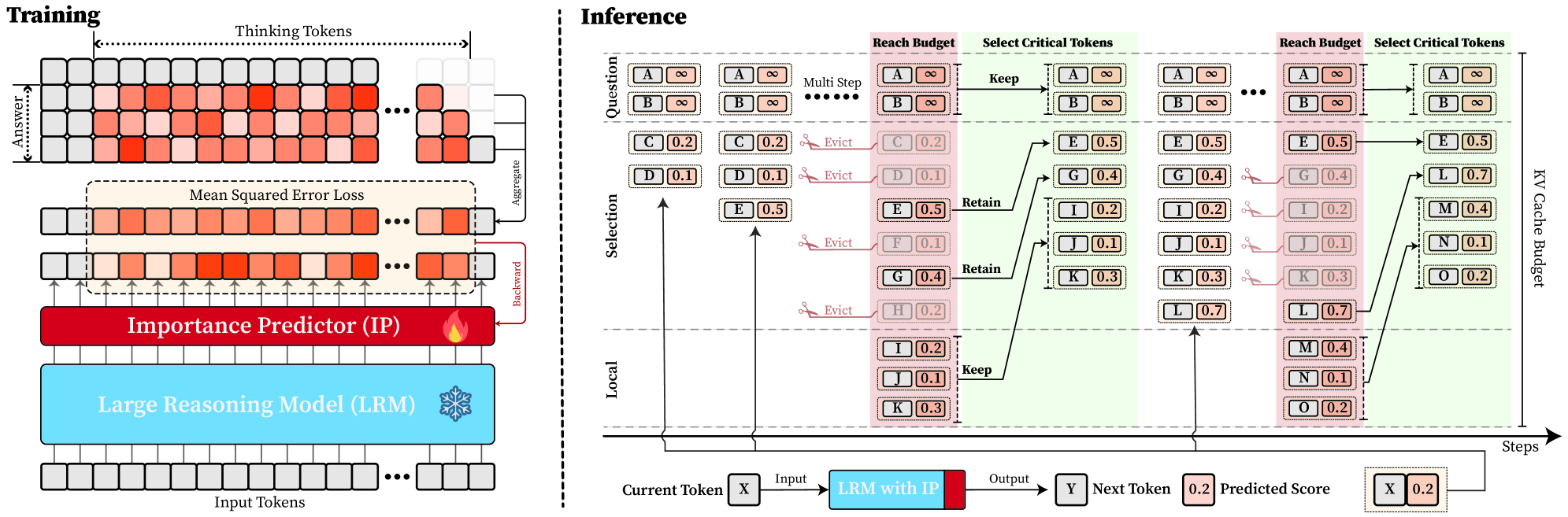
\n
## Diagram: Reaching Budget for Critical Tokens in a Reasoning Model
### Overview
This diagram illustrates the training and inference processes of a reasoning model, focusing on how critical tokens are selected and managed within a reach budget. The left side depicts the training phase, while the right side details the inference process, broken down into multiple steps. The core concept revolves around an Importance Predictor (IP) and a Large Reasoning Model (LRM) working together to identify and retain relevant information.
### Components/Axes
The diagram is divided into two main sections: "Training" (left) and "Inference" (right).
**Training Section:**
* **Input Tokens:** Represented as a grid of small rectangles.
* **Thinking Tokens:** A grid of small rectangles above the Input Tokens.
* **Answer Tokens:** A grid of small rectangles below the Input Tokens.
* **Importance Predictor (IP):** A flame-shaped icon.
* **Large Reasoning Model (LRM):** A snowflake-shaped icon.
* **Mean Squared Error Loss:** Label above the Thinking Tokens.
* **Aggregate & Backward:** Arrows indicating the flow of information.
**Inference Section:**
* **Question:** Label at the top-left of the inference section.
* **Multi Step:** Label indicating multiple steps in the inference process.
