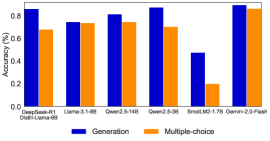
## Bar Chart: Model Accuracy Comparison
### Overview
The image is a bar chart comparing the accuracy of different language models on two tasks: generation and multiple-choice. The chart displays the accuracy percentage for each model on each task, with blue bars representing generation accuracy and orange bars representing multiple-choice accuracy.
### Components/Axes
* **X-axis:** Lists the language models: DeepSeek-R1 Distill-Llama-8B, Uame-3.1-8B, Qwer2.5-14B, Qwer2.5-3B, SmolLM2-1.7B, Gemini-2.0-Flash.
* **Y-axis:** Represents accuracy in percentage, ranging from 0.0 to 0.8.
* **Legend:** Located at the bottom of the chart, indicating that blue bars represent "Generation" accuracy and orange bars represent "Multiple-choice" accuracy.
### Detailed Analysis
Here's a breakdown of the accuracy for each model on both tasks:
* **DeepSeek-R1 Distill-Llama-8B:**
* Generation (Blue): Approximately 0.84
* Multiple-choice (Orange): Approximately 0.68
* **Uame-3.1-8B:**
* Generation (Blue): Approximately 0.75
* Multiple-choice (Orange): Approximately 0.74
* **Qwer2.5-14B:**
* Generation (Blue): Approximately 0.81
* Multiple-choice (Orange): Approximately 0.75
* **Qwer2.5-3B:**
* Generation (Blue): Approximately 0.84
* Multiple-choice (Orange): Approximately 0.70
* **SmolLM2-1.7B:**
* Generation (Blue): Approximately 0.47
* Multiple-choice (Orange): Approximately 0.20
* **Gemini-2.0-Flash:**
* Generation (Blue): Approximately 0.83
* Multiple-choice (Orange): Approximately 0.83
### Key Observations
* Gemini-2.0-Flash has the same accuracy for both Generation and Multiple-choice tasks.
* SmolLM2-1.7B has the lowest accuracy for both tasks compared to the other models.
* For most models, the generation accuracy is higher than the multiple-choice accuracy, except for Uame-3.1-8B and Gemini-2.0-Flash.
### Interpretation
The chart provides a comparative analysis of the performance of different language models on generation and multiple-choice tasks. The data suggests that some models, like DeepSeek-R1 and Qwer2.5-3B, are better suited for generation tasks, while others, like Gemini-2.0-Flash, perform equally well on both tasks. The significant difference in accuracy for SmolLM2-1.7B indicates that it may have limitations compared to the other models. The chart highlights the varying strengths and weaknesses of different language models in different tasks.