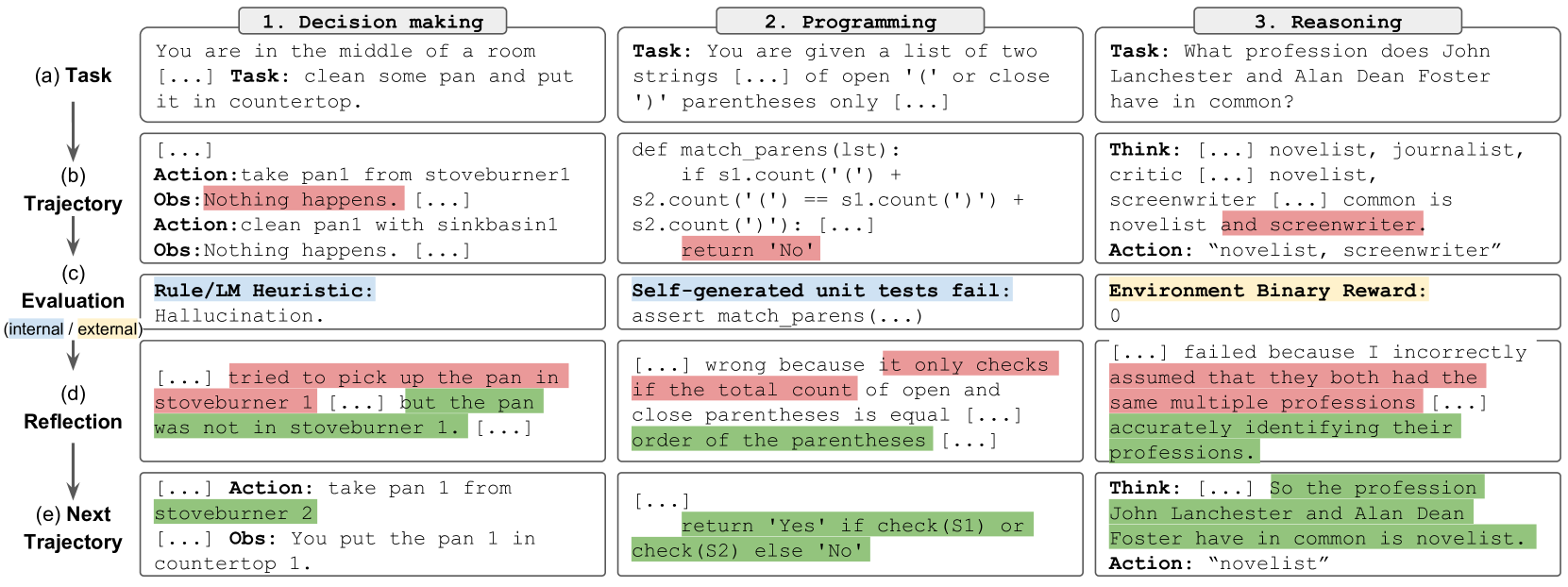
## Diagram: Model Process Comparison
### Overview
The image presents a diagram comparing three different model processes: Decision Making, Programming, and Reasoning. Each process is illustrated with a series of steps, showcasing tasks, actions, observations, evaluations, reflections, and subsequent trajectories. Key elements in the text are highlighted with different colors to indicate their function or status.
### Components/Axes
* **Title:** The diagram is divided into three sections, each with a numbered title:
1. Decision making
2. Programming
3. Reasoning
* **Process Steps:** Each section includes the following steps, represented as stages of a process flowing downwards:
* (a) Task
* (b) Trajectory
* (c) Evaluation (labeled "(internal / external)" and highlighted with two distinct colors)
* (d) Reflection
* (e) Next Trajectory
* **Color Coding (Implicit Legend):** Text within the process steps is highlighted in different colors:
* Red: Indicates potential problems, errors, or incorrect assumptions.
* Green: Indicates successful actions, observations, or correct conclusions.
* Blue: Indicates the type of evaluation
* Yellow/Orange: Indicates evaluation (internal or external)
### Detailed Analysis or Content Details
**1. Decision Making:**
* **(a) Task:** "You are in the middle of a room [...] Task: clean some pan and put it in countertop."
