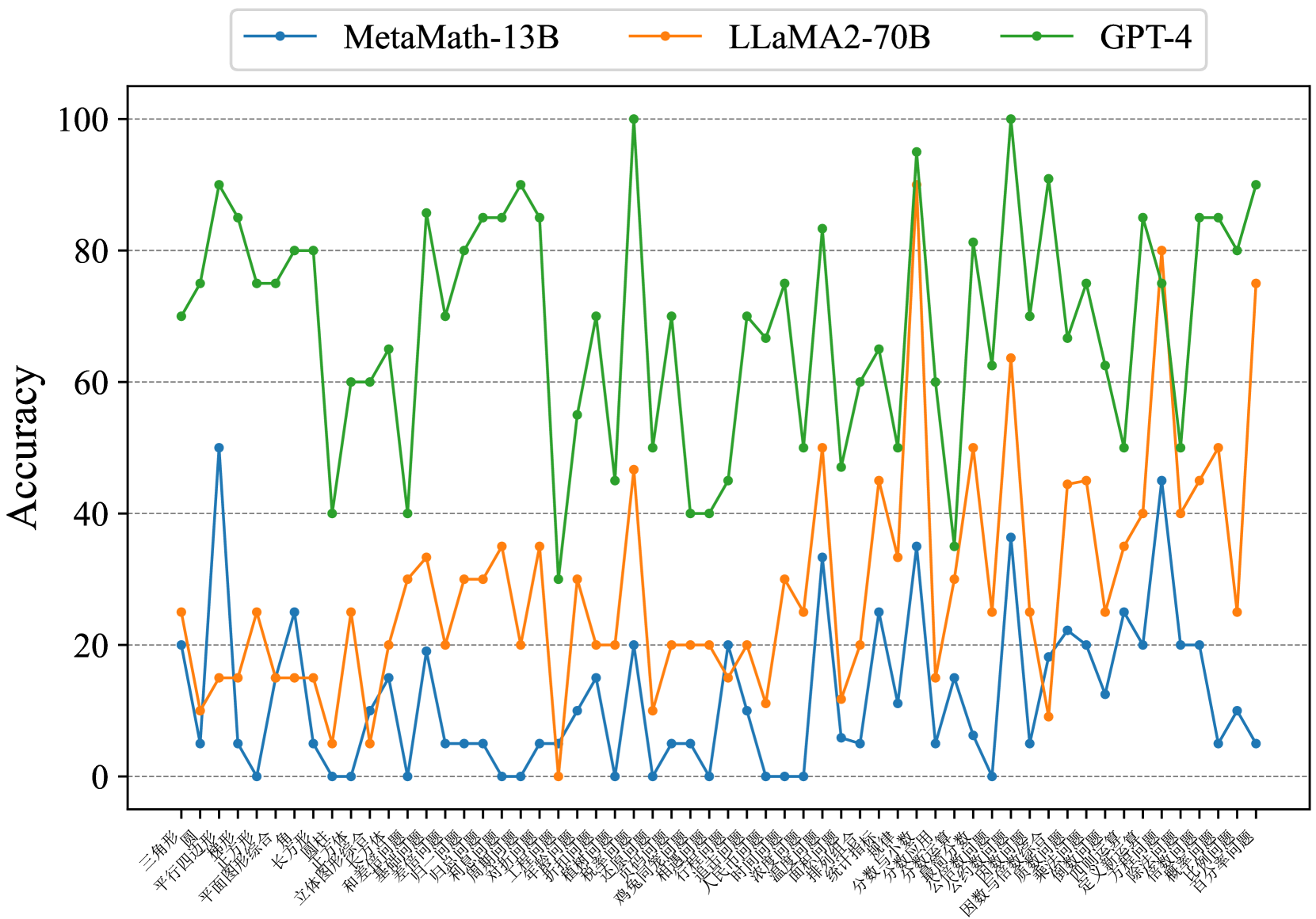
## Line Chart: Model Accuracy on Mathematical Problems
### Overview
This image presents a line chart comparing the accuracy of three large language models – MetaMath-13B, LLaMA2-70B, and GPT-4 – across a series of mathematical problems. The x-axis represents different mathematical problem types (labeled in Chinese characters), and the y-axis represents the accuracy score, ranging from 0 to 100.
### Components/Axes
* **X-axis Title:** (None explicitly labeled, but represents mathematical problem types)
* **Y-axis Title:** Accuracy
* **Y-axis Scale:** 0 to 100, with increments of 10.
* **Legend:** Located at the top-right of the chart.
* MetaMath-13B (Blue line with circular markers)
* LLaMA2-70B (Orange line with circular markers)
* GPT-4 (Green line with circular markers)
* **X-axis Labels:** A series of Chinese characters representing different mathematical problem types. These are densely packed along the x-axis. I will attempt to transcribe them as best as possible, but accuracy is limited.
