## Technical Document Example: Language Model Uncertainty Estimation Failure
### Overview
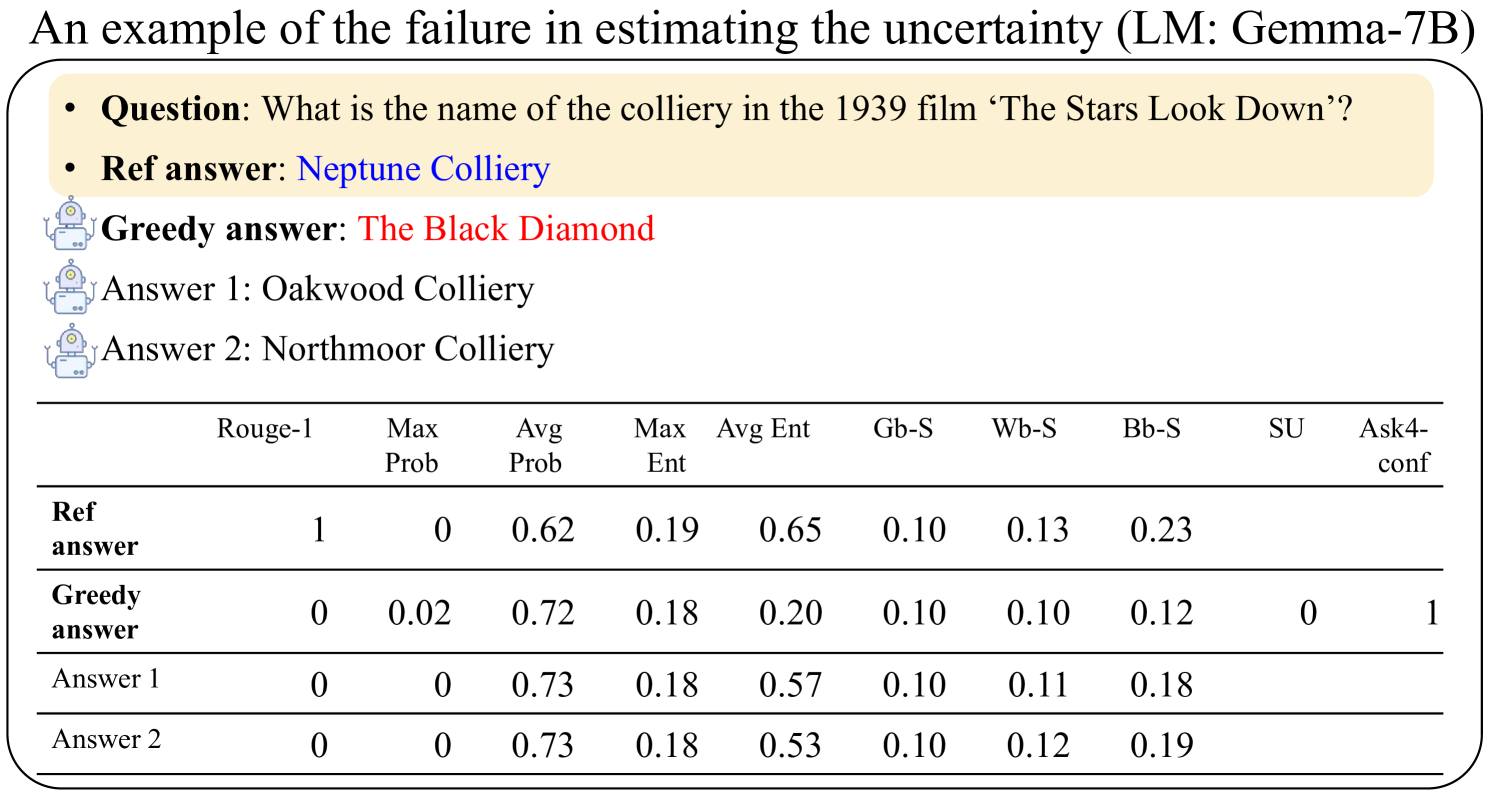
The image is a technical slide or figure titled "An example of the failure in estimating the uncertainty (LM: Gemma-7B)". It presents a specific question posed to a language model (Gemma-7B), the reference answer, the model's greedy (most likely) answer, and two alternative sampled answers. Below this, a table provides various quantitative metrics for each of these four answer candidates. The purpose is to illustrate a case where the model's internal uncertainty metrics do not align with the factual correctness of its outputs.
