TECHNICAL ASSET FINGERPRINT
9620143ada0987d2b3e53018
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: healer-alpha-free VERSION 1
RUNTIME: free/openrouter/healer-alpha
INTEL_VERIFIED
\n
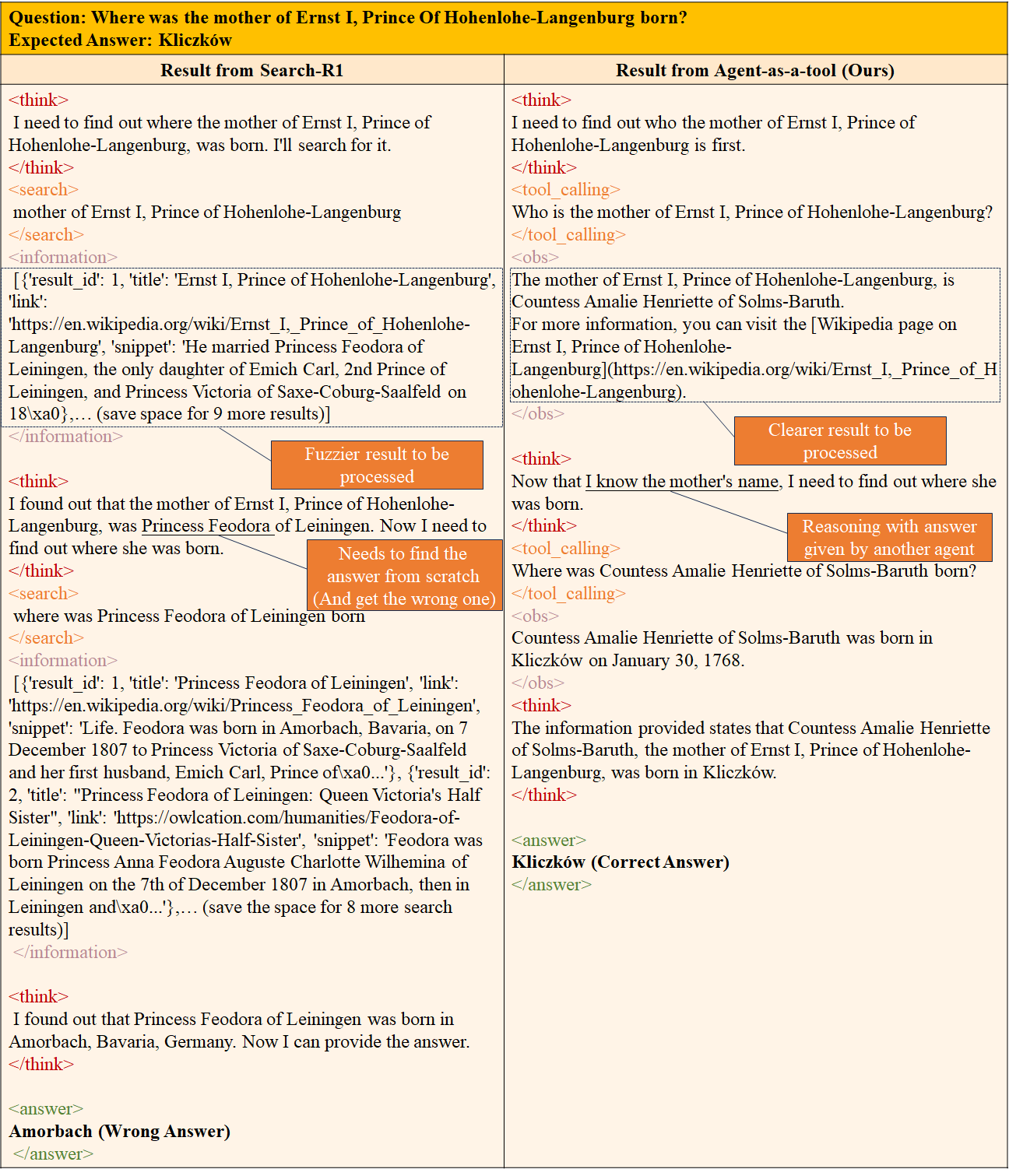
## Diagram: Comparative Analysis of Two AI Agent Workflows for Historical Fact Retrieval
### Overview
The image is a side-by-side comparison diagram illustrating two different AI agent approaches to answering the same factual question: "Where was the mother of Ernst I, Prince Of Hohenlohe-Langenburg born?" The expected correct answer is "Kliczków." The diagram contrasts a flawed process ("Search-R1") with a successful one ("Agent-as-a-tool (Ours)"), using annotated callouts to highlight critical reasoning steps and errors.
### Components/Axes
The diagram is structured as a two-column table with a header row.
* **Header (Yellow Background):**
* **Question:** "Where was the mother of Ernst I, Prince Of Hohenlohe-Langenburg born?"
* **Expected Answer:** "Kliczków"
* **Column 1 (Left):** "Result from Search-R1"
* **Column 2 (Right):** "Result from Agent-as-a-tool (Ours)"
* **Content Structure:** Each column contains a sequence of XML-like tags (`<think>`, `<search>`, `<tool_calling>`, `<information>`, `<obs>`, `<answer>`) representing the agent's internal reasoning, actions, and retrieved data.
