## Table: Language Model Uncertainty Estimation Failure Example
### Overview
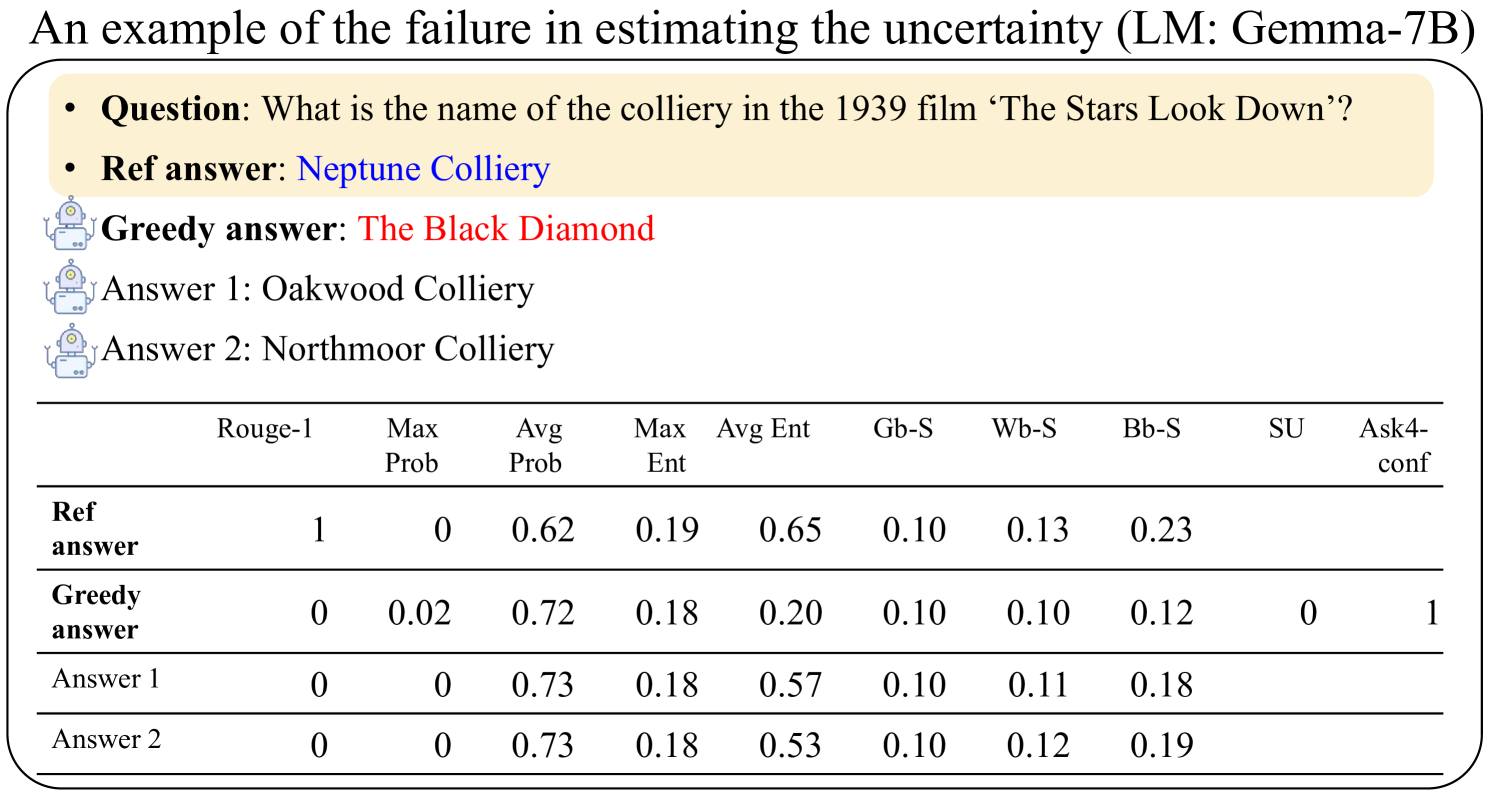
The image presents a table that exemplifies a failure case in estimating uncertainty using the Gemma-7B language model. It shows the model's responses to a question about a film, comparing a reference answer with a greedy answer and two other generated answers. The table provides various metrics for each answer, including Rouge-1 score, maximum probability, average probability, maximum entropy, average entropy, and other scores (Gb-S, Wb-S, Bb-S, SU, Ask4-conf).
