TECHNICAL ASSET FINGERPRINT
985b63992da1162f1add441a
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: gemma-3-27b-it-free VERSION 1
RUNTIME: google-free/gemma-3-27b-it
INTEL_VERIFIED
\n
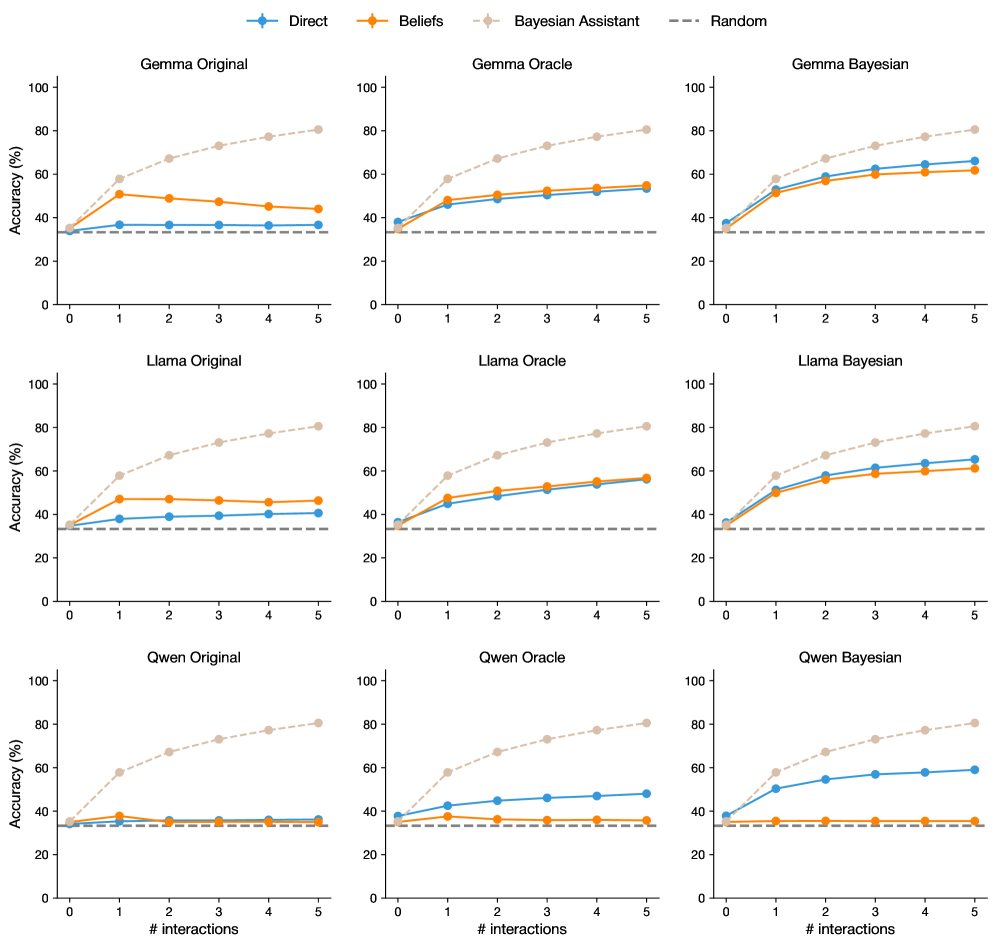
## Line Charts: Accuracy vs. Interactions for Different Models & Belief Systems
### Overview
This image presents nine separate line charts, arranged in a 3x3 grid. Each chart displays the relationship between the number of interactions and accuracy (%) for different language models (Gemma, Llama, Qwen) under different belief systems (Original, Oracle, Bayesian) and compared to a random baseline. The x-axis represents the number of interactions, ranging from 0 to 5. The y-axis represents accuracy, ranging from 0% to 100%. Each chart includes four lines representing "Direct", "Beliefs", "Bayesian Assistant", and "Random" approaches.
### Components/Axes
* **X-axis Label (all charts):** "# interactions"
* **Y-axis Label (all charts):** "Accuracy (%)"
* **Legend (top-right of each chart):**
* Blue Solid Line: "Direct"
* Orange Dashed Line: "Beliefs"
* Gray Solid Line: "Bayesian Assistant"
* Black Dashed-Dotted Line: "Random"
* **Chart Titles (top-center of each chart):**
* Gemma Original
* Gemma Oracle
* Gemma Bayesian
* Llama Original
* Llama Oracle
* Llama Bayesian
* Qwen Original
* Qwen Oracle
* Qwen Bayesian
### Detailed Analysis or Content Details
**Gemma Original:**
* Direct: Starts at approximately 45%, increases to approximately 65% at 5 interactions.
