\n
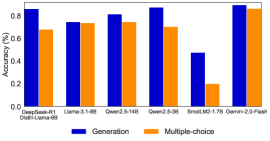
## Bar Chart: Accuracy Comparison of Language Models
### Overview
This bar chart compares the accuracy of several language models on two different tasks: "Generation" and "Multiple-choice". The accuracy is measured as a percentage, ranging from 0 to 1. The chart displays the accuracy for each model and task using adjacent bars.
### Components/Axes
* **X-axis:** Represents the language models being compared. The models listed are: DeepSeek-R1, Llama-3.1-6B, Qwen2.5-14B, Qwen2.5-3B, SmalM2-1.7B, Gemini-2.0-Flash. Below DeepSeek-R1 is the text "Dweil-Llama-8B".
* **Y-axis:** Represents the accuracy, labeled as "Accuracy (%)". The scale ranges from 0.0 to 0.9, with increments of 0.2.
* **Legend:** Located at the bottom-right of the chart.
* **Blue:** Represents "Generation" accuracy.
* **Orange:** Represents "Multiple-choice" accuracy.
### Detailed Analysis
The chart consists of six sets of paired bars, one for each language model.
* **DeepSeek-R1:** Generation accuracy is approximately 0.86. Multiple-choice accuracy is approximately 0.72.
* **Llama-3.1-6B:** Generation accuracy is approximately 0.74. Multiple-choice accuracy is approximately 0.73.
* **Qwen2.5-14B:** Generation accuracy is approximately 0.81. Multiple-choice accuracy is approximately 0.76.
* **Qwen2.5-3B:** Generation accuracy is approximately 0.89. Multiple-choice accuracy is approximately 0.69.
* **SmalM2-1.7B:** Generation accuracy is approximately 0.46. Multiple-choice accuracy is approximately 0.22.
* **Gemini-2.0-Flash:** Generation accuracy is approximately 0.90. Multiple-choice accuracy is approximately 0.82.
The "Generation" bars (blue) generally trend higher than the "Multiple-choice" bars (orange) for most models.
### Key Observations
* Gemini-2.0-Flash exhibits the highest accuracy for both Generation (approximately 0.90) and Multiple-choice (approximately 0.82).
* SmalM2-1.7B shows the lowest accuracy for both tasks, with a Generation accuracy of approximately 0.46 and a Multiple-choice accuracy of approximately 0.22.
* Qwen2.5-3B has a notably high Generation accuracy (approximately 0.89) compared to its Multiple-choice accuracy (approximately 0.69).
* Llama-3.1-6B has nearly identical accuracy for both tasks, around 0.73-0.74.
### Interpretation
The data suggests that the performance of language models varies significantly depending on the task and the specific model architecture. The "Generation" task appears to be generally easier for these models than the "Multiple-choice" task, as evidenced by the consistently higher Generation accuracy scores. Gemini-2.0-Flash stands out as the most accurate model across both tasks, while SmalM2-1.7B lags behind. The difference between Generation and Multiple-choice accuracy for Qwen2.5-3B could indicate a strength in open-ended text creation versus constrained selection. The fact that Dweil-Llama-8B is listed below DeepSeek-R1 suggests a possible relationship or comparison between these two models, potentially indicating Dweil-Llama-8B is a variant or predecessor of DeepSeek-R1. Further investigation would be needed to confirm this.