* 三角形 (sānjiǎoxíng) - Triangle
* 平行四边形 (píngxíng sìbiānxíng) - Parallelogram
* 矩形 (jǔxíng) - Rectangle
* 立体几何 (lìtǐ jǐhé) - Solid Geometry
* 长方形 (chángfāngxíng) - Long Rectangle
* 立体图形 (lìtǐ túxíng) - Solid Shape
* 梯形 (tīxíng) - Trapezoid
* 圆 (yuán) - Circle
* 扇形 (shànxíng) - Sector
* 面积 (miànjī) - Area
* 体积 (tǐjī) - Volume
* 方程 (fāngchéng) - Equation
* 因数 (yīnsù) - Factor
* 分解 (fēnjiě) - Decomposition
* 概率 (gàilǜ) - Probability
* 统计 (tǒngjì) - Statistics
* 微积分 (wēijīfēn) - Calculus
* 线性代数 (xiànxìng dàishù) - Linear Algebra
* 复数 (fùshù) - Complex Number
* 数列 (shùliè) - Sequence
* 极限 (jíxiàn) - Limit
* 导数 (dǎoshù) - Derivative
* 积分 (jīfēn) - Integral
* 函数 (hánshù) - Function
* 三角函数 (sānjiǎo hánshù) - Trigonometric Function
* 向量 (xiàngliàng) - Vector
* 矩阵 (jǔzhèn) - Matrix
* 几何 (jǐhé) - Geometry
* 不等式 (bùděngshì) - Inequality
* 组合 (zǔhé) - Combination
* 排列 (páiliè) - Permutation
### Detailed Analysis
* **GPT-4 (Green Line):** The GPT-4 line exhibits a highly volatile pattern, fluctuating significantly between approximately 20% and 100% accuracy. It generally maintains a higher accuracy than the other two models, with frequent peaks near or at 100%. The trend is generally upward, but with substantial oscillations.
* Approximately 90% accuracy at the first data point (三角形).
* Drops to around 30% at 平行四边形.
* Reaches 100% at 矩形.
* Fluctuates between 60-100% for the next several data points.
* Maintains high accuracy (70-90%) for the final data points.
* **LLaMA2-70B (Orange Line):** The LLaMA2-70B line shows a relatively stable, but lower, accuracy compared to GPT-4. It generally ranges between 10% and 40% accuracy. The trend is relatively flat, with some minor fluctuations.
* Starts around 20% accuracy (三角形).
* Remains relatively stable around 20-30% for the first 10 data points.
* Increases to around 40% at 面积.
* Decreases to around 20% at 概率.
* Ends around 25% accuracy.
* **MetaMath-13B (Blue Line):** The MetaMath-13B line demonstrates the most erratic behavior, with significant dips and peaks. It generally has the lowest accuracy, ranging from 0% to approximately 50%. The trend is difficult to discern due to the high degree of fluctuation.
* Starts around 25% accuracy (三角形).
* Drops to 0% at 平行四边形.
* Peaks around 45% at 梯形.
* Fluctuates wildly between 0% and 40% for the majority of the data points.
* Ends around 10% accuracy.
### Key Observations
* GPT-4 consistently outperforms both LLaMA2-70B and MetaMath-13B across all problem types.
* LLaMA2-70B exhibits more stable performance than MetaMath-13B, but with lower overall accuracy.
* MetaMath-13B shows the highest degree of variability and the lowest overall accuracy.
* The problem type appears to significantly influence the accuracy of all models, as evidenced by the fluctuations in the lines.
* There is no clear correlation between the type of mathematical problem and the performance of the models.
### Interpretation
The chart demonstrates a clear hierarchy in the mathematical reasoning capabilities of the three models. GPT-4 possesses a significantly superior ability to solve a diverse range of mathematical problems, as indicated by its consistently high accuracy and ability to achieve near-perfect scores on many problem types. LLaMA2-70B provides a more moderate level of performance, while MetaMath-13B struggles to maintain consistent accuracy.
The volatility observed in all three lines suggests that the models' performance is highly sensitive to the specific formulation of the mathematical problem. This could be due to variations in the complexity, ambiguity, or representation of the problems. The Chinese labels on the x-axis indicate that the problems cover a broad spectrum of mathematical topics, from basic geometry to advanced calculus, further highlighting the diversity of the test set.
The significant performance gap between GPT-4 and the other two models suggests that GPT-4 has a more robust and generalizable understanding of mathematical concepts. The erratic behavior of MetaMath-13B may indicate that it is more prone to errors or requires more specialized training data. The data suggests that while large language models are improving in mathematical reasoning, there is still considerable room for improvement, particularly in terms of consistency and robustness.