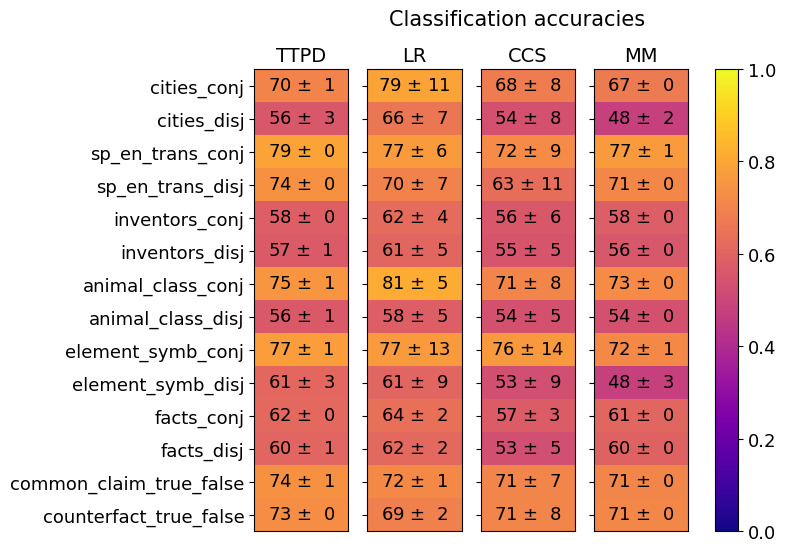
\n
## Heatmap: Classification Accuracies
### Overview
The image is a heatmap titled "Classification accuracies" that displays the performance (accuracy) of four different models or methods across fourteen distinct classification tasks. The performance is quantified as a mean accuracy percentage with an associated standard deviation (e.g., "70 ± 1"). A color scale on the right maps these accuracy values to a gradient from purple (low accuracy, ~0.0) to yellow (high accuracy, ~1.0).
### Components/Axes
* **Title:** "Classification accuracies" (top center).
* **Column Headers (Models/Methods):** Four columns are labeled:
* **TTPD** (leftmost column)
* **LR**
* **CCS**
* **MM** (rightmost column)
* **Row Labels (Tasks/Datasets):** Fourteen rows, each representing a specific task. The labels are:
1. `cities_conj`
2. `cities_disj`
3. `sp_en_trans_conj`
4. `sp_en_trans_disj`
5. `inventors_conj`
6. `inventors_disj`
7. `animal_class_conj`
8. `animal_class_disj`
9. `element_symb_conj`
10. `element_symb_disj`
11. `facts_conj`
12. `facts_disj`
13. `common_claim_true_false`
14. `counterfact_true_false`
* **Color Scale/Legend:** A vertical color bar is positioned to the right of the heatmap. It is labeled from **0.0** (bottom, dark purple) to **1.0** (top, bright yellow), with intermediate ticks at 0.2, 0.4, 0.6, and 0.8. This provides the key for interpreting the cell colors.
* **Data Cells:** Each cell in the 14x4 grid contains a text string in the format "mean ± std" (e.g., "70 ± 1"). The background color of each cell corresponds to the mean value according to the color scale.
### Detailed Analysis
Below is the extracted data for each task (row), organized by model (column). Values are mean accuracy ± standard deviation.
