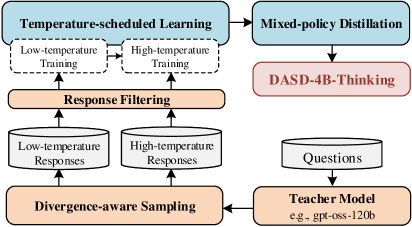
## Flowchart: Temperature-Scheduled Learning and Mixed-Policy Distillation Process
### Overview
The flowchart illustrates a multi-stage process for training and refining language models, combining temperature-scheduled learning, response filtering, and mixed-policy distillation. Key components include low/high-temperature training phases, divergence-aware sampling, and integration with a teacher model (e.g., gpt-oss-120b). The process culminates in DASD-4B-Thinking, a specialized output framework.
### Components/Axes
1. **Main Sections**:
- **Temperature-scheduled Learning** (blue box): Contains two sub-processes:
- Low-temperature Training (dashed arrow)
- High-temperature Training (dashed arrow)
- **Response Filtering** (orange box): Receives outputs from both training phases.
- **Mixed-policy Distillation** (blue box): Integrates filtered responses and connects to DASD-4B-Thinking (red box).
- **Divergence-aware Sampling** (orange box): Feeds into the Teacher Model.
- **Teacher Model** (yellow box): Labeled with example "gpt-oss-120b," processes Questions.
2. **Flow Direction**:
- Arrows indicate sequential progression:
- Training phases → Response Filtering → Mixed-policy Distillation → DASD-4B-Thinking.
- Divergence-aware Sampling → Teacher Model → Questions.
3. **Labels and Text**:
- All textual elements are explicitly labeled (e.g., "Low-temperature Responses," "High-temperature Responses").
- Example model name: "gpt-oss-120b" (Teacher Model).
### Detailed Analysis
- **Temperature-scheduled Learning**:
- Low/high-temperature training phases are visually distinct (dashed arrows) but share the same parent box.
- No numerical values provided; training intensity inferred from temperature metaphor.
- **Response Filtering**:
- Acts as a bottleneck, consolidating outputs from both training phases.
- No explicit criteria for filtering defined in the diagram.
- **Mixed-policy Distillation**:
- Combines filtered responses with DASD-4B-Thinking, suggesting a hybrid optimization approach.
- **Divergence-aware Sampling**:
- Feeds into the Teacher Model, implying iterative refinement of responses.
- **Teacher Model**:
- Explicitly named "gpt-oss-120b," indicating a large-scale pre-trained model.
- Processes Questions, suggesting downstream application in QA systems.
### Key Observations
- **Dual Training Paths**: Low and high-temperature training likely represent exploration (high temp) vs. exploitation (low temp) trade-offs.
- **Integration Points**: Response Filtering and Divergence-aware Sampling serve as critical nodes for combining diverse data streams.
- **Specialized Output**: DASD-4B-Thinking is isolated as a distinct output, possibly denoting a proprietary or optimized reasoning framework.
### Interpretation
The flowchart emphasizes a hybrid training paradigm where temperature modulation balances creativity and precision. Low-temperature training may prioritize accuracy, while high-temperature training encourages diverse outputs. Response Filtering ensures only viable responses proceed, which are then distilled via mixed policies to enhance robustness. The Teacher Model (gpt-oss-120b) acts as a knowledge anchor, refining outputs through divergence-aware sampling. DASD-4B-Thinking likely represents the final optimized reasoning layer, tailored for specific tasks. The absence of quantitative metrics suggests the diagram focuses on architectural design rather than empirical validation.