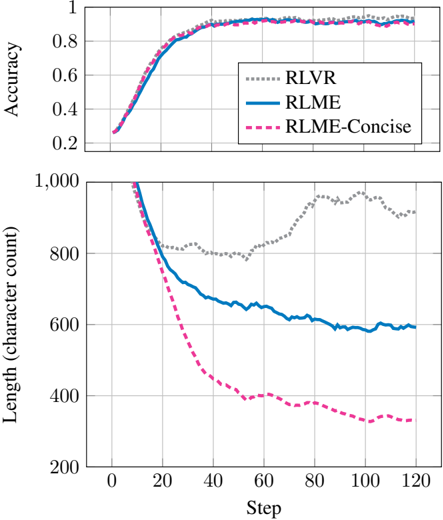
## Line Chart: Accuracy and Length vs. Training Steps
### Overview
The image displays a two-panel line chart comparing the performance of three different methods—RLVR, RLME, and RLME-Concise—over the course of 120 training steps. The top panel tracks "Accuracy," while the bottom panel tracks "Length (character count)." The chart is designed to illustrate the trade-off between output quality (accuracy) and efficiency (conciseness) during a training or optimization process.
### Components/Axes
* **Chart Type:** Two vertically stacked line charts sharing a common x-axis.
* **X-Axis (Both Panels):**
* **Label:** "Step"
* **Scale:** Linear, from 0 to 120.
* **Major Tick Marks:** 0, 20, 40, 60, 80, 100, 120.
* **Top Panel Y-Axis:**
* **Label:** "Accuracy"
* **Scale:** Linear, from 0.2 to 1.0.
* **Major Tick Marks:** 0.2, 0.4, 0.6, 0.8, 1.0.
* **Bottom Panel Y-Axis:**
* **Label:** "Length (character count)"
* **Scale:** Linear, from 200 to 1000.
* **Major Tick Marks:** 200, 400, 600, 800, 1000.
* **Legend:**
* **Position:** Top-right corner of the top panel.
* **Entries:**
1. **RLVR:** Represented by a gray dotted line (`...`).
2. **RLME:** Represented by a solid blue line (`—`).
3. **RLME-Concise:** Represented by a pink dashed line (`--`).
### Detailed Analysis
**Top Panel: Accuracy vs. Step**
* **Trend Verification:** All three lines show a similar, strong positive trend. They start at a low accuracy and rise steeply before plateauing.
* **Data Points & Values (Approximate):**
* **Start (Step 0):** All three methods begin at an accuracy of approximately **0.25**.
* **Rapid Ascent (Steps 0-40):** Accuracy increases sharply for all lines. By step 40, all are above **0.8**.
* **Plateau (Steps 40-120):** The curves flatten. From step 60 onward, accuracy for all methods hovers between **~0.88 and ~0.95**.
* **Relative Performance:** The lines are tightly clustered. RLME-Concise (pink dashed) appears to reach a marginally higher final accuracy (≈0.94) than RLME (blue solid, ≈0.92) and RLVR (gray dotted, ≈0.91) by step 120, though the difference is small.
**Bottom Panel: Length vs. Step**
* **Trend Verification:** The lines show divergent trends. RLVR fluctuates, while RLME and RLME-Concise show strong negative trends (decreasing length).
* **Data Points & Values (Approximate):**
* **Start (Step 0):** All three methods begin with a high character count, near or at the top of the scale (**≈1000**).
* **RLVR (Gray Dotted):** Drops to ~800 by step 20, fluctuates between ~780 and ~820 until step 60, then **increases** to a peak of ~950 around step 100 before settling at ~900 by step 120.
* **RLME (Blue Solid):** Shows a steady, monotonic decrease. It falls to ~700 by step 40, ~650 by step 60, and continues a gradual decline to approximately **600** by step 120.
* **RLME-Concise (Pink Dashed):** Exhibits the most dramatic reduction. It plummets to ~500 by step 30, ~400 by step 50, and continues a slower decline to approximately **320** by step 120.
### Key Observations
1. **Accuracy Convergence:** Despite different approaches, all three methods achieve nearly identical high accuracy (>90%) after sufficient training steps (≈60+).
2. **Length Divergence:** There is a stark contrast in output length. RLME-Concise is the most efficient, producing outputs less than one-third the length of its starting point and about half the length of standard RLME by the end.
3. **RLVR Anomaly:** The RLVR method's length does not decrease sustainably. After an initial drop, it trends upward again after step 60, suggesting it may be generating more verbose or redundant outputs as training progresses, without a corresponding gain in accuracy.
4. **Conciseness Without Sacrifice:** RLME-Concise achieves its goal. It matches or slightly exceeds the accuracy of the other methods while producing significantly shorter outputs.
### Interpretation
This chart demonstrates the effectiveness of a "conciseness" objective (RLME-Concise) in a reinforcement learning or model optimization context. The data suggests that:
* **The core task is learnable:** All methods successfully learn to perform the task with high accuracy.
* **Optimization for brevity works:** Incorporating a penalty or incentive for shorter outputs (as in RLME-Concise) successfully drives the model to generate much more concise responses without harming—and potentially even slightly improving—final accuracy.
* **Inefficiency in Baseline (RLVR):** The RLVR method appears inefficient. Its increasing length in later steps indicates it may be "overthinking" or adding unnecessary content, a problem the RLME methods, especially the Concise variant, successfully avoid.
* **Practical Implication:** For applications where response length matters (e.g., user interfaces, API costs, latency), using an approach like RLME-Concise is highly beneficial. It delivers the same quality of result with greater efficiency. The chart provides clear visual evidence that accuracy and conciseness are not necessarily at odds and can be optimized simultaneously.