TECHNICAL ASSET FINGERPRINT
97e2e311845b721e0c733421
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: gemini-2.5-flash-lite-free VERSION 1
RUNTIME: google-free/gemini-2.5-flash-lite
INTEL_VERIFIED
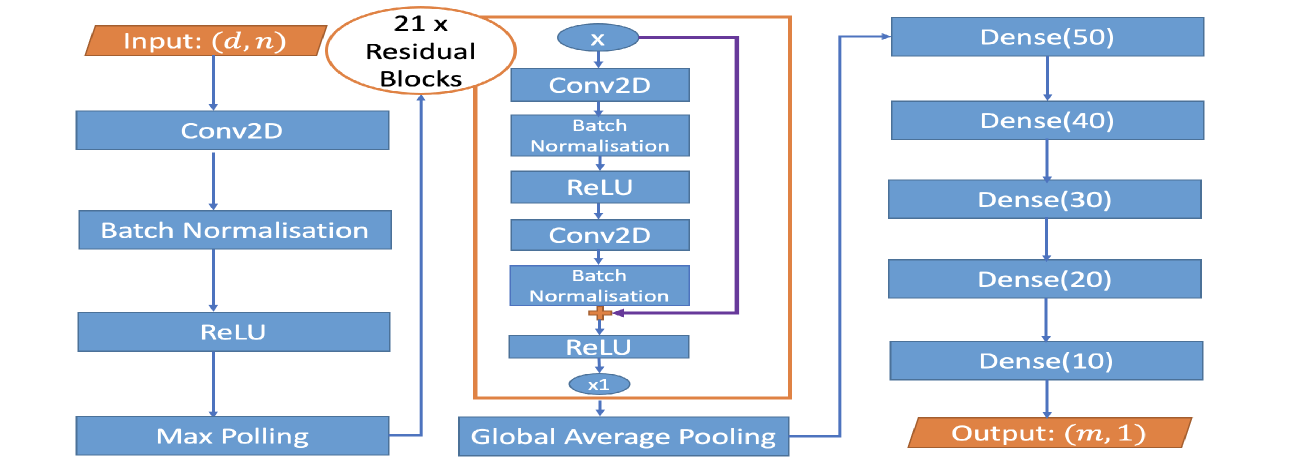
## Diagram: Neural Network Architecture
### Overview
This diagram illustrates a neural network architecture. It begins with an input layer, followed by convolutional layers, batch normalization, ReLU activation, and max pooling. A significant portion of the network consists of 21 residual blocks, which are themselves composed of convolutional layers, batch normalization, and ReLU activations, with a skip connection. After the residual blocks, a global average pooling layer is applied, leading to a series of dense (fully connected) layers, culminating in an output layer.
### Components/Axes
The diagram is a flowchart-style representation of a neural network. There are no explicit axes or legends in the traditional sense of a chart. The components are represented by rectangular boxes for layers and operations, and an oval for a repeated block structure. Arrows indicate the flow of data through the network.
**Input/Output:**
* **Input:** Indicated by an orange trapezoidal shape labeled "Input: (d, n)". This signifies the input data has dimensions 'd' and 'n'.
* **Output:** Indicated by an orange trapezoidal shape labeled "Output: (m, 1)". This signifies the output data has dimensions 'm' and '1'.
**Layers and Operations (Blue Rectangles):**
* **Conv2D:** Convolutional layer (appears multiple times).
* **Batch Normalisation:** Batch Normalization layer (appears multiple times).
* **ReLU:** Rectified Linear Unit activation function (appears multiple times).
* **Max Polling:** Max Pooling layer.
* **Dense(50):** Fully connected layer with 50 neurons.
* **Dense(40):** Fully connected layer with 40 neurons.
* **Dense(30):** Fully connected layer with 30 neurons.
* **Dense(20):** Fully connected layer with 20 neurons.
* **Dense(10):** Fully connected layer with 10 neurons.
