## Radar Chart: Comparative Performance of Pythia-1.4B and PonderingPythia-1.4B
### Overview
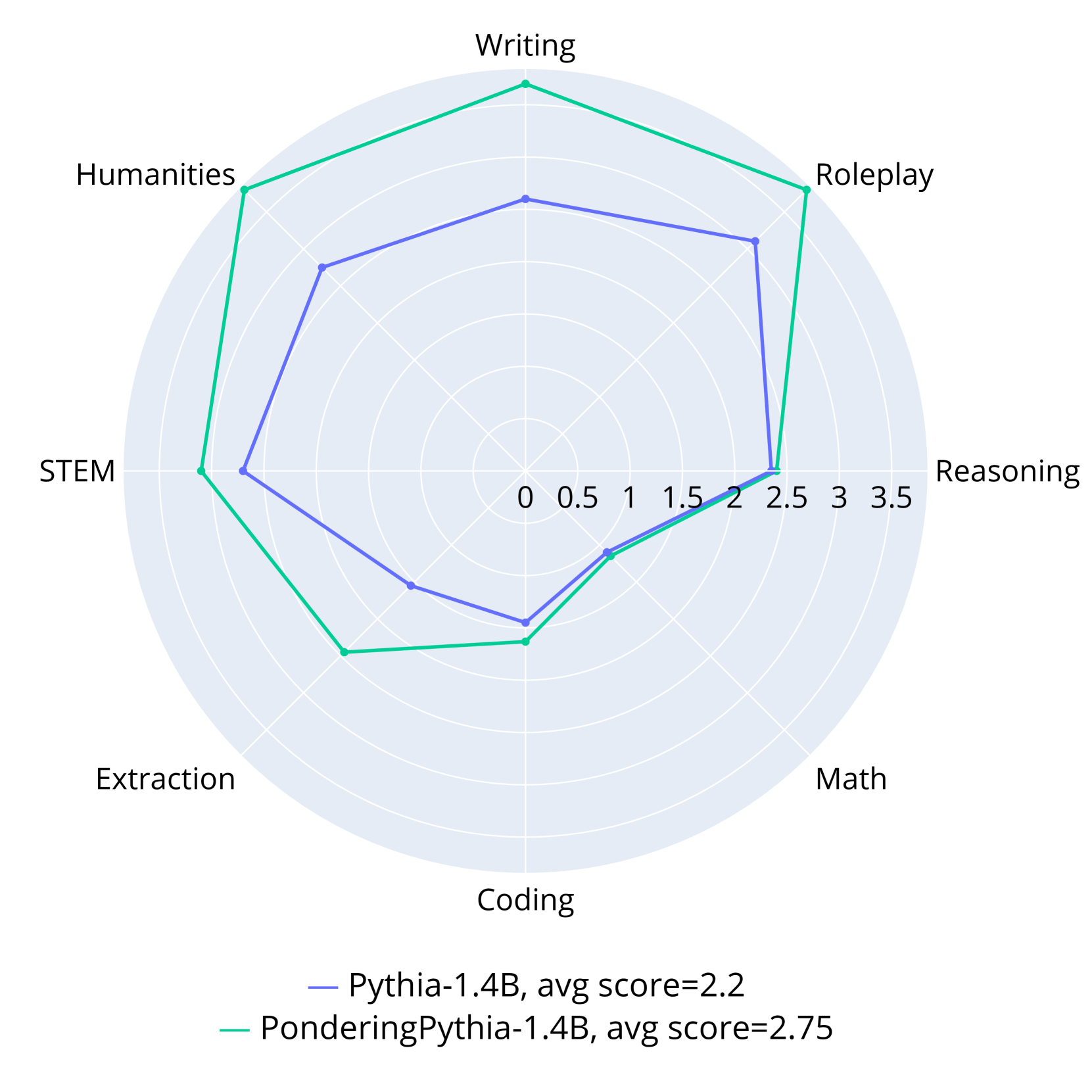
The image is a radar chart comparing the performance of two language models, Pythia-1.4B (blue line) and PonderingPythia-1.4B (teal line), across eight categories: Writing, Roleplay, Reasoning, Math, Coding, Extraction, STEM, and Humanities. The chart uses a circular layout with radial axes scaled from 0 to 3.5. Average scores are provided: Pythia-1.4B (2.2) and PonderingPythia-1.4B (2.75).
---
### Components/Axes
- **Categories (Axes):**
- Writing (top)
- Roleplay (top-right)
- Reasoning (right)
- Math (bottom-right)
- Coding (bottom)
- Extraction (bottom-left)
- STEM (left)
- Humanities (top-left)
- **Legend:**
- **Blue line:** Pythia-1.4B (avg score = 2.2)
- **Teal line:** PonderingPythia-1.4B (avg score = 2.75)
- **Axis Markers:**
- Radial scale increments: 0, 0.5, 1, 1.5, 2, 2.5, 3, 3.5
---
### Detailed Analysis
1. **PonderingPythia-1.4B (Teal Line):**
- **Highest Scores:**
- Roleplay (~3.5)
- Humanities (~3.2)
- Writing (~3.0)
- **Lowest Score:**
- Coding (~1.2)
- **Trend:** Dominates in creative/linguistic tasks (Roleplay, Humanities, Writing) but underperforms in technical tasks (Coding, Math).
2. **Pythia-1.4B (Blue Line):**
- **Highest Score:**
- Reasoning (~2.8)
- **Lowest Score:**
- Math (~1.5)
- **Trend:** Stronger in analytical tasks (Reasoning) but weaker in Math and Coding compared to PonderingPythia.
3. **Shared Patterns:**
- Both models score highest in Reasoning and Humanities.
- Both struggle with Math and Coding, though PonderingPythia performs slightly better in Math.
---
### Key Observations
- **Performance Gap:** PonderingPythia-1.4B consistently outperforms Pythia-1.4B across most categories, with an average score 0.55 points higher.
- **Outliers:**
- PonderingPythia’s extreme strength in Roleplay (~3.5) vs. Pythia’s moderate score (~2.5).
- Pythia’s slight edge in Reasoning (~2.8 vs. ~2.5).
- **Weaknesses:** Both models score below 2.0 in Math and Coding, suggesting systemic limitations in technical reasoning.
---
### Interpretation
The data suggests that **PonderingPythia-1.4B** is optimized for creative and linguistic tasks (e.g., Roleplay, Humanities), while **Pythia-1.4B** excels in analytical reasoning. However, both models share critical weaknesses in Math and Coding, indicating potential gaps in training data or architectural design for technical problem-solving. The disparity in Roleplay performance highlights PonderingPythia’s specialization in narrative generation, whereas Pythia’s balanced but lower scores suggest a more generalized but less specialized capability.
**Critical Insight:** The chart underscores the trade-off between specialization (PonderingPythia) and generalization (Pythia), with neither model achieving high performance in all domains. This aligns with Peircean principles of abductive reasoning: the models’ strengths and weaknesses reflect their design priorities, leaving room for hybrid approaches to address systemic gaps.