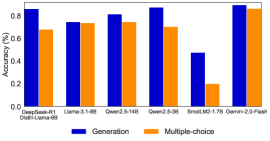
## Grouped Bar Chart: Model Accuracy Comparison (Generation vs. Multiple-choice)
### Overview
The image is a grouped bar chart comparing the accuracy of seven different large language models on two distinct task types: "Generation" and "Multiple-choice". The chart uses blue bars for Generation tasks and orange bars for Multiple-choice tasks. The overall visual trend shows that most models perform better on Generation tasks than on Multiple-choice tasks, with one notable exception.
### Components/Axes
* **Chart Type:** Grouped Bar Chart.
* **Y-Axis:**
* **Label:** `Accuracy (%)`
* **Scale:** Linear, ranging from 0.0 to 1.0 (representing 0% to 100%).
* **Major Ticks:** 0.0, 0.2, 0.4, 0.6, 0.8, 1.0.
* **X-Axis:**
* **Label:** Model names.
* **Categories (from left to right):**
1. `Qwen2.5-72B-Instruct`
2. `Llama-3.1-405B`
3. `Qwen2-72B`
4. `Qwen2.5-32B`
5. `Qwen2.5-7B`
6. `Small-1.7B`
7. `Qwen2-7B-Plain`
* **Legend:**
* **Position:** Centered at the bottom of the chart.
* **Items:**
* Blue Square: `Generation`
* Orange Square: `Multiple-choice`
### Detailed Analysis
Below is the extracted data for each model, with approximate accuracy values read from the chart. The visual trend for each model is noted first.
1. **Qwen2.5-72B-Instruct**
* **Trend:** Generation accuracy is significantly higher than Multiple-choice.
* **Generation (Blue):** ~0.95 (95%)
* **Multiple-choice (Orange):** ~0.80 (80%)
2. **Llama-3.1-405B**
* **Trend:** Generation and Multiple-choice accuracies are very close, with Generation slightly higher.
* **Generation (Blue):** ~0.82 (82%)
* **Multiple-choice (Orange):** ~0.80 (80%)
3. **Qwen2-72B**
* **Trend:** Generation accuracy is higher than Multiple-choice.
* **Generation (Blue):** ~0.88 (88%)
* **Multiple-choice (Orange):** ~0.80 (80%)
4. **Qwen2.5-32B**
* **Trend:** Generation accuracy is notably higher than Multiple-choice.
* **Generation (Blue):** ~0.92 (92%)
* **Multiple-choice (Orange):** ~0.80 (80%)
5. **Qwen2.5-7B**
* **Trend:** Generation accuracy is substantially higher than Multiple-choice.
* **Generation (Blue):** ~0.50 (50%)
* **Multiple-choice (Orange):** ~0.18 (18%)
6. **Small-1.7B**
* **Trend:** Generation accuracy is higher than Multiple-choice.
* **Generation (Blue):** ~0.18 (18%)
* **Multiple-choice (Orange):** ~0.08 (8%)
7. **Qwen2-7B-Plain**
* **Trend:** **This is the only model where Multiple-choice accuracy is higher than Generation.**
* **Generation (Blue):** ~0.78 (78%)
* **Multiple-choice (Orange):** ~0.88 (88%)
### Key Observations
* **Performance Hierarchy:** The `Qwen2.5-72B-Instruct` model achieves the highest Generation accuracy (~95%). The `Qwen2-7B-Plain` model achieves the highest Multiple-choice accuracy (~88%).
* **Consistent Multiple-choice Baseline:** Five of the seven models (the first four and the last one) cluster around an 80% accuracy for Multiple-choice tasks, suggesting a common performance ceiling or benchmark for this task type among these models.
* **Significant Performance Drop:** There is a dramatic drop in accuracy for both task types for the `Qwen2.5-7B` and `Small-1.7B` models, indicating a strong correlation between model size/capability and performance on these benchmarks.
* **Notable Anomaly:** `Qwen2-7B-Plain` is the sole outlier where the Multiple-choice score (~88%) exceeds the Generation score (~78%). This contrasts with the pattern seen in all other models.
### Interpretation
This chart provides a comparative snapshot of model capabilities across two fundamental NLP task paradigms: open-ended generation and constrained multiple-choice selection.
* **Task Difficulty Implication:** The general trend of higher Generation scores suggests that, for these specific models and benchmarks, the evaluated Generation tasks may be less challenging or better aligned with the models' pre-training than the Multiple-choice tasks. The consistent ~80% Multiple-choice score for larger models might indicate a specific type of reasoning or knowledge retrieval that is equally challenging for them.
* **Model Specialization:** The anomaly of `Qwen2-7B-Plain` performing better on Multiple-choice could imply a difference in its training data, fine-tuning procedure, or architecture that favors discriminative tasks over generative ones. The "-Plain" suffix might denote a base model without instruction tuning, which could explain this reversal.
* **Scale Matters:** The steep decline in performance for the 7B and 1.7B models underscores the importance of model scale for achieving high accuracy on these benchmarks. The performance gap between `Qwen2.5-7B` and `Qwen2.5-32B` is particularly stark.
* **Benchmark Insight:** The chart likely represents results from a specific evaluation suite. The data suggests that "Generation" and "Multiple-choice" are not monolithic categories; their relative difficulty is model-dependent. A model's strength in one does not perfectly predict its strength in the other, as evidenced by the `Qwen2-7B-Plain` case.