* **(b) Trajectory:**
* "Action: take pan1 from stoveburner1" Highlighted in red. "Obs: Nothing happens. [...]"
* "Action: clean pan1 with sinkbasin1" Highlighted in red. "Obs: Nothing happens. [...]"
* **(c) Evaluation:** "Rule/LM Heuristic: Hallucination." - The title "Rule/LM Heuristic" is highlighted in blue, and the word "Hallucination." is not.
* **(d) Reflection:** "[...] tried to pick up the pan in stoveburner 1 [...]" highlighted in red, "but the pan was not in stoveburner 1. [...]" highlighted in green.
* **(e) Next Trajectory:**
* "Action: take pan 1 from stoveburner 2" highlighted in green.
* "Obs: You put the pan 1 in countertop 1." highlighted in green.
**2. Programming:**
* **Task:** "Task: You are given a list of two strings [...] of open '(' or close ')' parentheses only [...]"
* **Code Snippet:**
```
def match_parens(lst):
if s1.count('(') +
s2.count('(') == s1.count(')') +
s2.count(')'): [...]
return 'No'
```
* **Evaluation:** "Self-generated unit tests fail: assert match\_parens(...)" - The title "Self-generated unit tests fail" is highlighted in blue.
* **Reflection:**
* "[...] wrong because it only checks if the total count of open and close parentheses is equal [...]" highlighted in red.
* "order of the parentheses [...]" highlighted in green.
* **Next Trajectory:**
* "[...] return 'Yes' if check(S1) or check(S2) else 'No'" highlighted in green.
**3. Reasoning:**
* **Task:** "Task: What profession does John Lanchester and Alan Dean Foster have in common?"
* **Think:** "[...] novelist, journalist, critic [...] novelist, screenwriter [...] common is novelist and screenwriter." - the words "novelist and screenwriter" are highlighted in red. "Action: "novelist, screenwriter""
* **Evaluation:** "Environment Binary Reward: 0" - The title "Environment Binary Reward:" is highlighted in orange/yellow. The value "0" is not.
* **Reflection:**
* "[...] failed because I incorrectly assumed that they both had the same multiple professions [...]" highlighted in red.
* "accurately identifying their professions." highlighted in green.
* **Next Trajectory:**
* "Think: [...] So the profession John Lanchester and Alan Dean Foster have in common is novelist." highlighted in green.
* "Action: "novelist"" highlighted in green.
### Key Observations
* Each process (Decision Making, Programming, Reasoning) follows a similar flow: Task -> Trajectory -> Evaluation -> Reflection -> Next Trajectory.
* The color-coding consistently highlights errors/failures in red and successes in green across all three processes.
* The "Evaluation" step uses distinct blue and orange/yellow to categorize the type of evaluation applied (Rule/LM Heuristic, Self-generated unit tests, and Environment Binary Reward).
### Interpretation
The diagram illustrates a comparative analysis of how different models handle decision-making, programming, and reasoning tasks. The processes are broken down into steps to show the flow of information, actions taken, and feedback received. The color-coding helps to quickly identify where errors occur and where corrections are made.
* **Decision Making:** The initial attempt to clean a pan fails because the pan isn't where the model expects it to be. The model recovers by looking in a different location (stoveburner 2). This suggests a basic level of problem-solving and adaptation.
* **Programming:** The model fails at a unit test because the code only checks the count of open and closed parentheses, not their order. This demonstrates a limitation in the model's understanding of the problem's requirements and a need for more sophisticated parsing logic.
* **Reasoning:** The model initially fails to accurately identify the common profession of John Lanchester and Alan Dean Foster, then corrects its answer by inferring from the task.
The use of internal vs external evaluation is interesting. The decision making relies on a rule or LM heuristic, which is internal.
Programming relies on self-generated unit tests.
Reasoning relies on an external binary reward.
Overall, the diagram effectively highlights the iterative nature of problem-solving in AI models, showing how errors and reflection lead to improved performance.