TECHNICAL ASSET FINGERPRINT
985b63992da1162f1add441a
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: gemini-2.0-flash VERSION 1
RUNTIME: nugit/gemini/gemini-2.0-flash
INTEL_VERIFIED
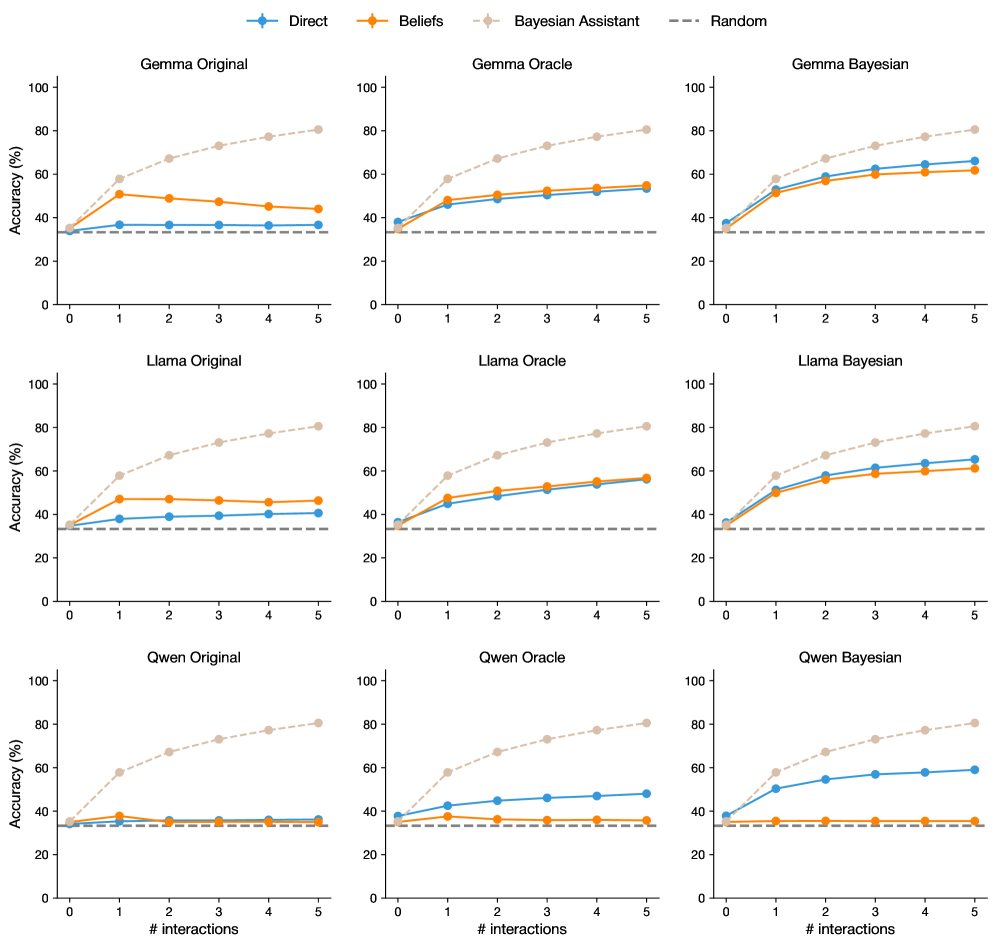
## Line Charts: Accuracy vs. Interactions for Different Models
### Overview
The image presents a series of line charts comparing the accuracy of different language models (Gemma, Llama, Qwen) under various interaction strategies (Direct, Beliefs, Bayesian Assistant, Random). Each row represents a different language model, while each column represents a different interaction strategy. The x-axis represents the number of interactions, and the y-axis represents the accuracy in percentage.
### Components/Axes
* **Title:** Accuracy vs. Interactions for Different Models
* **X-axis:** "# interactions" with markers at 0, 1, 2, 3, 4, and 5.
* **Y-axis:** "Accuracy (%)" with markers at 0, 20, 40, 60, 80, and 100.
* **Legend:** Located at the top of the image.
* **Direct:** Blue line with circular markers.
* **Beliefs:** Orange line with circular markers.
* **Bayesian Assistant:** Light brown dashed line with circular markers.
* **Random:** Gray dashed line.
* **Chart Titles (Top Row):**
* Gemma Original (Top-Left)
* Gemma Oracle (Top-Center)
* Gemma Bayesian (Top-Right)
* **Chart Titles (Middle Row):**
* Llama Original (Middle-Left)
* Llama Oracle (Middle-Center)
* Llama Bayesian (Middle-Right)
* **Chart Titles (Bottom Row):**
* Qwen Original (Bottom-Left)
* Qwen Oracle (Bottom-Center)
* Qwen Bayesian (Bottom-Right)
### Detailed Analysis
**Gemma Models:**
* **Gemma Original:**
* Direct (Blue): Starts at approximately 35% and decreases slightly to around 33% at 5 interactions.
