\n
## Data Table: Uncertainty Estimation Failure Analysis
### Overview
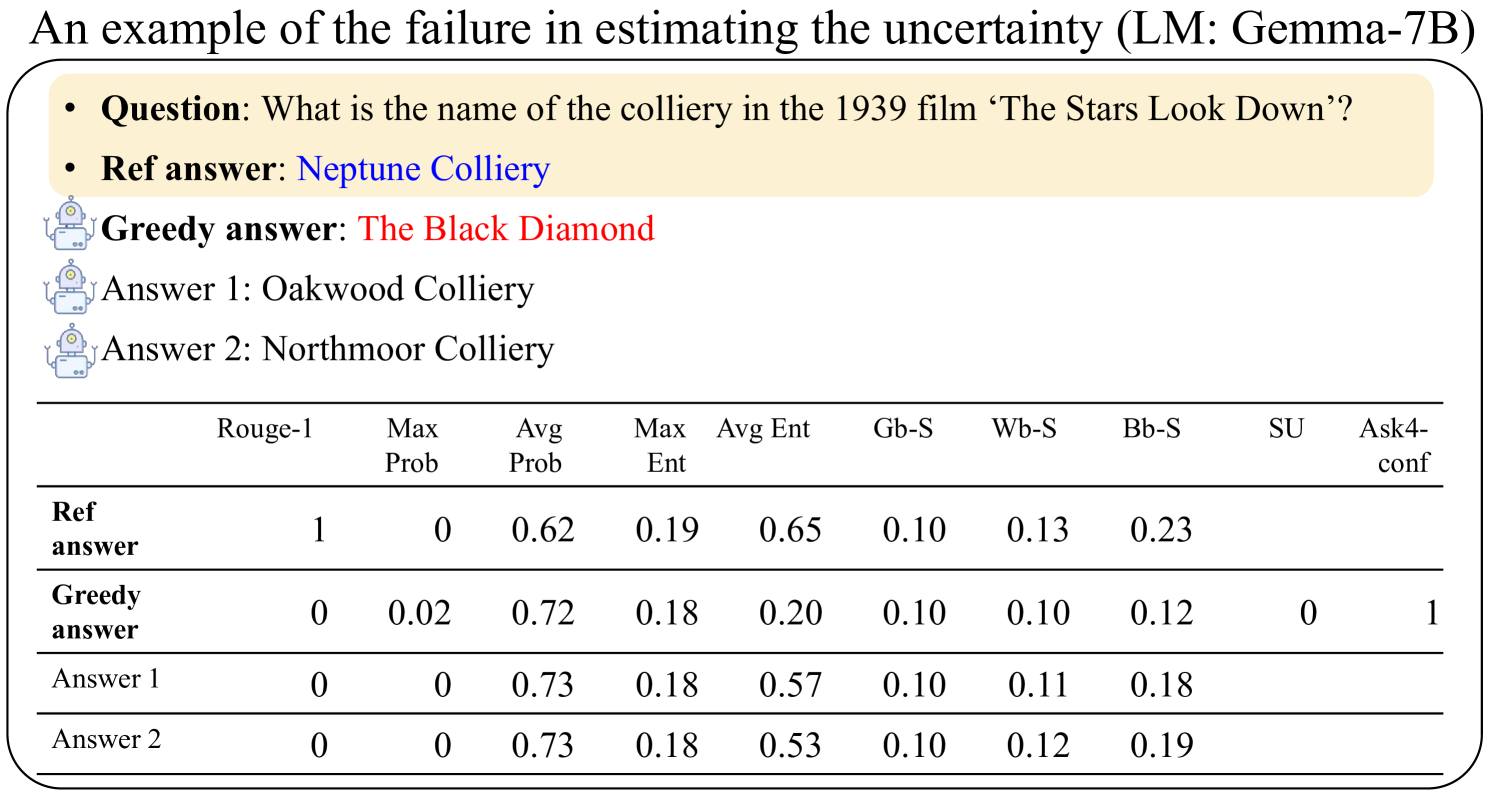
This image presents a data table comparing the performance of different answer generation models (Greedy, Answer 1, Answer 2) against a reference answer for a specific question. The table quantifies performance using several metrics related to text similarity and uncertainty estimation. The question being addressed is: "What is the name of the colliery in the 1939 film ‘The Stars Look Down’?".