### Components/Axes
The image is structured in two main sections:
1. **Header/Question Section (Top, within a beige rounded rectangle):**
* **Question:** "What is the name of the colliery in the 1939 film ‘The Stars Look Down’?"
* **Ref answer:** "Neptune Colliery" (displayed in blue text).
* **Greedy answer:** "The Black Diamond" (displayed in red text, preceded by a small robot icon).
* **Answer 1:** "Oakwood Colliery" (preceded by a small robot icon).
* **Answer 2:** "Northmoor Colliery" (preceded by a small robot icon).
2. **Data Table (Bottom):**
* **Rows:** Correspond to the four answer candidates: "Ref answer", "Greedy answer", "Answer 1", "Answer 2".
* **Columns (Metrics):** The table has 10 columns with the following headers:
* `Rouge-1`
* `Max Prob`
* `Avg Prob`
* `Max Ent`
* `Avg Ent`
* `Gb-S`
* `Wb-S`
* `Bb-S`
* `SU`
* `Ask4-conf`
### Detailed Analysis
The table contains the following numerical data for each answer candidate:
| Answer Candidate | Rouge-1 | Max Prob | Avg Prob | Max Ent | Avg Ent | Gb-S | Wb-S | Bb-S | SU | Ask4-conf |
| :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- |
| **Ref answer** | 1 | 0 | 0.62 | 0.19 | 0.65 | 0.10 | 0.13 | 0.23 | | |
| **Greedy answer** | 0 | 0.02 | 0.72 | 0.18 | 0.20 | 0.10 | 0.10 | 0.12 | 0 | 1 |
| **Answer 1** | 0 | 0 | 0.73 | 0.18 | 0.57 | 0.10 | 0.11 | 0.18 | | |
| **Answer 2** | 0 | 0 | 0.73 | 0.18 | 0.53 | 0.10 | 0.12 | 0.19 | | |
**Note:** The cells for `SU` and `Ask4-conf` are empty for the "Ref answer", "Answer 1", and "Answer 2" rows.
### Key Observations
1. **Correctness vs. Model Confidence:** The reference answer ("Neptune Colliery") is correct (Rouge-1 = 1). The model's greedy answer ("The Black Diamond") is incorrect (Rouge-1 = 0).
2. **Probability Metrics:** The incorrect greedy answer has a higher `Avg Prob` (0.72) than the correct reference answer (0.62). The two other incorrect sampled answers ("Answer 1" and "Answer 2") have the highest `Avg Prob` (0.73).
3. **Entropy Metrics:** The correct reference answer has the highest `Avg Ent` (0.65), indicating higher model uncertainty for the correct token sequence. The incorrect greedy answer has a much lower `Avg Ent` (0.20), suggesting the model is more certain about its incorrect output.
4. **Special Metrics:** Only the greedy answer has values for `SU` (0) and `Ask4-conf` (1). The `Ask4-conf` value of 1 suggests the model would express high confidence if asked about this answer.
5. **Similarity Scores (Gb-S, Wb-S, Bb-S):** These scores are relatively low and similar across all answers, with the reference answer having slightly higher values in `Wb-S` and `Bb-S`.
### Interpretation
This example demonstrates a critical failure mode in language model uncertainty estimation. The model (Gemma-7B) exhibits **overconfidence in an incorrect answer**.
* **The Core Problem:** The model assigns higher average probability (`Avg Prob`) and lower average entropy (`Avg Ent`) to its incorrect greedy answer compared to the correct reference answer. This is the opposite of the desired behavior, where correct answers should be associated with higher model confidence (higher probability, lower entropy).
* **Implication for Reliability:** This misalignment means that using the model's own probability or entropy scores as a proxy for answer correctness or uncertainty is unreliable in this case. A user or system relying on these metrics would be misled into trusting the wrong answer.
* **Broader Significance:** The slide highlights a key challenge in AI safety and reliability: ensuring that a model's internal confidence signals are well-calibrated with factual accuracy. When models are confidently wrong, it becomes difficult to build systems that can automatically flag uncertain or potentially incorrect outputs for human review. This failure underscores the need for better uncertainty quantification methods that are robust to such cases.