### Components/Axes
* **Title:** An example of the failure in estimating the uncertainty (LM: Gemma-7B)
* **Question:** What is the name of the colliery in the 1939 film 'The Stars Look Down'?
* **Answers:**
* Ref answer: Neptune Colliery
* Greedy answer: The Black Diamond
* Answer 1: Oakwood Colliery
* Answer 2: Northmoor Colliery
* **Table Headers (Columns):**
* Rouge-1
* Max Prob
* Avg Prob
* Max Ent
* Avg Ent
* Gb-S
* Wb-S
* Bb-S
* SU
* Ask4-conf
* **Table Rows:**
* Ref answer
* Greedy answer
* Answer 1
* Answer 2
### Detailed Analysis or ### Content Details
The table presents the following data:
| | Rouge-1 | Max Prob | Avg Prob | Max Ent | Avg Ent | Gb-S | Wb-S | Bb-S | SU | Ask4-conf |
| :-------------------- | :------ | :------- | :------- | :------ | :------ | :---- | :---- | :---- | :---- | :-------- |
| **Ref answer** | 1 | 0 | 0.62 | 0.19 | 0.65 | 0.10 | 0.13 | 0.23 | N/A | N/A |
| **Greedy answer** | 0 | 0.02 | 0.72 | 0.18 | 0.20 | 0.10 | 0.10 | 0.12 | 0 | 1 |
| **Answer 1** | 0 | 0 | 0.73 | 0.18 | 0.57 | 0.10 | 0.11 | 0.18 | N/A | N/A |
| **Answer 2** | 0 | 0 | 0.73 | 0.18 | 0.53 | 0.10 | 0.12 | 0.19 | N/A | N/A |
* **Ref answer:**
* Rouge-1: 1
* Max Prob: 0
* Avg Prob: 0.62
* Max Ent: 0.19
* Avg Ent: 0.65
* Gb-S: 0.10
* Wb-S: 0.13
* Bb-S: 0.23
* **Greedy answer:**
* Rouge-1: 0
* Max Prob: 0.02
* Avg Prob: 0.72
* Max Ent: 0.18
* Avg Ent: 0.20
* Gb-S: 0.10
* Wb-S: 0.10
* Bb-S: 0.12
* SU: 0
* Ask4-conf: 1
* **Answer 1:**
* Rouge-1: 0
* Max Prob: 0
* Avg Prob: 0.73
* Max Ent: 0.18
* Avg Ent: 0.57
* Gb-S: 0.10
* Wb-S: 0.11
* Bb-S: 0.18
* **Answer 2:**
* Rouge-1: 0
* Max Prob: 0
* Avg Prob: 0.73
* Max Ent: 0.18
* Avg Ent: 0.53
* Gb-S: 0.10
* Wb-S: 0.12
* Bb-S: 0.19
### Key Observations
* The "Ref answer" has a Rouge-1 score of 1, indicating it's the correct answer.
* The "Greedy answer" has a higher average probability (0.72) than the "Ref answer" (0.62), yet it's incorrect (Rouge-1 score of 0).
* "Answer 1" and "Answer 2" have the highest average probability (0.73), but are also incorrect.
* The maximum entropy is relatively consistent across all answers.
* Gb-S is the same for all answers.
### Interpretation
The data suggests that the Gemma-7B language model, in this specific instance, fails to accurately estimate uncertainty. Despite the "Greedy answer," "Answer 1," and "Answer 2" having higher average probabilities than the correct "Ref answer," they are incorrect. This highlights a potential issue where the model's confidence (as reflected by average probability) doesn't align with the actual correctness of the answer. The model is more "certain" about the wrong answers. The consistent Gb-S score across all answers suggests this metric might not be useful in distinguishing correct from incorrect answers in this scenario. The Ask4-conf score is only present for the Greedy answer, and its meaning is not clear from the context.