\n
## Bar Chart: Accuracy Comparison of Original and Fine-tuned Models
### Overview
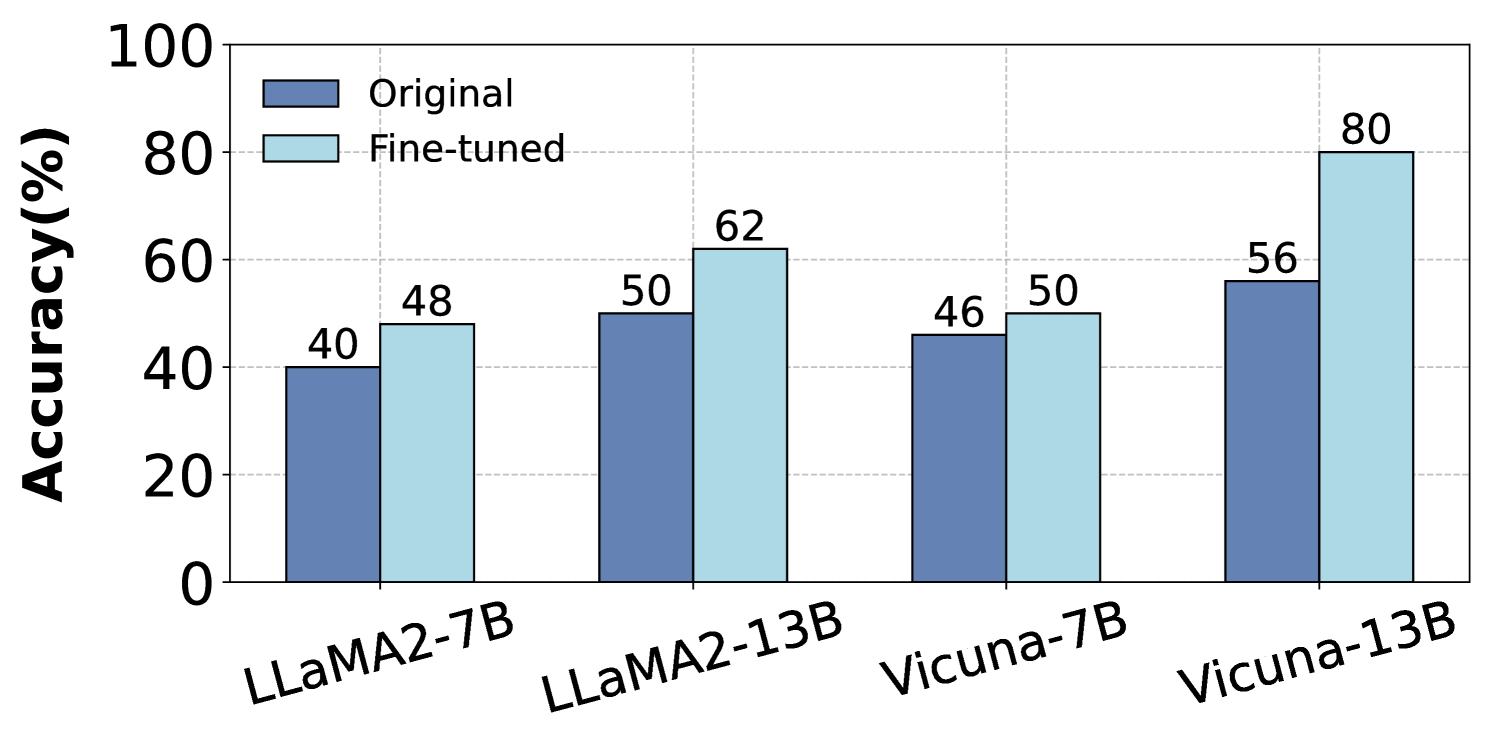
This bar chart compares the accuracy of original and fine-tuned language models across four different model types: LLaMA2-7B, LLaMA2-13B, Vicuna-7B, and Vicuna-13B. Accuracy is measured in percentage points.
### Components/Axes
* **X-axis:** Model Type (LLaMA2-7B, LLaMA2-13B, Vicuna-7B, Vicuna-13B)
* **Y-axis:** Accuracy (%) - Scale ranges from 0 to 100, with increments of 20.
* **Legend:**
* Dark Blue: "Original"
* Light Blue: "Fine-tuned"
### Detailed Analysis
The chart consists of paired bars for each model type, representing the accuracy of the original and fine-tuned versions.
* **LLaMA2-7B:**
* Original: Approximately 40% accuracy.
* Fine-tuned: Approximately 48% accuracy.
* **LLaMA2-13B:**
* Original: Approximately 50% accuracy.
* Fine-tuned: Approximately 62% accuracy.
* **Vicuna-7B:**
* Original: Approximately 46% accuracy.
* Fine-tuned: Approximately 50% accuracy.
* **Vicuna-13B:**
* Original: Approximately 56% accuracy.
* Fine-tuned: Approximately 80% accuracy.
### Key Observations
* Fine-tuning consistently improves accuracy across all model types.
* The largest improvement in accuracy is observed for Vicuna-13B, with a difference of approximately 24 percentage points between the original and fine-tuned versions.
* LLaMA2-7B shows the smallest improvement, with a difference of approximately 8 percentage points.
* Vicuna-13B achieves the highest accuracy overall (80%) after fine-tuning.
### Interpretation
The data strongly suggests that fine-tuning is an effective method for improving the accuracy of these language models. The magnitude of improvement varies depending on the model type, with larger models (13B parameters) generally benefiting more from fine-tuning than smaller models (7B parameters). The substantial accuracy gain observed in Vicuna-13B indicates that this model has a greater capacity to learn from fine-tuning data. This could be due to its architecture, pre-training data, or other factors. The consistent positive impact of fine-tuning across all models highlights its general applicability as a technique for enhancing language model performance. The chart provides quantitative evidence supporting the claim that fine-tuning can significantly boost the capabilities of these models.