* Beliefs: Starts at approximately 40%, increases to approximately 50% at 5 interactions.
* Bayesian Assistant: Starts at approximately 35%, increases to approximately 45% at 5 interactions.
* Random: Remains relatively flat around 30% throughout all interactions.
**Gemma Oracle:**
* Direct: Starts at approximately 50%, increases to approximately 70% at 5 interactions.
* Beliefs: Starts at approximately 40%, increases to approximately 55% at 5 interactions.
* Bayesian Assistant: Starts at approximately 40%, remains around 45% throughout all interactions.
* Random: Remains relatively flat around 30% throughout all interactions.
**Gemma Bayesian:**
* Direct: Starts at approximately 45%, increases to approximately 65% at 5 interactions.
* Beliefs: Starts at approximately 40%, increases to approximately 55% at 5 interactions.
* Bayesian Assistant: Starts at approximately 40%, increases to approximately 50% at 5 interactions.
* Random: Remains relatively flat around 30% throughout all interactions.
**Llama Original:**
* Direct: Starts at approximately 40%, increases to approximately 60% at 5 interactions.
* Beliefs: Starts at approximately 35%, increases to approximately 45% at 5 interactions.
* Bayesian Assistant: Starts at approximately 30%, increases to approximately 40% at 5 interactions.
* Random: Remains relatively flat around 30% throughout all interactions.
**Llama Oracle:**
* Direct: Starts at approximately 45%, increases to approximately 65% at 5 interactions.
* Beliefs: Starts at approximately 40%, increases to approximately 55% at 5 interactions.
* Bayesian Assistant: Starts at approximately 35%, remains around 40% throughout all interactions.
* Random: Remains relatively flat around 30% throughout all interactions.
**Llama Bayesian:**
* Direct: Starts at approximately 40%, increases to approximately 60% at 5 interactions.
* Beliefs: Starts at approximately 35%, increases to approximately 50% at 5 interactions.
* Bayesian Assistant: Starts at approximately 30%, increases to approximately 40% at 5 interactions.
* Random: Remains relatively flat around 30% throughout all interactions.
**Qwen Original:**
* Direct: Starts at approximately 45%, increases to approximately 65% at 5 interactions.
* Beliefs: Starts at approximately 40%, increases to approximately 50% at 5 interactions.
* Bayesian Assistant: Starts at approximately 35%, increases to approximately 45% at 5 interactions.
* Random: Remains relatively flat around 30% throughout all interactions.
**Qwen Oracle:**
* Direct: Starts at approximately 45%, increases to approximately 65% at 5 interactions.
* Beliefs: Starts at approximately 40%, increases to approximately 55% at 5 interactions.
* Bayesian Assistant: Starts at approximately 35%, remains around 40% throughout all interactions.
* Random: Remains relatively flat around 30% throughout all interactions.
**Qwen Bayesian:**
* Direct: Starts at approximately 45%, increases to approximately 65% at 5 interactions.
* Beliefs: Starts at approximately 40%, increases to approximately 55% at 5 interactions.
* Bayesian Assistant: Starts at approximately 35%, increases to approximately 45% at 5 interactions.
* Random: Remains relatively flat around 30% throughout all interactions.
### Key Observations
* The "Direct" approach consistently outperforms the other approaches across all models and belief systems.
* The "Random" approach consistently shows the lowest accuracy, serving as a baseline.
* The "Beliefs" and "Bayesian Assistant" approaches generally show similar trends, with moderate improvements in accuracy as the number of interactions increases.
* The "Oracle" belief system generally leads to slightly higher accuracy compared to the "Original" belief system for the "Direct" approach.
* The "Bayesian Assistant" approach appears to plateau in accuracy after a certain number of interactions (around 3-4) for the "Oracle" belief system in all models.
### Interpretation
The data suggests that a "Direct" approach to interacting with these language models yields the highest accuracy, and that accuracy generally increases with more interactions. The "Oracle" belief system seems to provide a slight advantage in accuracy, particularly when combined with the "Direct" approach. The "Beliefs" and "Bayesian Assistant" approaches offer some improvement over the "Random" baseline, but are significantly less effective than the "Direct" approach. The plateauing of the "Bayesian Assistant" approach with the "Oracle" belief system could indicate a limit to the benefits of Bayesian reasoning after a certain level of information is gathered. The consistent low performance of the "Random" approach highlights the importance of structured interaction for achieving higher accuracy. The similar performance across Gemma, Llama, and Qwen suggests that the underlying model architecture has less impact on the effectiveness of these interaction strategies than the interaction strategy itself.
DECODING INTELLIGENCE...