TECHNICAL ASSET FINGERPRINT
9619ab4ad9156a8236f2ec60
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: healer-alpha-free VERSION 1
RUNTIME: free/openrouter/healer-alpha
INTEL_VERIFIED
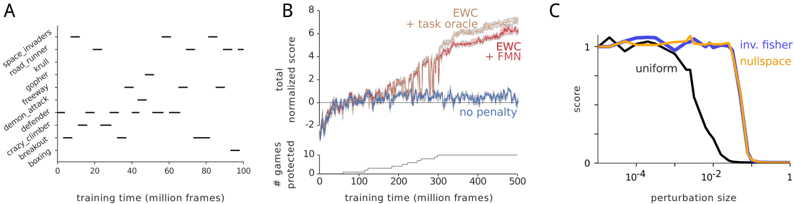
## [Multi-Panel Technical Figure]: Performance and Robustness Analysis of Machine Learning Methods
### Overview
The image is a composite figure containing three distinct subplots labeled A, B, and C. It presents data related to the training progression, performance, and robustness of machine learning models, likely in the context of reinforcement learning on Atari games. The figure compares different continual learning or regularization methods.
### Components/Axes
The figure is divided into three panels arranged horizontally.
**Panel A (Left):**
* **Type:** Scatter plot / Raster plot.
* **Y-axis:** Labeled with a list of Atari game titles. From top to bottom: `space_invaders`, `road_runner`, `qbert`, `gopher`, `tourney`, `demon_attack`, `defender`, `crazy_climber`, `breakout`, `beam_rider`.
* **X-axis:** Labeled "training time (million frames)". Scale ranges from 0 to 100 with major ticks at 0, 20, 40, 60, 80, 100.
* **Data:** Black horizontal dashes indicate specific points in training time where each game was presumably encountered or evaluated.
**Panel B (Center):**
* **Type:** Composite chart with a line graph (top) and a bar/step chart (bottom).
* **Top Chart:**
* **Y-axis:** Labeled "normalized total score". Scale ranges from 0 to 8 with major ticks at 0, 2, 4, 6, 8.
* **X-axis:** Shared with the bottom chart, labeled "training time (million frames)". Scale ranges from 0 to 500 with major ticks at 0, 100, 200, 300, 400, 500.
* **Legend:** Located in the top-right corner. Contains four entries:
* `+ task oracle` (Light orange line)
* `EWC` (Red line)
* `+ FMN` (Dark red/brown line)
* `no penalty` (Blue line)
* **Bottom Chart:**
* **Y-axis:** Labeled "# games protected". Scale ranges from 0 to 10 with major ticks at 0, 5, 10.
* **X-axis:** "training time (million frames)" (shared with top chart).
* **Data:** A single grey step-line showing an increasing trend.
**Panel C (Right):**
* **Type:** Line graph.
* **Y-axis:** Labeled "score". Scale ranges from 0 to 1 with major ticks at 0, 0.5, 1.
* **X-axis:** Labeled "perturbation size". Scale is logarithmic, with major ticks at 10⁻⁴, 10⁻², 1.
* **Legend:** Located in the top-right corner. Contains three entries:
* `uniform` (Black line)
* `inv. fisher` (Blue line)
* `nullspace` (Orange line)
### Detailed Analysis
**Panel A Analysis:**
This plot shows the training schedule across 10 Atari games. The games are not trained on simultaneously but are interleaved throughout the 100 million frame training period. For example, `space_invaders` is trained on at approximately 10, 50, 70, and 90 million frames. `beam_rider` is only trained on at the very end (~95 million frames). The pattern suggests a continual learning setup where tasks (games) are revisited periodically.
**Panel B Analysis:**
* **Top Chart (Performance):**
* **Trend Verification:**
* `+ task oracle` (Light orange): Shows a steep, steady upward trend, reaching the highest normalized score (~7.5) by 500 million frames. This represents an ideal upper bound.
* `EWC` (Red) and `+ FMN` (Dark red): Both show a strong upward trend, closely tracking each other. They plateau around a score of 6-6.5 after 400 million frames, performing significantly better than the baseline but below the oracle.
* `no penalty` (Blue): Shows an initial increase but then fluctuates noisily around a score of 1-2 after 100 million frames, indicating catastrophic forgetting or failure to learn effectively across tasks.
* **Data Points (Approximate at 500M frames):**
* `+ task oracle`: ~7.5
* `EWC`: ~6.3
* `+ FMN`: ~6.5
* `no penalty`: ~1.5
* **Bottom Chart (Protection):**
* The number of "protected" games increases in a step-wise fashion over training time. It starts at 0, reaches ~2 by 200M frames, ~5 by 300M frames, and ~9 by 500M frames. This metric likely counts how many tasks the model has successfully retained knowledge of without forgetting.
**Panel C Analysis:**
This chart measures robustness to input perturbations.
* **Trend Verification:**
* `uniform` (Black): Maintains a high score (~1) for very small perturbations (<10⁻³). The score then drops sharply, reaching near 0 by a perturbation size of 10⁻¹.
* `inv. fisher` (Blue) and `nullspace` (Orange): Both maintain a high, stable score (~1) across a much wider range of perturbation sizes. Their performance only begins to degrade slightly at the largest perturbation sizes (~1), but remains far above the `uniform` method.
* **Key Data Point:** The critical divergence occurs between perturbation sizes of 10⁻³ and 10⁻¹, where the `uniform` method's performance collapses while the other two remain robust.
### Key Observations
1. **Method Superiority:** In Panel B, both `EWC` and `EWC+FMN` dramatically outperform the `no penalty` baseline in continual learning, achieving scores 4-5 times higher. The `+ task oracle` sets a clear performance ceiling.
2. **Forgetting vs. Protection:** The bottom chart of Panel B correlates with the top chart's performance gap. As more games are "protected" (knowledge retained), the overall normalized score increases for the regularization methods (`EWC`, `FMN`).
3. **Robustness Hierarchy:** Panel C demonstrates a clear hierarchy in robustness. The `inv. fisher` and `nullspace` methods are highly robust to input perturbations, while the `uniform` method is fragile, failing catastrophically with moderate perturbations.
4. **Task Schedule:** Panel A reveals a non-random, interleaved task schedule, which is a critical experimental detail for interpreting the continual learning results in Panel B.
### Interpretation
This figure collectively argues for the effectiveness of specific continual learning regularization techniques (EWC, FMN) and robustness-promoting methods (inv. fisher, nullspace).
* **Panel A** establishes the experimental setup: a challenging continual learning scenario with 10 distinct tasks (Atari games) interleaved over time.
* **Panel B** provides the core result: without regularization (`no penalty`), the model suffers from catastrophic forgetting, failing to accumulate knowledge across tasks. Methods like EWC and FMN successfully mitigate this, allowing the model to protect previously learned tasks (as shown in the bottom chart) and achieve a high cumulative score, though not reaching the theoretical maximum of a task-specific oracle.
* **Panel C** shifts focus to model robustness, showing that certain methods (`inv. fisher`, `nullspace`) confer stability against input noise or adversarial perturbations, a property distinct from but complementary to continual learning ability.
**Underlying Message:** The research likely aims to develop AI agents that can both learn sequentially without forgetting *and* remain stable in the face of environmental noise. The figure uses Atari games as a benchmark to demonstrate that the proposed methods achieve significant progress on both fronts compared to standard training. The "protected games" metric is a novel way to quantify the prevention of catastrophic forgetting.
DECODING INTELLIGENCE...