* **Annotations (Orange Callout Boxes):** These are overlaid on the diagram to provide meta-commentary on the process. They are connected to specific steps with lines.
* **Left Column Annotations:**
1. "Fuzzier result to be processed" (pointing to the first `<information>` block).
2. "Needs to find the answer from scratch (And get the wrong one)" (pointing to the second `<think>` block).
* **Right Column Annotations:**
1. "Clearer result to be processed" (pointing to the first `<obs>` block).
2. "Reasoning with answer given by another agent" (pointing to the second `<think>` block).
### Detailed Analysis: Content Transcription and Flow
#### **Left Column: "Result from Search-R1" (Flawed Process)**
1. **Initial Thought (`<think>`):** "I need to find out where the mother of Ernst I, Prince of Hohenlohe-Langenburg, was born. I'll search for it."
2. **Action (`<search>`):** Searches for "mother of Ernst I, Prince of Hohenlohe-Langenburg".
3. **Retrieved Data (`<information>`):** Returns a snippet from a Wikipedia page about Ernst I. The snippet states: "'He married Princess Feodora of Leiningen...'" This is an indirect and potentially misleading piece of information, as it mentions his wife, not his mother.
4. **Flawed Reasoning (`<think>`):** "I found out that the mother of Ernst I, Prince of Hohenlohe-Langenburg, was Princess Feodora of Leiningen. Now I need to find out where she was born." **(Error: Misidentifies the mother based on the search snippet.)**
5. **Second Action (`<search>`):** Searches for "where was Princess Feodora of Leiningen born".
6. **Second Retrieved Data (`<information>`):** Returns snippets stating Princess Feodora was born in "Amorbach, Bavaria".
7. **Final Reasoning (`<think>`):** "I found out that Princess Feodora of Leiningen was born in Amorbach, Bavaria, Germany. Now I can provide the answer."
8. **Final Answer (`<answer>`):** "Amorbach (Wrong Answer)"
#### **Right Column: "Result from Agent-as-a-tool (Ours)" (Successful Process)**
1. **Initial Thought (`<think>`):** "I need to find out who the mother of Ernst I, Prince of Hohenlohe-Langenburg is first." **(Key Difference: Focuses on identifying the person first.)**
2. **Action (`<tool_calling>`):** Calls a tool with the query: "Who is the mother of Ernst I, Prince of Hohenlohe-Langenburg?"
3. **Observation (`<obs>`):** "The mother of Ernst I, Prince of Hohenlohe-Langenburg, is Countess Amalie Henriette of Solms-Baruth. For more information, you can visit the [Wikipedia page...](https://en.wikipedia.org/wiki/Ernst_I,_Prince_of_Hohenlohe-Langenburg)." **(Clear, direct identification.)**
4. **Second Reasoning (`<think>`):** "Now that I know the mother's name, I need to find out where she was born."
5. **Second Action (`<tool_calling>`):** Calls a tool with the specific query: "Where was Countess Amalie Henriette of Solms-Baruth born?"
6. **Second Observation (`<obs>`):** "Countess Amalie Henriette of Solms-Baruth was born in Kliczków on January 30, 1768."
7. **Final Reasoning (`<think>`):** "The information provided states that Countess Amalie Henriette of Solms-Baruth, the mother of Ernst I, Prince of Hohenlohe-Langenburg, was born in Kliczków."
8. **Final Answer (`<answer>`):** "Kliczków (Correct Answer)"
### Key Observations
1. **Critical Error Point:** The "Search-R1" agent fails at the first reasoning step by incorrectly inferring the mother's identity from a search result about the son's spouse.
2. **Process Difference:** The successful agent uses a two-stage, decomposed approach: first identify the subject (the mother), then query for the specific attribute (her birthplace). The flawed agent attempts to find the final answer in one step.
3. **Data Quality:** The "Search-R1" agent processes "fuzzier" raw search snippets containing tangential information. The "Agent-as-a-tool" receives "clearer," pre-processed answers from a dedicated tool.
4. **Annotation Purpose:** The orange callouts explicitly label the methodological strengths ("Clearer result," "Reasoning with answer given by another agent") and weaknesses ("Fuzzier result," "Needs to find the answer from scratch") of each approach.
### Interpretation
This diagram serves as a technical case study in AI agent design for factual retrieval. It argues for the superiority of a modular, tool-based architecture over a monolithic search-and-infer approach.
* **The Core Argument:** The "Agent-as-a-tool" model succeeds because it separates concerns. It uses a specialized tool (likely a knowledge graph or structured database) to answer the discrete sub-question "Who is X?" before asking "Where was X born?" This prevents the propagation of initial identification errors.
* **The Failure Mode:** The "Search-R1" model demonstrates a common pitfall in retrieval-augmented generation (RAG): over-reliance on the first plausible snippet from an unstructured web search, leading to a confident but incorrect intermediate conclusion ("Princess Feodora... was the mother"). This error then cascades through the rest of the process.
* **Broader Implication:** The image suggests that for complex or precise factual queries, agents benefit from interacting with structured knowledge sources via defined tools, rather than solely parsing free-form text from general web searches. The successful agent's workflow is more robust, interpretable, and less prone to hallucination or misinterpretation of context.
DECODING INTELLIGENCE...