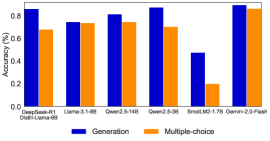
## Bar Chart: Model Accuracy Comparison (Generation vs Multiple-choice)
### Overview
The chart compares the accuracy performance of two methods ("Generation" and "Multiple-choice") across seven AI models. Accuracy is measured in percentage, with values ranging from 0% to 80% on the y-axis. The x-axis lists model names, and the legend distinguishes the two methods by color (blue for Generation, orange for Multiple-choice).
### Components/Axes
- **X-axis (Models)**:
- DeepSeek-R1
- Llama-3-1-8B
- Qwen2-5-14B
- Qwen2-5-3B
- SmolLM2-1.7B
- Gemini-2.0-Flash
- DistilLlama-8B
- **Y-axis (Accuracy %)**:
- Scale: 0.0 to 0.8 in increments of 0.2
- Labels: "Accuracy (%)"
- **Legend**:
- Position: Bottom center
- Colors:
- Blue = Generation
- Orange = Multiple-choice
### Detailed Analysis
1. **DeepSeek-R1**:
- Generation: ~85% (blue bar)
- Multiple-choice: ~68% (orange bar)
2. **Llama-3-1-8B**:
- Generation: ~75% (blue bar)
- Multiple-choice: ~74% (orange bar)
3. **Qwen2-5-14B**:
- Generation: ~81% (blue bar)
- Multiple-choice: ~76% (orange bar)
4. **Qwen2-5-3B**:
- Generation: ~87% (blue bar)
- Multiple-choice: ~71% (orange bar)
5. **SmolLM2-1.7B**:
- Generation: ~47% (blue bar)
- Multiple-choice: ~20% (orange bar)
6. **Gemini-2.0-Flash**:
- Generation: ~90% (blue bar)
- Multiple-choice: ~86% (orange bar)
7. **DistilLlama-8B**:
- Generation: ~78% (blue bar)
- Multiple-choice: ~72% (orange bar)
### Key Observations
- **Consistent Outperformance**: Generation methods consistently outperform Multiple-choice across all models, with accuracy gaps ranging from 5% (Llama-3-1-8B) to 30% (SmolLM2-1.7B).
- **SmolLM2-1.7B Anomaly**: This model shows the largest disparity between methods (27% gap), with Generation at 47% and Multiple-choice at 20%.
- **Gemini-2.0-Flash Exception**: Despite being the highest-performing model overall, its Multiple-choice accuracy (86%) is nearly equal to its Generation accuracy (90%), suggesting near-parity in this case.
- **Low Baseline**: SmolLM2-1.7B has the lowest accuracy for both methods, indicating potential limitations in model size or training data.
### Interpretation
The data demonstrates that **Generation methods significantly outperform Multiple-choice approaches** in most models, particularly in larger architectures like Gemini-2.0-Flash and Qwen2-5-3B. The exception with Gemini-2.0-Flash suggests that for highly capable models, Multiple-choice may approach Generation performance. However, SmolLM2-1.7B's poor performance across both methods highlights challenges in smaller models. This trend implies that Generation methods may be more robust or adaptable to diverse tasks, while Multiple-choice approaches might struggle with complex reasoning or domain-specific knowledge. The near-parity in Gemini-2.0-Flash warrants further investigation into whether Multiple-choice could be optimized for specific use cases in high-capacity models.