**Special Components:**
* **21 x Residual Blocks:** An orange oval enclosing a repeated structure, indicating that this block is instantiated 21 times.
* **x:** An oval representing a variable or intermediate output, used as input to the residual block.
* **x1:** An oval indicating a single instance or output of the residual block structure.
* **Global Average Pooling:** A rectangular box representing the global average pooling operation.
**Connections:**
* Arrows indicate the sequential flow of data.
* A purple arrow forms a skip connection within the residual block, bypassing some layers and adding its output to a later stage.
* A '+' symbol within the residual block indicates the addition operation for the skip connection.
### Detailed Analysis or Content Details
The network processing can be broken down as follows:
1. **Initial Feature Extraction:**
* Input data with dimensions `(d, n)` is fed into a `Conv2D` layer.
* The output of `Conv2D` is processed by `Batch Normalisation`.
* The normalized output is passed through a `ReLU` activation function.
* This is followed by a `Max Polling` operation.
2. **Residual Blocks:**
* The output from the initial feature extraction (or the output of the previous residual block) is fed into a structure labeled "21 x Residual Blocks".
* **Inside a single Residual Block:**
* An input `x` is received.
* It passes through a `Conv2D` layer.
* Followed by `Batch Normalisation`.
* Then a `ReLU` activation.
* Another `Conv2D` layer.
* Followed by `Batch Normalisation`.
* A `ReLU` activation.
* Crucially, a skip connection (purple arrow) bypasses the first `Conv2D`, `Batch Normalisation`, and `ReLU` layers. The output of the first `Batch Normalisation` layer is added (indicated by '+') to the output of the second `Batch Normalisation` layer.
* The result of this addition is then passed through a `ReLU` activation.
* This entire block is repeated 21 times. The output of the final residual block is labeled `x1`.
3. **Downsampling and Feature Aggregation:**
* The output `x1` from the residual blocks is fed into a `Global Average Pooling` layer.
4. **Classification/Regression Head:**
* The output of `Global Average Pooling` is then passed through a series of fully connected (Dense) layers:
* `Dense(50)`
* `Dense(40)`
* `Dense(30)`
* `Dense(20)`
* `Dense(10)`
* The final layer produces an output with dimensions `(m, 1)`.
### Key Observations
* The architecture heavily relies on residual connections, a common technique in deep learning to facilitate the training of very deep networks by mitigating the vanishing gradient problem.
* The network employs a combination of convolutional layers for feature extraction and dense layers for final prediction or classification.
* The presence of 21 residual blocks suggests a deep network designed to learn complex hierarchical features.
* Batch Normalization and ReLU activations are used throughout the network, which are standard practices for improving training stability and performance.
* Global Average Pooling is used before the dense layers, which can help reduce the number of parameters and prevent overfitting compared to traditional fully connected layers after convolutional layers.
### Interpretation
This diagram depicts a deep convolutional neural network architecture, likely designed for a task such as image classification or regression. The initial convolutional layers extract low-level features, which are then processed and refined through a substantial stack of 21 residual blocks. The residual connections are a key design choice, enabling the network to learn identity mappings and thus making it easier to train very deep models. The repeated application of `Conv2D`, `Batch Normalisation`, and `ReLU` within each residual block allows for the learning of increasingly complex and abstract features. The `Global Average Pooling` layer effectively summarizes the spatial feature maps into a fixed-size vector, reducing dimensionality and making the network more robust to spatial variations. Finally, the series of `Dense` layers acts as a classifier or regressor, mapping the learned features to the desired output dimensions `(m, 1)`. The specific number of neurons in the dense layers (50, 40, 30, 20, 10) suggests a multi-class classification problem or a regression task with multiple output values, where the final layer with 10 neurons might represent classes or specific output features. The input dimensions `(d, n)` and output dimensions `(m, 1)` are generic placeholders, indicating that the network is adaptable to different input data shapes and output requirements.
DECODING INTELLIGENCE...