\n
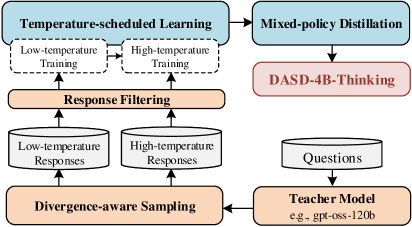
## Diagram: DASD-4B-Thinking Training Pipeline
### Overview
The image depicts a diagram illustrating the training pipeline for DASD-4B-Thinking. It shows a flow of data and processes, starting with temperature-scheduled learning and culminating in the DASD-4B-Thinking model. The diagram is organized into two main vertical columns, with processes flowing from top to bottom and connections between them indicated by arrows.
### Components/Axes
The diagram consists of the following components:
* **Temperature-scheduled Learning:** A blue rectangular block at the top-left.
* **Low-temperature Training:** A dashed-border white block within "Temperature-scheduled Learning".
* **High-temperature Training:** A dashed-border white block within "Temperature-scheduled Learning".
* **Response Filtering:** An orange rectangular block.
* **Low-temperature Responses:** A white cylindrical block.
* **High-temperature Responses:** A white cylindrical block.
* **Divergence-aware Sampling:** An orange rectangular block.
* **Mixed-policy Distillation:** A blue rectangular block at the top-right.
* **DASD-4B-Thinking:** A red rectangular block.
* **Questions:** A white cylindrical block.
* **Teacher Model:** An orange rectangular block with the example "e.g. gpt-oss-120b" listed below.
Arrows indicate the direction of data flow between these components.
### Detailed Analysis or Content Details
The diagram illustrates the following process flow:
1. **Temperature-scheduled Learning** generates outputs from both **Low-temperature Training** and **High-temperature Training**.
2. These outputs are fed into **Response Filtering**.
3. **Response Filtering** produces **Low-temperature Responses** and **High-temperature Responses**.
4. **Low-temperature Responses** and **High-temperature Responses** are fed into **Divergence-aware Sampling**.
5. **Divergence-aware Sampling** feeds into the **Teacher Model**.
6. The **Teacher Model** receives **Questions** as input.
7. The **Teacher Model** feeds into **Mixed-policy Distillation**.
8. **Mixed-policy Distillation** produces **DASD-4B-Thinking**.
The "Teacher Model" block includes the example "e.g. gpt-oss-120b".
### Key Observations
The diagram highlights a two-branch training approach (low and high temperature) that converges through response filtering and divergence-aware sampling before being distilled into the final DASD-4B-Thinking model. The use of a "Teacher Model" suggests a knowledge distillation process. The dashed border around the "Low-temperature Training" and "High-temperature Training" blocks suggests they are sub-processes within the broader "Temperature-scheduled Learning" stage.
### Interpretation
This diagram represents a sophisticated training pipeline for a language model (DASD-4B-Thinking). The use of temperature scheduling suggests an attempt to balance exploration (high temperature) and exploitation (low temperature) during training. Response filtering likely aims to improve the quality and relevance of the generated responses. Divergence-aware sampling may be used to encourage diversity in the generated outputs. The final distillation step, guided by a powerful "Teacher Model" (like gpt-oss-120b), transfers knowledge from the teacher to the student model (DASD-4B-Thinking). The overall architecture suggests a focus on generating high-quality, diverse, and thoughtful responses, as indicated by the "Thinking" component in the model's name. The diagram doesn't provide quantitative data, but it clearly outlines the key stages and relationships within the training process.