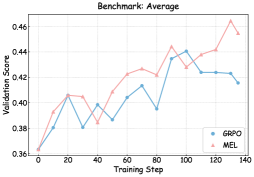
## Line Chart: Benchmark Average
### Overview
The image is a line chart comparing the validation scores of two models, GRPO and MEL, over training steps. The chart shows how the validation score changes as the models are trained.
### Components/Axes
* **Title:** Benchmark: Average
* **X-axis:** Training Step (ranging from 0 to 140 in increments of 20)
* **Y-axis:** Validation Score (ranging from 0.36 to 0.46 in increments of 0.02)
* **Legend:** Located in the bottom-right corner.
* GRPO (blue line with circle markers)
* MEL (pink line with triangle markers)
### Detailed Analysis
* **GRPO (blue line):**
* Starts at approximately 0.36.
* Increases to approximately 0.405 at Training Step 20.
* Decreases to approximately 0.38 at Training Step 30.
* Increases to approximately 0.41 at Training Step 80.
* Peaks at approximately 0.44 at Training Step 100.
* Decreases and plateaus around 0.42 between Training Steps 110 and 130.
* Ends at approximately 0.415 at Training Step 140.
* **MEL (pink line):**
* Starts at approximately 0.36.
* Increases to approximately 0.405 at Training Step 20.
* Decreases slightly to approximately 0.403 at Training Step 30.
* Generally increases to approximately 0.445 at Training Step 100.
* Dips slightly to approximately 0.44 at Training Step 120.
* Peaks at approximately 0.46 at Training Step 130.
* Ends at approximately 0.455 at Training Step 140.
### Key Observations
* Both models start with the same validation score.
* MEL generally outperforms GRPO after Training Step 60.
* MEL reaches a higher peak validation score than GRPO.
* GRPO's validation score plateaus towards the end of the training steps.
### Interpretation
The chart compares the performance of two models, GRPO and MEL, during training. The validation score is used as a metric to evaluate the models' performance. The data suggests that MEL generally performs better than GRPO, especially in the later stages of training. MEL achieves a higher peak validation score, indicating better generalization performance on the validation set. GRPO's performance plateaus, suggesting it may have reached its learning capacity or is overfitting to the training data. The initial similar performance suggests both models may have similar initial learning capabilities, but MEL is better at leveraging the training data to improve its performance over time.