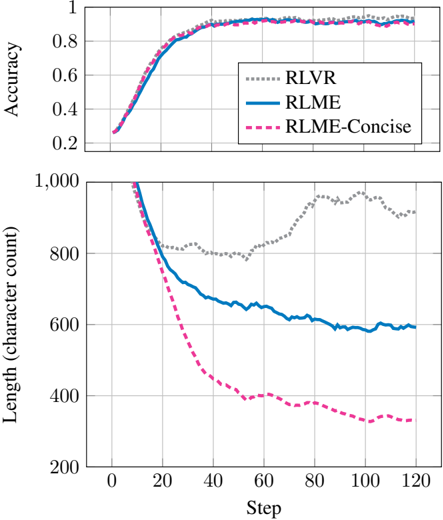
## Line Chart: Model Performance Over Training Steps
### Overview
The image contains two vertically stacked line charts comparing the performance of three models (RLVR, RLME, RLME-Concise) across two metrics: **Accuracy** (top chart) and **Length (character count)** (bottom chart). Both charts track changes over **Steps** (0–120) on the x-axis.
---
### Components/Axes
#### Top Chart (Accuracy)
- **X-axis**: "Step" (0–120, increments of 20)
- **Y-axis**: "Accuracy" (0–1, increments of 0.2)
- **Legend**: Located in the top-right corner, mapping:
- **RLVR**: Dotted gray line
- **RLME**: Solid blue line
- **RLME-Concise**: Dashed pink line
#### Bottom Chart (Length)
- **X-axis**: "Step" (0–120, increments of 20)
- **Y-axis**: "Length (character count)" (200–1000, increments of 200)
- **Legend**: Same as top chart, with lines extending to the bottom chart.
---
### Detailed Analysis
#### Top Chart (Accuracy)
- **Trend**: All three lines show rapid improvement in accuracy during the first 40 steps, plateauing near 0.95 by step 120.
- **RLVR** (dotted gray): Peaks slightly higher (~0.97) than the others, maintaining a steady lead.
- **RLME** (solid blue) and **RLME-Concise** (dashed pink): Nearly identical trajectories, with RLME-Concise dipping marginally below RLME after step 60.
- **Key Data Points**:
- Step 0: All models start near 0.2 accuracy.
- Step 40: All models reach ~0.9 accuracy.
- Step 120: All models stabilize between 0.93–0.97.
#### Bottom Chart (Length)
- **Trend**: All lines decline sharply in the first 40 steps, then flatten.
- **RLME-Concise** (dashed pink): Drops fastest, ending near 300 characters by step 120.
- **RLME** (solid blue): Declines to ~500 characters.
- **RLVR** (dotted gray): Declines slowest, ending near 800 characters.
- **Key Data Points**:
- Step 0: All models start near 1000 characters.
- Step 40: RLME-Concise reaches ~600, RLME ~700, RLVR ~850.
- Step 120: RLME-Concise ~300, RLME ~500, RLVR ~800.
---
### Key Observations
1. **Accuracy**: All models converge to high accuracy (>0.9) by step 40, with RLVR maintaining a slight edge.
2. **Efficiency**: RLME-Concise reduces length most aggressively, suggesting better optimization for brevity.
3. **Trade-off**: RLVR achieves the highest accuracy but retains the longest character count, indicating potential inefficiency in compression.
---
### Interpretation
The data suggests a trade-off between **accuracy** and **efficiency**:
- **RLVR** prioritizes accuracy at the cost of longer outputs.
- **RLME-Concise** optimizes for brevity while maintaining near-par accuracy to RLME.
- The rapid early improvement in both metrics implies that initial training steps are critical for performance gains. The divergence in length reduction highlights differences in model design, with RLME-Concise likely employing more aggressive compression techniques.