\n
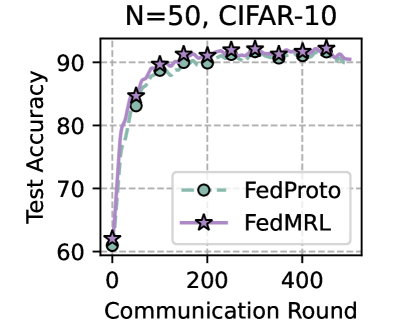
## Line Chart: Test Accuracy vs. Communication Round
### Overview
This line chart displays the test accuracy of two federated learning methods, FedProto and FedMRL, as a function of the communication round. The chart is labeled with "N=50, CIFAR-10" at the top, indicating the number of clients (N=50) and the dataset used (CIFAR-10).
### Components/Axes
* **X-axis:** Communication Round (ranging from approximately 0 to 500, with markers at 0, 100, 200, 300, 400, and 500).
* **Y-axis:** Test Accuracy (ranging from approximately 60 to 95, with markers at 60, 70, 80, 90).
* **Data Series 1:** FedProto (represented by a light-green line with circular markers).
* **Data Series 2:** FedMRL (represented by a light-purple line with star-shaped markers).
* **Legend:** Located in the bottom-right corner, clearly labeling each data series with its corresponding color and marker.
### Detailed Analysis
* **FedProto (Green Line):** The line starts at approximately 68% accuracy at Communication Round 0. It rapidly increases to around 88% accuracy by Communication Round 100. The accuracy plateaus around 92% between Communication Rounds 200 and 500, with minor fluctuations.
* (0, 68)
* (100, 88)
* (200, 91)
* (300, 92)
* (400, 92)
* (500, 92)
* **FedMRL (Purple Line):** The line begins at approximately 62% accuracy at Communication Round 0. It shows a steeper initial increase than FedProto, reaching around 89% accuracy by Communication Round 100. The accuracy continues to increase, reaching approximately 93% by Communication Round 200, and then plateaus around 93-94% between Communication Rounds 200 and 500.
* (0, 62)
* (100, 89)
* (200, 93)
* (300, 93)
* (400, 94)
* (500, 93)
### Key Observations
* Both FedProto and FedMRL demonstrate a significant increase in test accuracy with increasing communication rounds.
* FedMRL initially outperforms FedProto in terms of accuracy gain, but both methods converge to similar accuracy levels after approximately 200 communication rounds.
* The accuracy plateaus for both methods after 200 communication rounds, suggesting diminishing returns from further communication.
### Interpretation
The chart demonstrates the effectiveness of both FedProto and FedMRL in improving model accuracy through federated learning on the CIFAR-10 dataset with 50 clients. The initial rapid increase in accuracy indicates that the models are quickly learning from the distributed data. The eventual plateau suggests that the models have reached a point of convergence, where further communication does not significantly improve performance. The slight initial advantage of FedMRL could be due to its specific optimization strategy, but the ultimate convergence to similar accuracy levels suggests that both methods are viable options for this task. The N=50 and CIFAR-10 parameters provide context for the performance observed, and the results may vary with different dataset sizes or numbers of clients. The data suggests that a communication round of around 200 is sufficient to achieve good performance, and further communication may not be necessary.