* Beliefs (Orange): Starts at approximately 45% and decreases slightly to around 42% at 5 interactions.
* Bayesian Assistant (Light Brown): Starts at approximately 35% and increases to approximately 80% at 5 interactions.
* Random (Gray): Constant at approximately 33%.
* **Gemma Oracle:**
* Direct (Blue): Starts at approximately 35% and increases to approximately 65% at 5 interactions.
* Beliefs (Orange): Starts at approximately 45% and increases to approximately 55% at 5 interactions.
* Bayesian Assistant (Light Brown): Starts at approximately 35% and increases to approximately 80% at 5 interactions.
* Random (Gray): Constant at approximately 33%.
* **Gemma Bayesian:**
* Direct (Blue): Starts at approximately 45% and increases to approximately 65% at 5 interactions.
* Beliefs (Orange): Starts at approximately 50% and increases to approximately 60% at 5 interactions.
* Bayesian Assistant (Light Brown): Starts at approximately 45% and increases to approximately 75% at 5 interactions.
* Random (Gray): Constant at approximately 33%.
**Llama Models:**
* **Llama Original:**
* Direct (Blue): Starts at approximately 35% and increases slightly to around 40% at 5 interactions.
* Beliefs (Orange): Starts at approximately 40% and increases slightly to around 45% at 5 interactions.
* Bayesian Assistant (Light Brown): Starts at approximately 35% and increases to approximately 85% at 5 interactions.
* Random (Gray): Constant at approximately 33%.
* **Llama Oracle:**
* Direct (Blue): Starts at approximately 35% and increases to approximately 60% at 5 interactions.
* Beliefs (Orange): Starts at approximately 45% and increases to approximately 55% at 5 interactions.
* Bayesian Assistant (Light Brown): Starts at approximately 35% and increases to approximately 80% at 5 interactions.
* Random (Gray): Constant at approximately 33%.
* **Llama Bayesian:**
* Direct (Blue): Starts at approximately 45% and increases to approximately 65% at 5 interactions.
* Beliefs (Orange): Starts at approximately 50% and increases to approximately 70% at 5 interactions.
* Bayesian Assistant (Light Brown): Starts at approximately 45% and increases to approximately 80% at 5 interactions.
* Random (Gray): Constant at approximately 33%.
**Qwen Models:**
* **Qwen Original:**
* Direct (Blue): Starts at approximately 35% and increases slightly to around 38% at 5 interactions.
* Beliefs (Orange): Starts at approximately 38% and decreases slightly to around 36% at 5 interactions.
* Bayesian Assistant (Light Brown): Starts at approximately 35% and increases to approximately 80% at 5 interactions.
* Random (Gray): Constant at approximately 33%.
* **Qwen Oracle:**
* Direct (Blue): Starts at approximately 35% and increases slightly to around 48% at 5 interactions.
* Beliefs (Orange): Starts at approximately 38% and increases slightly to around 40% at 5 interactions.
* Bayesian Assistant (Light Brown): Starts at approximately 35% and increases to approximately 80% at 5 interactions.
* Random (Gray): Constant at approximately 33%.
* **Qwen Bayesian:**
* Direct (Blue): Starts at approximately 45% and increases slightly to around 50% at 5 interactions.
* Beliefs (Orange): Starts at approximately 40% and decreases slightly to around 38% at 5 interactions.
* Bayesian Assistant (Light Brown): Starts at approximately 45% and increases to approximately 80% at 5 interactions.
* Random (Gray): Constant at approximately 33%.
### Key Observations
* The "Bayesian Assistant" strategy (light brown dashed line) consistently shows the most significant improvement in accuracy across all models (Gemma, Llama, Qwen) and configurations (Original, Oracle, Bayesian) as the number of interactions increases.
* The "Random" strategy (gray dashed line) remains constant across all models and configurations, serving as a baseline.
* The "Direct" and "Beliefs" strategies (blue and orange lines, respectively) show varying degrees of improvement or even slight decreases in accuracy depending on the model and configuration.
* The "Oracle" and "Bayesian" configurations generally result in higher accuracy compared to the "Original" configuration for the "Direct" and "Beliefs" strategies.
### Interpretation
The data suggests that the "Bayesian Assistant" interaction strategy is highly effective in improving the accuracy of language models as the number of interactions increases. This indicates that incorporating Bayesian methods into the interaction process can significantly enhance the model's performance. The "Random" strategy serves as a control, demonstrating the baseline accuracy without any specific interaction strategy. The varying performance of the "Direct" and "Beliefs" strategies highlights the importance of choosing an appropriate interaction strategy based on the specific language model and configuration. The "Oracle" and "Bayesian" configurations appear to provide additional information or context that aids the model in improving its accuracy, particularly when using the "Direct" and "Beliefs" strategies.
