\n
## Radar Chart: Model Performance Comparison
### Overview
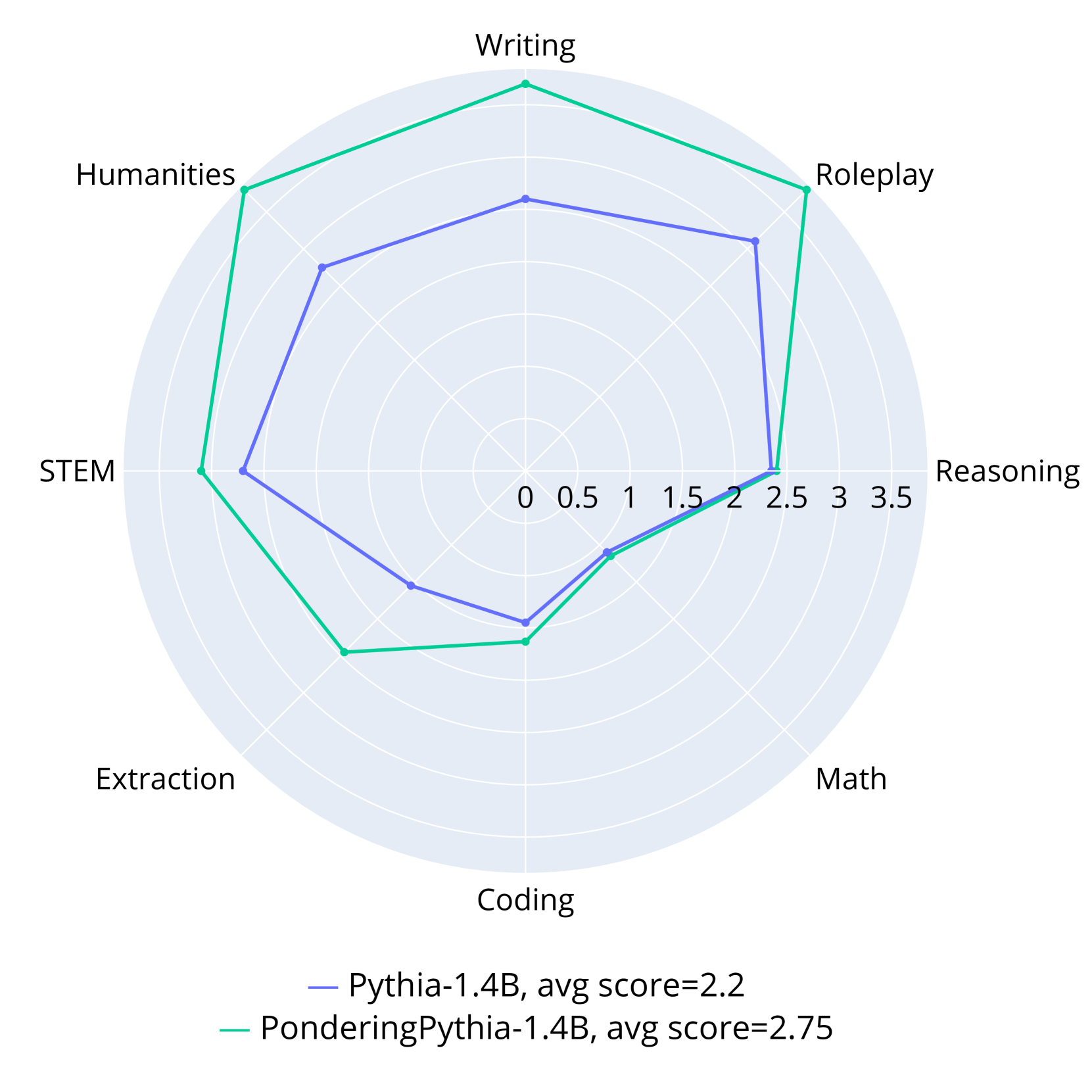
This image presents a radar chart comparing the performance of two language models, "Pythia-1.4B" and "PonderingPythia-1.4B", across eight different categories. The chart uses a radial layout with each axis representing a specific skill or domain. The performance score ranges from 0 to 3.5.
### Components/Axes
* **Axes Labels (Categories):** Writing, Roleplay, Reasoning, Math, Coding, Extraction, STEM, Humanities. These are arranged clockwise around the chart.
* **Radial Scale:** The chart features a radial scale ranging from 0 to 3.5, with increments of 0.5. The scale is positioned at the center of the chart.
* **Legend:** Located at the bottom-right of the chart.
* **Pythia-1.4B:** Represented by a solid grey line. Average score: 2.2
* **PonderingPythia-1.4B:** Represented by a solid teal line. Average score: 2.75
### Detailed Analysis
The chart displays two polygonal lines representing the performance of each model across the eight categories.
**Pythia-1.4B (Grey Line):**
* **Writing:** Approximately 2.5
* **Roleplay:** Approximately 2.0
* **Reasoning:** Approximately 2.2
* **Math:** Approximately 1.8
* **Coding:** Approximately 2.0
* **Extraction:** Approximately 1.5
* **STEM:** Approximately 1.2
* **Humanities:** Approximately 2.8
The grey line shows a relatively consistent performance across categories, with a slight dip in STEM and Extraction, and a peak in Humanities.
**PonderingPythia-1.4B (Teal Line):**
* **Writing:** Approximately 3.2
* **Roleplay:** Approximately 3.0
* **Reasoning:** Approximately 3.0
* **Math:** Approximately 2.5
* **Coding:** Approximately 2.7
* **Extraction:** Approximately 2.2
* **STEM:** Approximately 2.5
* **Humanities:** Approximately 2.8
The teal line generally exhibits higher scores than the grey line across all categories. It shows a strong performance in Writing, Roleplay, and Reasoning, with a slight dip in Humanities.
### Key Observations
* PonderingPythia-1.4B consistently outperforms Pythia-1.4B across all evaluated categories.
* Both models show relatively lower performance in STEM and Extraction compared to other categories.
* Pythia-1.4B has its highest score in Humanities, while PonderingPythia-1.4B excels in Writing, Roleplay, and Reasoning.
* The average score for Pythia-1.4B is 2.2, while the average score for PonderingPythia-1.4B is 2.75, indicating an overall performance advantage for the latter.
### Interpretation
The radar chart effectively visualizes the comparative strengths and weaknesses of the two language models. The data suggests that PonderingPythia-1.4B is a more capable model overall, demonstrating superior performance in a wide range of tasks. The lower scores in STEM and Extraction for both models might indicate areas where further training or architectural improvements are needed. The difference in performance between the two models is particularly noticeable in areas like Writing, Roleplay, and Reasoning, suggesting that the modifications made to create PonderingPythia-1.4B have significantly enhanced its capabilities in these domains. The chart provides a clear and concise overview of the models' relative performance, facilitating informed decision-making regarding their application in various NLP tasks.