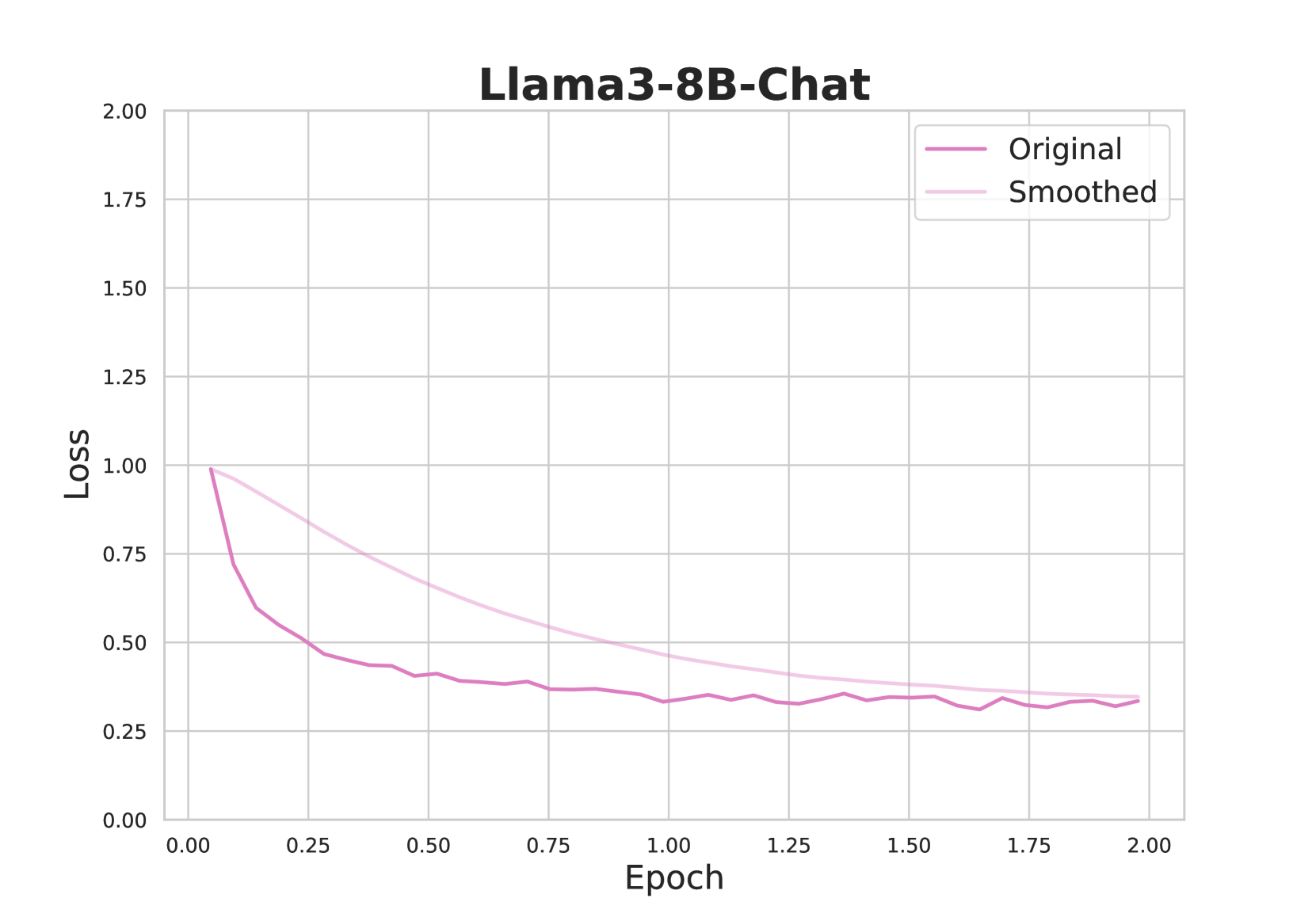
## Line Chart: Llama3-8B-Chat Loss Over Epochs
### Overview
The chart visualizes the training loss of the Llama3-8B-Chat model across 2.00 epochs. Two lines are plotted: "Original" (dark purple) and "Smoothed" (light pink), showing loss values on the y-axis against epoch progression on the x-axis. Both lines exhibit a general downward trend, with the Smoothed line consistently maintaining lower loss values than the Original line after the initial drop.
### Components/Axes
- **Title**: "Llama3-8B-Chat" (top-center, bold black text).
- **Legend**: Located in the top-right corner, with:
- "Original" (dark purple line).
- "Smoothed" (light pink line).
- **X-axis (Epoch)**:
- Label: "Epoch" (bottom-center, black text).
- Scale: 0.00 to 2.00 in increments of 0.25.
- **Y-axis (Loss)**:
- Label: "Loss" (left-center, black text).
- Scale: 0.00 to 2.00 in increments of 0.25.
### Detailed Analysis
1. **Original Line**:
- Starts at **1.00 loss** at epoch 0.00.
- Drops sharply to **~0.30 loss** by epoch 0.50.
- Exhibits minor fluctuations (~0.30–0.40) between epochs 0.50–2.00.
- Final loss value: **~0.30** at epoch 2.00.
2. **Smoothed Line**:
- Starts at **~0.95 loss** at epoch 0.00.
- Declines steadily to **~0.35 loss** by epoch 2.00.
- Maintains a smoother trajectory with no sharp drops or spikes.
- Final loss value: **~0.35** at epoch 2.00.
### Key Observations
- The Smoothed line consistently outperforms the Original line in terms of lower loss after the initial epoch.
- Both lines converge toward similar loss values (~0.30–0.35) by epoch 2.00, suggesting stabilization.
- The Original line shows higher variance in early epochs (e.g., sharp drop from 1.00 to 0.30 between epochs 0.00–0.50), while the Smoothed line exhibits a more gradual decline.
### Interpretation
The chart demonstrates the effectiveness of smoothing techniques in reducing loss volatility during model training. The Original line’s initial sharp drop may reflect rapid learning, but subsequent fluctuations suggest instability or overfitting. The Smoothed line’s consistent performance indicates that smoothing mitigates noise, leading to more reliable training. The convergence of both lines by epoch 2.00 implies that the model reaches a stable state, with smoothing providing a more robust path to convergence. This aligns with common practices in machine learning, where smoothing (e.g., gradient clipping or moving averages) is used to improve training stability.