DECODING INTELLIGENCE...
EXPERT: nemotron-free VERSION 1
RUNTIME: free/nvidia/nemotron-nano-12b-v2-vl:free
INTEL_VERIFIED
## Line Graphs: Model Performance Across Interaction Counts
### Overview
The image contains a 3x3 grid of line graphs comparing the accuracy of three AI models (Gemma, Llama, Qwen) across three configurations (Original, Oracle, Bayesian) over 5 interaction steps. Four performance metrics are tracked: Direct, Beliefs, Bayesian Assistant, and Random. Each graph shows distinct trends in accuracy improvement with increasing interactions.
### Components/Axes
- **X-axis**: "# interactions" (0–5, integer steps)
- **Y-axis**: "Accuracy (%)" (0–100, linear scale)
- **Legends**: Positioned at the top of each graph with four categories:
- **Direct** (blue circles)
- **Beliefs** (orange squares)
- **Bayesian Assistant** (beige diamonds)
- **Random** (gray dashed line)
- **Graph Titles**: Format = "[Model] [Configuration]" (e.g., "Gemma Original")
### Detailed Analysis
#### Gemma Original
- **Direct**: Starts at ~30%, rises to ~60% by interaction 5
- **Beliefs**: Peaks at ~50% (interaction 2), drops to ~45% by interaction 5
- **Bayesian Assistant**: Steady climb from ~30% to ~80%
- **Random**: Flat at ~30%
#### Gemma Oracle
- **Direct**: ~30% → ~50%
- **Beliefs**: Peaks at ~55% (interaction 3), drops to ~50%
- **Bayesian Assistant**: ~30% → ~75%
- **Random**: Flat at ~30%
#### Gemma Bayesian
- **Direct**: ~30% → ~65%
- **Beliefs**: Peaks at ~60% (interaction 3), drops to ~55%
- **Bayesian Assistant**: ~30% → ~85%
- **Random**: Flat at ~30%
#### Llama Original
- **Direct**: ~30% → ~50%
- **Beliefs**: Peaks at ~50% (interaction 2), drops to ~45%
- **Bayesian Assistant**: ~30% → ~80%
- **Random**: Flat at ~30%
#### Llama Oracle
- **Direct**: ~30% → ~55%
- **Beliefs**: Peaks at ~55% (interaction 3), drops to ~50%
- **Bayesian Assistant**: ~30% → ~75%
- **Random**: Flat at ~30%
#### Llama Bayesian
- **Direct**: ~30% → ~60%
- **Beliefs**: Peaks at ~60% (interaction 3), drops to ~55%
- **Bayesian Assistant**: ~30% → ~85%
- **Random**: Flat at ~30%
#### Qwen Original
- **Direct**: ~30% → ~50%
- **Beliefs**: Peaks at ~40% (interaction 1), drops to ~35%
- **Bayesian Assistant**: ~30% → ~80%
- **Random**: Flat at ~30%
#### Qwen Oracle
- **Direct**: ~30% → ~50%
- **Beliefs**: Peaks at ~40% (interaction 1), drops to ~35%
- **Bayesian Assistant**: ~30% → ~75%
- **Random**: Flat at ~30%
#### Qwen Bayesian
- **Direct**: ~30% → ~60%
- **Beliefs**: Peaks at ~50% (interaction 3), drops to ~45%
- **Bayesian Assistant**: ~30% → ~85%
- **Random**: Flat at ~30%
### Key Observations
1. **Bayesian Assistant Dominance**: Consistently achieves highest accuracy across all models and configurations, suggesting Bayesian methods significantly enhance performance.
2. **Direct vs. Beliefs**: Both metrics show initial improvement with interactions but plateau or decline after 3–4 steps, indicating diminishing returns.
3. **Random Baseline**: All models outperform the random baseline (30%) by interaction 1, demonstrating baseline effectiveness.
4. **Model-Specific Trends**:
- Qwen shows the most pronounced drop in Beliefs accuracy after peak
- Llama and Gemma maintain more stable Beliefs performance
- Bayesian configurations show 20–30% absolute improvement over Original/Oracle
### Interpretation
The data suggests Bayesian approaches (Bayesian Assistant) provide the most reliable accuracy gains, likely through probabilistic reasoning and uncertainty quantification. Direct and Beliefs metrics indicate that while interaction depth improves performance initially, excessive interactions may introduce noise or overfitting. The consistent Random baseline (30%) across all graphs implies these models outperform chance-level guessing by at least 30 percentage points. Notably, the Bayesian Assistant's performance improvement correlates with interaction count, suggesting it effectively leverages additional context. The Beliefs metric's volatility across models may reflect differences in how each architecture handles uncertainty representation.
DECODING INTELLIGENCE...