## Radar Chart: Model Performance Comparison
### Overview
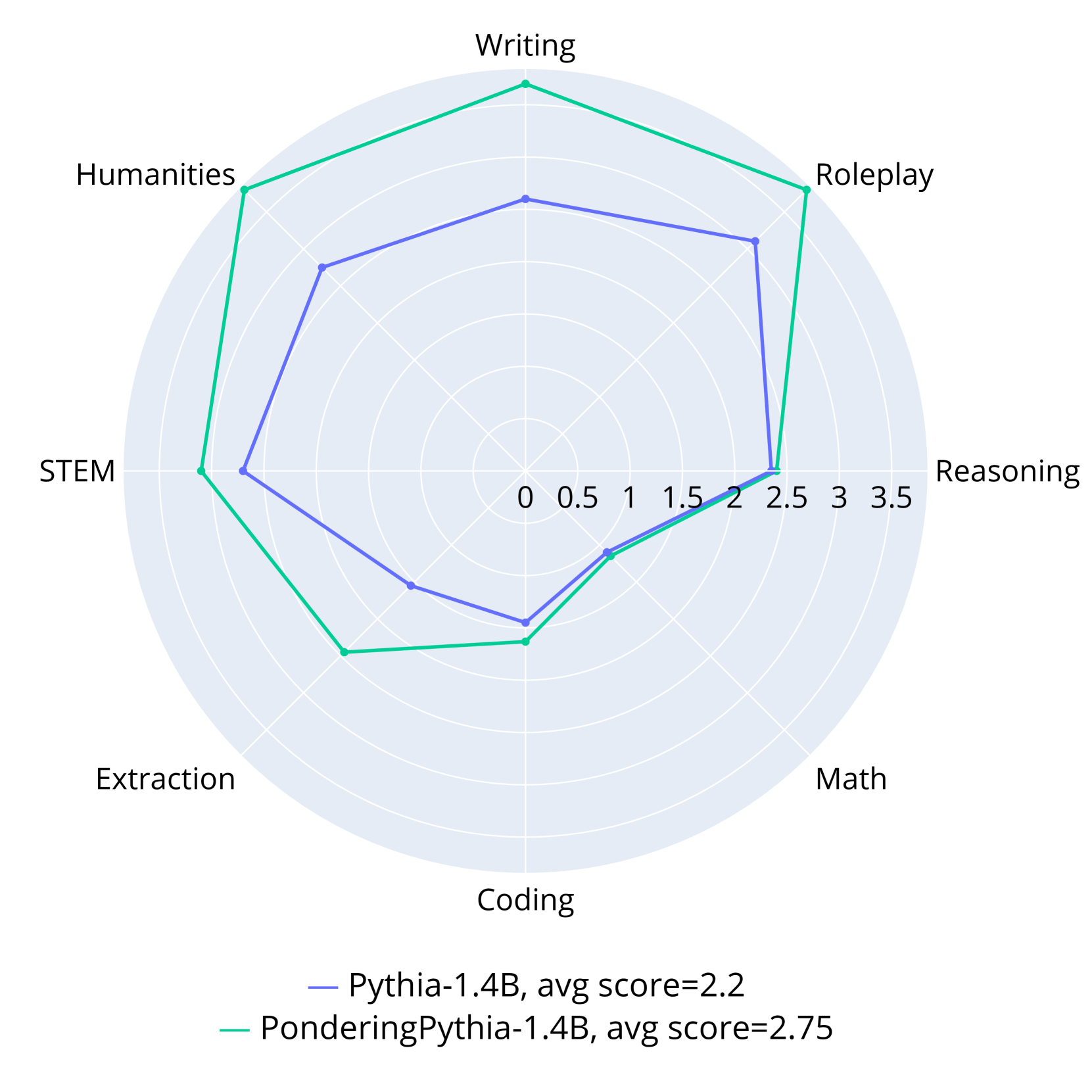
The image is a radar chart comparing the performance of two models, "Pythia-1.4B" and "PonderingPythia-1.4B", across several categories: Writing, Roleplay, Reasoning, Math, Coding, Extraction, STEM, and Humanities. The chart visualizes the strengths and weaknesses of each model in these different areas.
### Components/Axes
* **Axes:** The chart has eight axes, each representing a different category: Writing, Roleplay, Reasoning, Math, Coding, Extraction, STEM, and Humanities.
* **Scale:** The radial scale ranges from 0 to 3.5, with increments of 0.5.
* **Legend:** Located at the bottom of the chart:
* Blue line: Pythia-1.4B, avg score = 2.2
* Green line: PonderingPythia-1.4B, avg score = 2.75
### Detailed Analysis
* **Pythia-1.4B (Blue Line):**
* Writing: Approximately 2.0
* Roleplay: Approximately 2.3
* Reasoning: Approximately 2.3
* Math: Approximately 1.8
* Coding: Approximately 1.2
* Extraction: Approximately 1.5
* STEM: Approximately 1.7
* Humanities: Approximately 1.8
The Pythia-1.4B model shows relatively consistent performance across all categories, with slightly higher scores in Roleplay and Reasoning.
* **PonderingPythia-1.4B (Green Line):**
* Writing: Approximately 3.5
* Roleplay: Approximately 3.0
* Reasoning: Approximately 2.5
* Math: Approximately 1.9
* Coding: Approximately 1.4
* Extraction: Approximately 1.0
* STEM: Approximately 2.5
* Humanities: Approximately 3.0
The PonderingPythia-1.4B model excels in Writing, Roleplay, Humanities, and STEM, but performs relatively weaker in Extraction and Coding.
### Key Observations
* PonderingPythia-1.4B consistently outperforms Pythia-1.4B in Writing, Roleplay, Humanities, and STEM.
* Both models have relatively lower scores in Coding and Extraction.
* PonderingPythia-1.4B has a higher average score (2.75) compared to Pythia-1.4B (2.2).
### Interpretation
The radar chart provides a clear visual comparison of the two models' capabilities across different domains. PonderingPythia-1.4B appears to be a more versatile model, particularly strong in creative and knowledge-based tasks (Writing, Roleplay, Humanities) and STEM, while Pythia-1.4B offers a more balanced performance profile. The lower scores in Coding and Extraction for both models suggest potential areas for improvement in future iterations. The higher average score of PonderingPythia-1.4B indicates that it is generally a better-performing model overall.