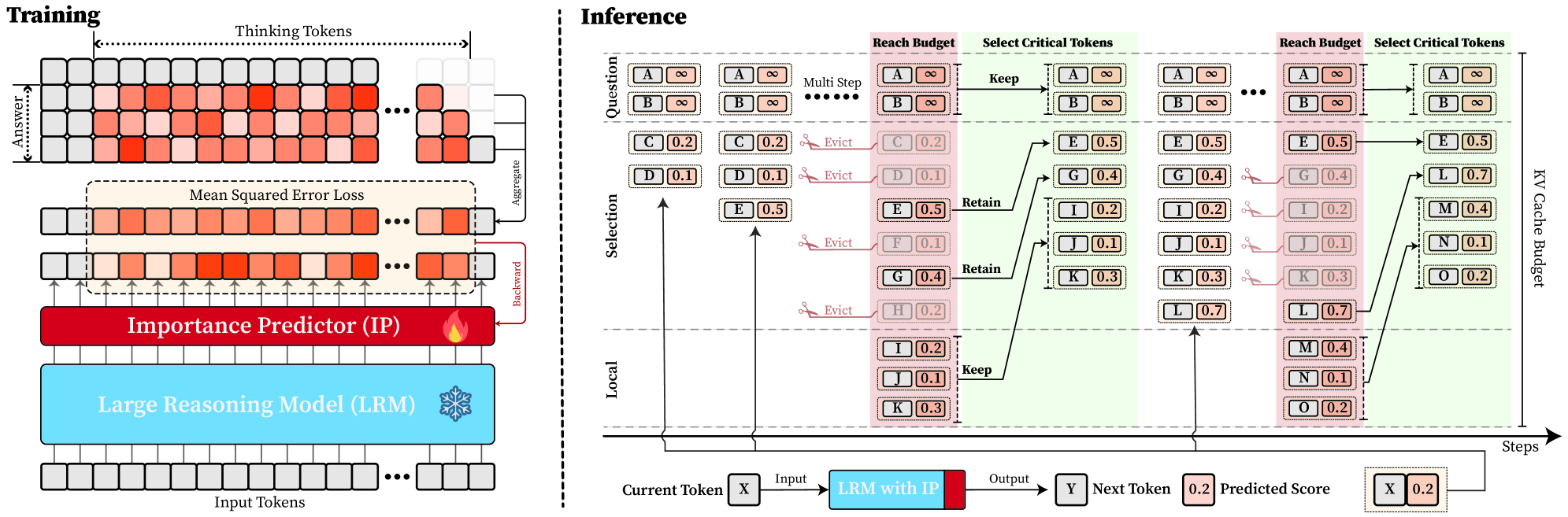
## Diagram: Machine Learning Model Training and Inference Pipeline
### Overview
The image depicts a technical diagram illustrating the training and inference processes of a machine learning model, specifically a Large Reasoning Model (LRM) with an Importance Predictor (IP). The diagram is divided into two main sections: **Training** (left) and **Inference** (right), with distinct color-coded components and token flow visualization.
---
### Components/Axes
#### Training Section (Left)
- **Input Tokens**: Gray squares at the bottom, labeled as the starting point.
- **Large Reasoning Model (LRM)**: Blue rectangle processing input tokens.
- **Thinking Tokens**: Red squares generated by the LRM, representing intermediate reasoning steps.
- **Mean Squared Error Loss**: Orange gradient overlay on thinking tokens, indicating error calculation.
- **Importance Predictor (IP)**: Red rectangle analyzing token importance.
- **Answer**: Final output derived from processed tokens.
#### Inference Section (Right)
- **Current Token (X)**: Input token at the start of the inference pipeline.
- **LRM with IP**: Blue component processing tokens during inference.
- **Output (Y)**: Predicted next token.
- **Predicted Score**: Numerical values (e.g., 0.2, 0.5) indicating token importance.
- **KV Cache Cache Budget**: Memory constraint for retaining tokens.
- **Steps**: Sequential processing steps (e.g., "Reach Budget," "Select Critical Tokens").
---
### Detailed Analysis
#### Training Section
1. **Input Tokens → LRM**: Input tokens are fed into the LRM, which generates **Thinking Tokens** (red squares).
2. **Error Calculation**: The **Mean Squared Error Loss** (orange gradient) is applied to the thinking tokens to measure prediction accuracy.
3. **Importance Prediction**: The **Importance Predictor (IP)** evaluates token relevance, prioritizing critical tokens for retention.
4. **Aggregation**: Tokens are aggregated to form the final **Answer**.
#### Inference Section
1. **Token Processing Flow**:
- **Current Token (X)** is processed by the **LRM with IP**, producing **Output (Y)** and a **Predicted Score**.
- Tokens are evaluated against a **Reach Budget** (pink shaded area) to determine criticality.
- **Select Critical Tokens**: Tokens with scores above thresholds (e.g., 0.5) are retained; others are evicted.
- **KV Cache Budget**: Limits the number of tokens retained in memory (e.g., tokens A, B, E, G are kept).
2. **Token Retention Logic**:
- Tokens like **A** (score: ∞) and **B** (score: ∞) are always retained.
- Lower-scoring tokens (e.g., **C**: 0.2, **D**: 0.1) are evicted to optimize memory usage.
- Critical tokens (e.g., **E**: 0.5, **G**: 0.4) are retained for subsequent steps.
---
### Key Observations
1. **Training Efficiency**: The IP reduces computational overhead by focusing on high-importance tokens during training.
2. **Inference Optimization**: The KV Cache Budget enforces memory constraints, prioritizing tokens with scores ≥ 0.5 for retention.
3. **Token Dynamics**: High-scoring tokens (e.g., **A**, **B**) dominate the cache, while lower-scoring tokens (e.g., **C**, **D**) are evicted early.
4. **Iterative Steps**: The inference process repeats across multiple steps, refining token selection and output predictions.
---
### Interpretation
- **Purpose**: The diagram demonstrates how the LRM with IP balances accuracy and efficiency by dynamically managing token importance during training and inference.
- **Critical Tokens**: Tokens with infinite scores (A, B) are deemed essential, possibly representing ground-truth or high-confidence predictions.
- **Memory Constraints**: The KV Cache Budget ensures the model operates within resource limits, evicting less critical tokens to maintain performance.
- **Trade-offs**: While retaining high-scoring tokens improves output quality, aggressive eviction of low-scoring tokens may risk losing nuanced context.
---
### Uncertainties
- Exact numerical thresholds for the **Reach Budget** and **KV Cache Budget** are not explicitly defined.
- The relationship between **Mean Squared Error Loss** and token importance scores requires further clarification.
- The role of **Thinking Tokens** in the training phase is abstracted; their exact function in error calculation is unspecified.