* **Reach Budget:** Label above the token selection grids.
* **Select Critical Tokens:** Label above the token selection grids.
* **Keep/Evict/Retain:** Labels indicating actions taken on tokens.
* **KV Cache Budget:** Label on the right side of the token selection grids.
* **Current Token X:** Label at the bottom-left.
* **LRM with IP:** Label indicating the integration of the LRM and IP.
* **Input:** Label indicating the input to the LRM.
* **Output:** Label indicating the output of the LRM.
* **Y Next Token:** Label indicating the next token.
* **Predicted Score:** Label indicating the predicted score.
* **Steps:** Label at the bottom-right.
* **Tokens A-O:** Represented as rectangles within the grids. Each token has an associated numerical value.
### Detailed Analysis or Content Details
**Training Section:**
The training section shows a flow of information from Input Tokens to Thinking Tokens to Answer Tokens. The Mean Squared Error Loss is calculated and used to refine the Importance Predictor (IP) and Large Reasoning Model (LRM). The flow is indicated by "Aggregate" and "Backward" arrows.
**Inference Section:**
The inference section is broken down into multiple steps, each involving the selection of critical tokens.
* **Step 1:**
* Tokens A, B, C, D, E, F, G, H, I, J, K are present.
* Token A has a value of ∞ (infinity).
* Token B has a value of ∞ (infinity).
* Token C has a value of 0.2.
* Token D has a value of 0.1.
* Token E has a value of 0.5.
* Token F has a value of 0.1.
* Token G has a value of 0.4.
* Token H has a value of 0.2.
* Token I has a value of 0.1.
* Token J has a value of 0.3.
* Token K has a value of 0.3.
* "Evict" is indicated for tokens C and E.
* "Retain" is indicated for token I.
* **Step 2:**
* Tokens A, B, C, D, E, G, H, I, J, K, L, M, N, O are present.
* Token A has a value of ∞ (infinity).
* Token B has a value of ∞ (infinity).
* Token C has a value of 0.2.
* Token D has a value of 0.1.
* Token E has a value of 0.5.
* Token G has a value of 0.4.
* Token H has a value of 0.2.
* Token I has a value of 0.1.
* Token J has a value of 0.3.
* Token K has a value of 0.3.
* Token L has a value of 0.7.
* Token M has a value of 0.4.
* Token N has a value of 0.1.
* Token O has a value of 0.2.
* "Evict" is indicated for tokens D and H.
* "Keep" is indicated for token B.
* **Bottom Flow:**
* Current Token X is input into the LRM with IP, producing Output Y (Next Token) and a Predicted Score of 0.2.
* The next token is X, with a value of 0.2.
### Key Observations
* The values associated with the tokens appear to represent some form of importance or relevance score.
* The "Reach Budget" and "KV Cache Budget" suggest a constraint on the number of tokens that can be retained.
* The Importance Predictor (IP) plays a crucial role in guiding the selection of critical tokens.
* The process is iterative, with multiple steps involved in refining the selection of tokens.
* The infinity values (∞) likely represent tokens that are considered highly important and are always retained.
### Interpretation
This diagram illustrates a mechanism for efficient reasoning by selectively retaining critical information. The LRM, guided by the IP, prioritizes tokens based on their relevance to the question. The reach and cache budgets impose constraints, forcing the model to make choices about which tokens to keep and which to evict. The iterative process allows the model to refine its selection over multiple steps, ultimately leading to a more focused and efficient reasoning process. The numerical values associated with the tokens likely represent the IP's confidence in their importance. The "Keep," "Evict," and "Retain" actions demonstrate a dynamic memory management strategy. The diagram suggests a system designed to handle long-context reasoning tasks by intelligently managing the information available to the model. The flow from Input Tokens to Output Y represents the core reasoning process, with the IP acting as a filter to enhance performance. The Mean Squared Error Loss in the training phase indicates that the IP is being trained to accurately predict token importance.