## Line Graphs: Performance Comparison of Initialization Methods
### Overview
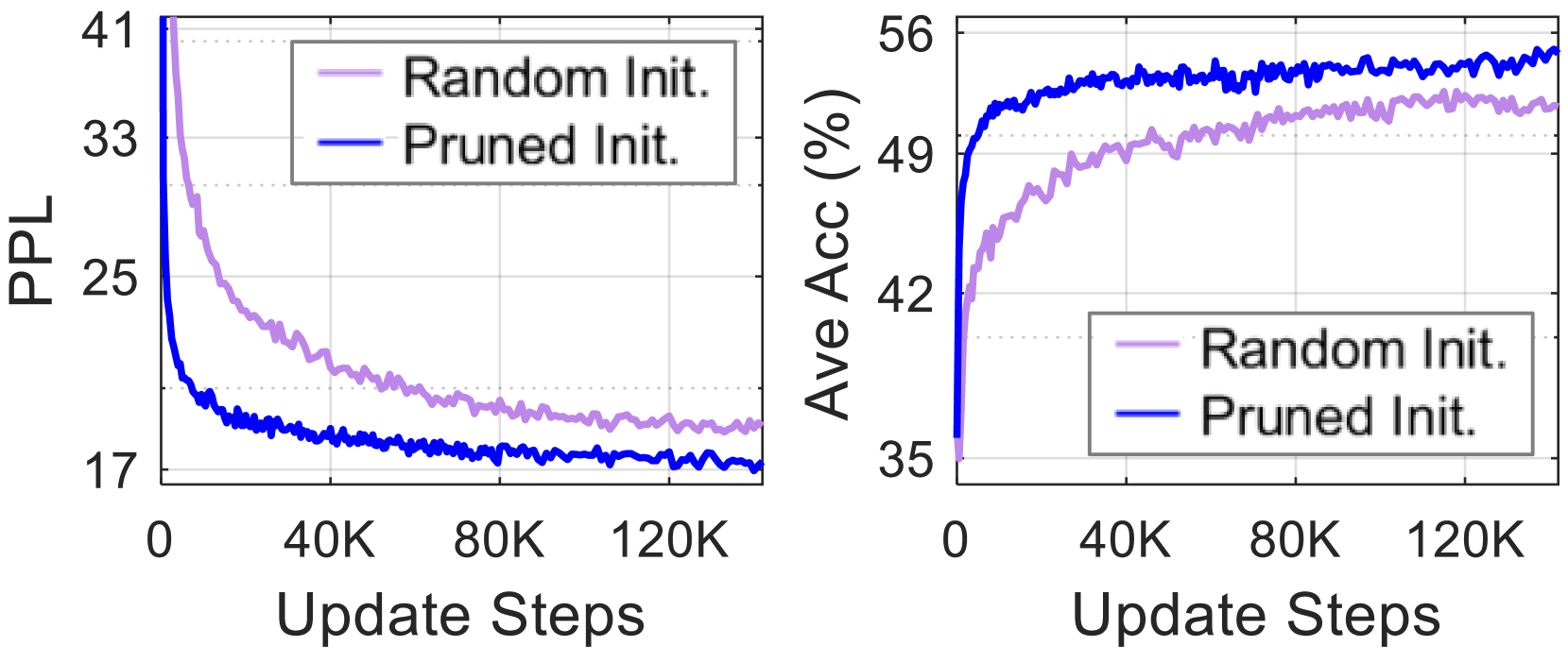
The image contains two side-by-side line graphs comparing the performance of two initialization methods ("Random Init." and "Pruned Init.") across update steps. The left graph tracks **PPL** (Perplexity), while the right graph tracks **Ave Acc** (Average Accuracy in percentage). Both graphs show trends over 120K update steps.
---
### Components/Axes
#### Left Graph (PPL)
- **Y-axis**: PPL (Perplexity), scaled from 17 to 41.
- **X-axis**: Update Steps, scaled from 0 to 120K (increments of 40K).
- **Legend**:
- Purple line: "Random Init."
- Blue line: "Pruned Init."
- **Legend Position**: Top-left corner of the graph.
#### Right Graph (Ave Acc %)
- **Y-axis**: Ave Acc (%), scaled from 35 to 56.
- **X-axis**: Update Steps, identical to the left graph (0 to 120K).
- **Legend**:
- Purple line: "Random Init."
- Blue line: "Pruned Init."
- **Legend Position**: Top-left corner of the graph.
---
### Detailed Analysis
#### Left Graph (PPL)
- **Random Init. (Purple)**:
- Starts at ~41 PPL at 0 steps.
- Gradually decreases to ~17 PPL by 120K steps.
- Slope: Steady decline with minor fluctuations.
- **Pruned Init. (Blue)**:
- Starts at ~41 PPL at 0 steps.
- Sharp decline to ~17 PPL by ~40K steps.
- Stabilizes near 17 PPL with minor oscillations.
#### Right Graph (Ave Acc %)
- **Random Init. (Purple)**:
- Starts at ~35% at 0 steps.
- Gradual increase to ~49% by 120K steps.
- Slope: Slow, steady rise with minor fluctuations.
- **Pruned Init. (Blue)**:
- Starts at ~35% at 0 steps.
- Rapid rise to ~56% by ~40K steps.
- Stabilizes near 56% with minor oscillations.
---
### Key Observations
1. **Pruned Init. outperforms Random Init.** in both metrics:
- Achieves lower PPL faster (by ~40K steps).
- Reaches higher accuracy earlier (by ~40K steps).
2. **Convergence**:
- Both methods stabilize after ~80K steps, but Pruned Init. maintains superior performance.
3. **Trend Consistency**:
- PPL and Ave Acc trends are inversely related (lower PPL correlates with higher accuracy).
---
### Interpretation
The data demonstrates that **Pruned Initialization** significantly accelerates model convergence compared to **Random Initialization**. This suggests that pruning techniques (e.g., weight pruning, parameter selection) improve training efficiency by reducing the number of updates required to achieve optimal performance. The inverse relationship between PPL and accuracy highlights the trade-off between model uncertainty and predictive power. These findings are critical for optimizing training pipelines in machine learning, where computational resources are often constrained.