRM-Stage2
- Dark green: Llama3.1-8B-PRM-Deepseek-Data
- Dark gray: Qwen2.5-AIRL-S-PRM (Ours PRM)
### Detailed Analysis
#### Qwen2.5-7B-Instruct
- Accuracy@1: 40.8% (pink)
- Math-Shepherd-Mistral-7B-PRM: 51.1% (light orange)
- EurusPRM-Stage2: 52.6% (light green)
- Llama3.1-8B-PRM-Deepseek-Data: 53.2% (dark green)
- Qwen2.5-AIRL-S-PRM: 53.8% (dark gray)
#### Eurus-2-7B-PRIME
- Accuracy@1: 51.9% (pink)
- Math-Shepherd-Mistral-7B-PRM: 56.3% (light orange)
- EurusPRM-Stage2: 56.1% (light green)
- Llama3.1-8B-PRM-Deepseek-Data: 57.3% (dark green)
- Qwen2.5-AIRL-S-PRM: 57.6% (dark gray)
#### Phi-4-14B
- Accuracy@1: 45.5% (pink)
- Math-Shepherd-Mistral-7B-PRM: 53.7% (light orange)
- EurusPRM-Stage2: 54.5% (light green)
- Llama3.1-8B-PRM-Deepseek-Data: 55.5% (dark green)
- Qwen2.5-AIRL-S-PRM: 56.1% (dark gray)
#### Qwen2.5-7B-AIRL-S (Our LLM)
- Accuracy@1: 55.3% (pink)
- Math-Shepherd-Mistral-7B-PRM: 59.8% (light orange)
- EurusPRM-Stage2: 60.2% (light green)
- Llama3.1-8B-PRM-Deepseek-Data: 59.3% (dark green)
- Qwen2.5-AIRL-S-PRM: 61.3% (dark gray)
### Key Observations
1. **Consistent PRM Performance**: All PRM configurations outperform Accuracy@1 across all LLM variants.
2. **Best-of-N Effect**: Accuracy improves with Best-of-N sampling, with the highest gains in Qwen2.5-7B-AIRL-S (Our LLM).
3. **Top Performer**: Qwen2.5-AIRL-S-PRM (dark gray) achieves the highest accuracy (61.3%) in the final LLM variant.
4. **Baseline Variability**: Accuracy@1 ranges from 40.8% (Qwen2.5-7B-Instruct) to 55.3% (Qwen2.5-7B-AIRL-S).
### Interpretation
The data demonstrates that PRM integration significantly enhances LLM performance, with the "Ours PRM" (Qwen2.5-AIRL-S-PRM) consistently achieving the highest accuracy across all LLM variants. The Qwen2.5-7B-AIRL-S model shows the most substantial improvement (from 55.3% baseline to 61.3% with PRM), suggesting that its architecture synergizes particularly well with the PRM. The Math-Shepherd-Mistral-7B-PRM and EurusPRM-Stage2 configurations also show strong performance, though slightly behind the "Ours PRM" variant. The progressive increase in baseline accuracy from Qwen2.5-7B-Instruct (40.8%) to Qwen2.5-7B-AIRL-S (55.3%) indicates that model architecture improvements alone contribute to performance gains, but PRM integration remains critical for maximizing accuracy.