## Violin Plot: High School CS Model Accuracy Comparison
### Overview
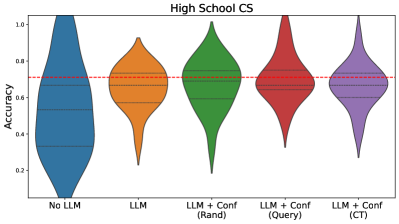
The image presents a comparative analysis of model accuracy distributions across five configurations in a high school computer science context. Five violin plots are arranged horizontally, each representing a different model variant, with a red dashed reference line at 0.7 accuracy.
### Components/Axes
- **X-axis**: Model configurations (categorical)
- "No LLM" (blue)
- "LLM" (orange)
- "LLM + Conf (Rand)" (green)
- "LLM + Conf (Query)" (red)
- "LLM + Conf (CT)" (purple)
- **Y-axis**: Accuracy (continuous scale from 0.0 to 1.0)
- **Legend**: Right-aligned color-coded labels matching x-axis categories
- **Reference Line**: Red dashed horizontal line at y=0.7
### Detailed Analysis
1. **No LLM (Blue)**:
- Distributed between 0.3-0.6 accuracy
- Median ~0.5 (horizontal line within violin)
- Wide distribution indicates high variability
2. **LLM (Orange)**:
- Concentrated around 0.6-0.75
- Median ~0.65
- Narrower distribution than "No LLM"
3. **LLM + Conf (Rand) (Green)**:
- Peaks at 0.7-0.8
- Median ~0.75
- Symmetrical distribution
4. **LLM + Conf (Query) (Red)**:
- Distributed 0.7-0.85
- Median ~0.78
- Slightly skewed toward higher values
5. **LLM + Conf (CT) (Purple)**:
- Peaks at 0.8-0.9
- Median ~0.85
- Most concentrated distribution
### Key Observations
- All "LLM + Conf" variants exceed the 0.7 reference line
- "LLM + Conf (CT)" achieves highest median accuracy (~0.85)
- "No LLM" shows lowest and most variable performance
- Confidence augmentation improves accuracy by 0.15-0.25 compared to base LLM
- "LLM + Conf (Rand)" and "(Query)" show similar performance (~0.75 median)
### Interpretation
The data demonstrates that confidence augmentation consistently improves model accuracy in high school CS applications. The "CT" (likely "Contextual Tuning") method yields the most significant gains, suggesting specialized confidence mechanisms enhance performance. The red reference line at 0.7 appears to represent a performance threshold, with all confidence-augmented models exceeding this benchmark. The progressive improvement from "LLM" to "LLM + Conf (CT)" indicates that confidence augmentation strategies are additive and context-dependent, with CT providing the most substantial benefits. The variability in "No LLM" suggests baseline models struggle with consistency in this domain.