| Task | TTPD | LR | CCS | MM |
| :--- | :--- | :--- | :--- | :--- |
| **cities_conj** | 70 ± 1 | 79 ± 11 | 68 ± 8 | 67 ± 0 |
| **cities_disj** | 56 ± 3 | 66 ± 7 | 54 ± 8 | 48 ± 2 |
| **sp_en_trans_conj** | 79 ± 0 | 77 ± 6 | 72 ± 9 | 77 ± 1 |
| **sp_en_trans_disj** | 74 ± 0 | 70 ± 7 | 63 ± 11 | 71 ± 0 |
| **inventors_conj** | 58 ± 0 | 62 ± 4 | 56 ± 6 | 58 ± 0 |
| **inventors_disj** | 57 ± 1 | 61 ± 5 | 55 ± 5 | 56 ± 0 |
| **animal_class_conj** | 75 ± 1 | 81 ± 5 | 71 ± 8 | 73 ± 0 |
| **animal_class_disj** | 56 ± 1 | 58 ± 5 | 54 ± 5 | 54 ± 0 |
| **element_symb_conj** | 77 ± 1 | 77 ± 13 | 76 ± 14 | 72 ± 1 |
| **element_symb_disj** | 61 ± 3 | 61 ± 9 | 53 ± 9 | 48 ± 3 |
| **facts_conj** | 62 ± 0 | 64 ± 2 | 57 ± 3 | 61 ± 0 |
| **facts_disj** | 60 ± 1 | 62 ± 2 | 53 ± 5 | 60 ± 0 |
| **common_claim_true_false** | 74 ± 1 | 72 ± 1 | 71 ± 7 | 71 ± 0 |
| **counterfact_true_false** | 73 ± 0 | 69 ± 2 | 71 ± 8 | 71 ± 0 |
**Trend Verification by Model:**
* **TTPD:** Shows relatively stable performance. Its highest accuracy is on `sp_en_trans_conj` (79) and lowest on `cities_disj` (56). The standard deviations are very low (0-3), indicating consistent results.
* **LR:** Exhibits the highest single accuracy on the chart (`animal_class_conj`: 81) but also high variance, as seen in the large standard deviation for `element_symb_conj` (±13). It generally performs well on "_conj" tasks.
* **CCS:** Tends to have the lowest accuracies and the highest standard deviations (e.g., `element_symb_conj`: ±14, `sp_en_trans_disj`: ±11), suggesting its performance is less stable across runs or samples.
* **MM:** Performance is often similar to or slightly lower than TTPD. It shows notably low accuracy on `cities_disj` (48) and `element_symb_disj` (48), which are among the lowest values in the entire table.
**Trend Verification by Task Type:**
A clear pattern emerges when comparing tasks with the suffix `_conj` (likely conjunction) versus `_disj` (likely disjunction). For every corresponding pair, the `_conj` task has a higher mean accuracy than its `_disj` counterpart across all models. For example, `cities_conj` (70, 79, 68, 67) vs. `cities_disj` (56, 66, 54, 48).
### Key Observations
1. **Conjunction vs. Disjunction Gap:** The most striking pattern is the consistent performance drop from `_conj` to `_disj` tasks. This suggests that disjunctive reasoning is significantly harder for all four evaluated models.
2. **Model Strengths:** LR achieves the highest peak performance (81 on `animal_class_conj`) but also shows high variance. TTPD appears the most consistent (lowest standard deviations). CCS is the weakest and least stable overall.
3. **Task Difficulty:** `inventors_conj/disj` and `animal_class_disj` appear to be among the hardest tasks, with accuracies clustered in the mid-50s to low-60s. `sp_en_trans_conj` and `animal_class_conj` are among the easiest.
4. **Outliers:** The `element_symb_conj` task shows exceptionally high variance for LR (±13) and CCS (±14), indicating unstable model behavior on this specific task. The `cities_disj` task for MM (48 ± 2) is a notable low point.
### Interpretation
This heatmap provides a comparative analysis of model capabilities on structured reasoning tasks. The data strongly suggests that the logical structure of the task (conjunction vs. disjunction) is a primary determinant of difficulty, more so than the specific domain (cities, translations, animals, etc.). All models struggle with disjunctive reasoning.
From a Peircean perspective, the `_conj` tasks likely require abductive or deductive reasoning to combine information, while `_disj` tasks may require more complex abductive reasoning to evaluate multiple possibilities, which is a harder inferential step. The high variance in CCS and on specific tasks like `element_symb_conj` could indicate that the model's internal representations for those concepts are less robust or that the training data for those domains is noisier.
The practical implication is that model development should focus on improving robustness for disjunctive reasoning. The stability of TTPD might make it preferable for applications requiring reliable, if not peak, performance. The LR model's high variance suggests it may be overfitting to certain patterns in the "_conj" tasks. This chart is a valuable diagnostic tool for understanding not just *if* models fail, but *how* and *under what logical conditions* they fail.