### Components/Axes
The image contains the following components:
* **Title:** "An example of the failure in estimating the uncertainty (LM: Gemma-7B)" - positioned at the top-left.
* **Question:** "Question: What is the name of the colliery in the 1939 film ‘The Stars Look Down’?" - positioned below the title.
* **Answers:**
* "Ref answer: Neptune Colliery" - highlighted in yellow.
* "Greedy answer: The Black Diamond" - highlighted in red.
* "Answer 1: Oakwood Colliery" - associated with a robot icon.
* "Answer 2: Northmoor Colliery" - associated with a robot icon.
* **Data Table:** A table with rows representing each answer (Ref answer, Greedy answer, Answer 1, Answer 2) and columns representing different evaluation metrics.
* **Column Headers:** "Rouge-1", "Max Prob", "Avg Prob", "Max Ent", "Avg Ent", "Gb-S", "Wb-S", "Bb-S", "SU", "Ask4-conf".
### Detailed Analysis or Content Details
The data table contains the following values:
| Answer | Rouge-1 | Max Prob | Avg Prob | Max Ent | Avg Ent | Gb-S | Wb-S | Bb-S | SU | Ask4-conf |
|-----------------|---------|----------|----------|---------|---------|-------|-------|-------|-------|-----------|
| Ref answer | 1 | 0 | 0.62 | 0.19 | 0.65 | 0.10 | 0.13 | 0.23 | | |
| Greedy answer | 0 | 0.02 | 0.72 | 0.18 | 0.20 | 0.10 | 0.10 | 0.12 | 0 | 1 |
| Answer 1 | 0 | 0 | 0.73 | 0.18 | 0.57 | 0.10 | 0.11 | 0.18 | | |
| Answer 2 | 0 | 0 | 0.73 | 0.18 | 0.53 | 0.10 | 0.12 | 0.19 | | |
**Trends:**
* **Rouge-1:** The reference answer has a Rouge-1 score of 1, while all other answers have a score of 0.
* **Max Prob:** The Greedy answer has a Max Prob of 0.02, while all other answers have a Max Prob of 0.
* **Avg Prob:** All answers (Ref, Greedy, Answer 1, Answer 2) have similar Avg Prob values, ranging from 0.62 to 0.73.
* **Max Ent:** All answers have a Max Ent value of 0.18 or 0.19.
* **Avg Ent:** The Ref answer has an Avg Ent of 0.65, while the other answers have lower values (0.20, 0.57, 0.53).
* **Gb-S, Wb-S, Bb-S:** These metrics are consistently 0.10, 0.11-0.13, and 0.12-0.23 respectively across all answers.
* **SU:** The Greedy answer has an SU value of 0, while the Ask4-conf is 1.
* **Ask4-conf:** Only the Greedy answer has a value for Ask4-conf, which is 1.
### Key Observations
* The "Greedy answer" has a non-zero "Max Prob" (0.02) and "Ask4-conf" (1), suggesting some level of confidence in its incorrect answer.
* The "Ref answer" has the highest "Rouge-1" and "Avg Ent" scores, indicating a strong match to the expected answer and higher uncertainty.
* The "Avg Prob" is relatively high for all answers, even the incorrect ones, suggesting the model assigns similar probabilities to different answers.
* The "SU" metric is only populated for the "Greedy answer" and is 0.
### Interpretation
The data suggests that the language model (Gemma-7B) struggles to accurately estimate the uncertainty associated with its answers. Despite providing an incorrect answer ("The Black Diamond"), the "Greedy answer" exhibits a relatively high probability and confidence score ("Ask4-conf" = 1). This indicates a failure in the model's ability to recognize its own limitations and express appropriate uncertainty. The high "Avg Prob" values across all answers suggest the model is overconfident in its predictions, even when they are incorrect. The "Rouge-1" metric clearly differentiates the correct answer ("Neptune Colliery") from the others, but the other metrics do not provide a clear signal of the answer's correctness. This example highlights the challenges in developing language models that can not only generate answers but also accurately assess their own reliability.