## Line Graph: Model Accuracy Comparison Over Training Steps
### Overview
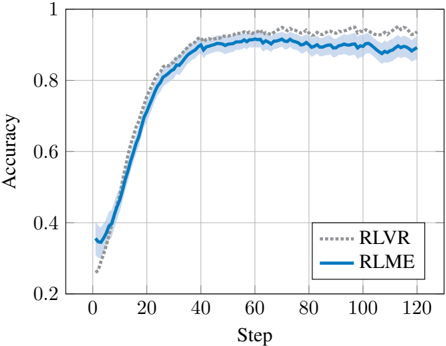
The image depicts a line graph comparing the accuracy of two machine learning models (RLVR and RLME) across 120 training steps. Both models show increasing accuracy over time, with RLME achieving higher final performance. The graph includes confidence intervals (shaded regions) and grid lines for reference.
### Components/Axes
- **X-axis (Step)**: Labeled "Step" with integer markers from 0 to 120 in increments of 20.
- **Y-axis (Accuracy)**: Labeled "Accuracy" with decimal markers from 0.2 to 1.0 in increments of 0.2.
- **Legend**: Located in the bottom-right corner, with:
- **RLVR**: Dotted gray line (dashed pattern)
- **RLME**: Solid blue line
- **Grid**: Light gray horizontal and vertical lines at axis intervals.
### Detailed Analysis
1. **RLME (Solid Blue Line)**:
- Starts at ~0.35 accuracy at step 0.
- Sharp increase to ~0.85 by step 40.
- Plateaus between ~0.88–0.92 from step 60 to 120.
- Confidence interval (shaded blue) narrows significantly after step 40.
2. **RLVR (Dotted Gray Line)**:
- Begins at ~0.3 accuracy at step 0.
- Dips to ~0.25 at step 10, then rises steadily.
- Reaches ~0.85 by step 40, matching RLME's plateau.
- Confidence interval (shaded gray) remains wider than RLME's throughout.
3. **Key Data Points**:
- **RLME**:
- Step 0: 0.35 ± 0.05
- Step 40: 0.85 ± 0.03
- Step 120: 0.90 ± 0.02
- **RLVR**:
- Step 0: 0.30 ± 0.05
- Step 10: 0.25 ± 0.04
- Step 40: 0.85 ± 0.04
- Step 120: 0.90 ± 0.03
### Key Observations
- RLME demonstrates faster convergence (reaching 0.85 accuracy by step 40 vs. RLVR's step 40).
- RLVR exhibits higher initial variability (wider confidence interval at step 0).
- Both models stabilize near 0.9 accuracy by step 120, but RLME maintains tighter confidence bounds.
- RLVR shows a temporary performance dip at step 10, recovering by step 20.
### Interpretation
The graph suggests RLME is more robust and efficient in early training phases, achieving higher accuracy with greater consistency. RLVR's initial dip may indicate sensitivity to hyperparameters or data noise, though it ultimately matches RLME's performance. The narrowing confidence intervals for RLME imply more reliable predictions as training progresses. These results could inform model selection for tasks requiring rapid convergence and stability, while RLVR might be preferable if computational resources allow for longer training to mitigate early instability.