TECHNICAL ASSET FINGERPRINT
9a5b04b58ddafef3282643cf
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: healer-alpha-free VERSION 1
RUNTIME: free/openrouter/healer-alpha
INTEL_VERIFIED
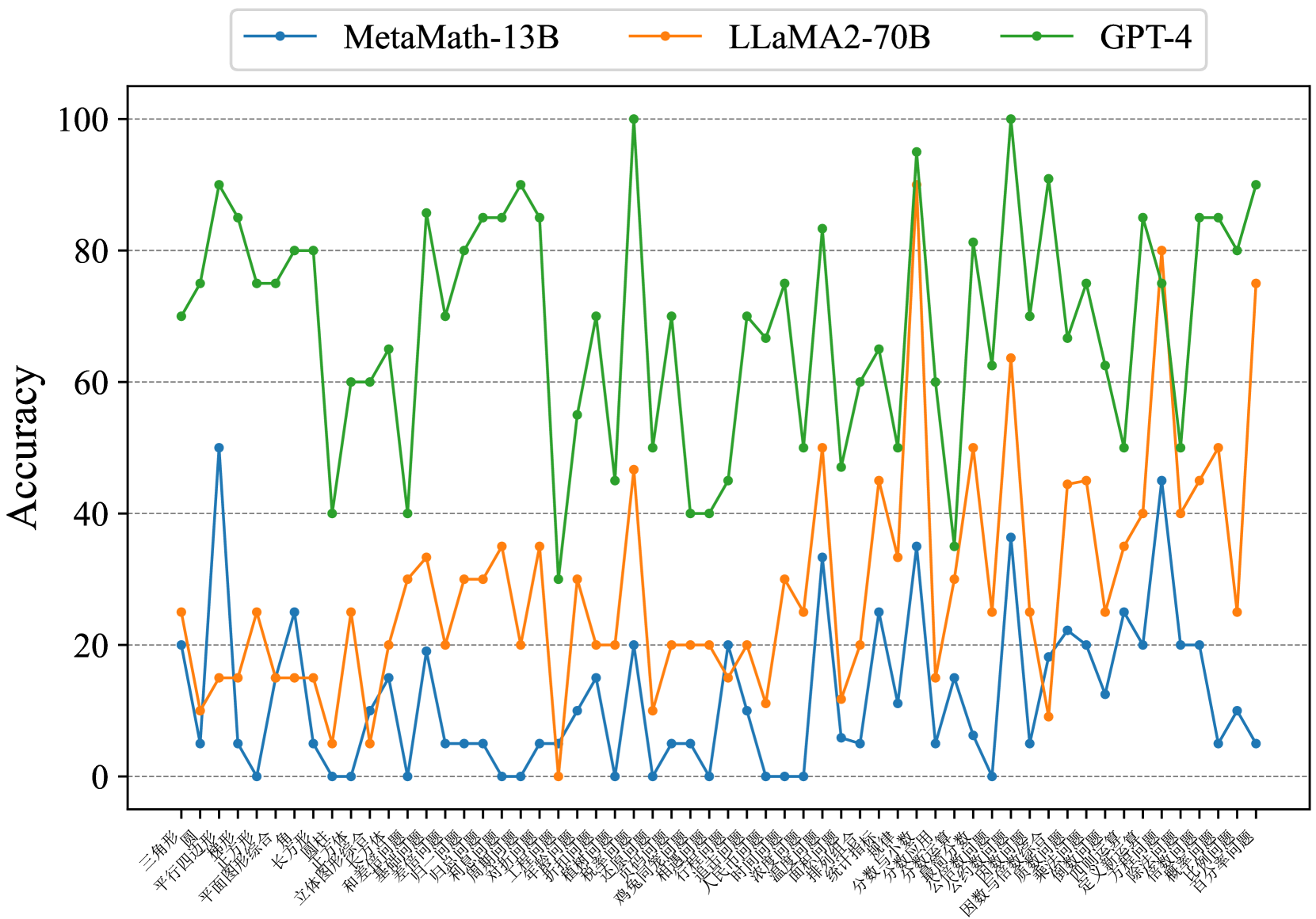
## Line Chart: Accuracy Comparison of Three AI Models Across Math Problem Categories
### Overview
This image is a line chart comparing the accuracy percentages of three large language models (LLMs) across a wide range of Chinese mathematics problem categories. The chart visualizes performance variability, showing that GPT-4 consistently achieves the highest accuracy, followed by LLaMA2-70B, with MetaMath-13B generally performing the lowest. The data is presented as three distinct, jagged lines plotted against a categorical x-axis.
### Components/Axes
* **Chart Type:** Multi-line chart.
* **Y-Axis:**
* **Label:** "Accuracy" (written vertically on the left side).
* **Scale:** Linear scale from 0 to 100, with major gridlines at intervals of 20 (0, 20, 40, 60, 80, 100).
* **X-Axis:**
* **Label:** None explicitly stated. The axis consists of categorical labels for various math problem types.
* **Categories (from left to right, with approximate English translations):**
1. 三角形 (Triangle)
2. 圆 (Circle)
3. 平行四边形 (Parallelogram)
4. 梯形 (Trapezoid)
5. 长方形 (Rectangle)
6. 平面图形综合 (Plane Figure Synthesis)
7. 长方体 (Cuboid)
8. 圆柱 (Cylinder)
9. 圆锥 (Cone)
10. 立体图形综合 (Solid Figure Synthesis)
11. 和差问题 (Sum and Difference Problem)
12. 和倍问题 (Sum and Multiple Problem)
13. 差倍问题 (Difference and Multiple Problem)
14. 植树问题 (Tree Planting Problem)
15. 归一问题 (Unitary Method Problem)
16. 归总问题 (Total Method Problem)
17. 盈亏问题 (Surplus and Deficit Problem)
18. 年龄问题 (Age Problem)
19. 折叠问题 (Folding Problem)
20. 还原问题 (Reversal Problem)
21. 植树问题 (Tree Planting Problem - appears repeated)
22. 鸡兔同笼 (Chicken and Rabbit in the Same Cage)
23. 行程问题 (Travel Problem)
24. 相遇问题 (Meeting Problem)
25. 追及问题 (Pursuit Problem)
26. 时钟问题 (Clock Problem)
27. 浓度问题 (Concentration Problem)
28. 温度问题 (Temperature Problem)
29. 面积问题 (Area Problem)
30. 排列组合 (Permutation and Combination)
31. 统计与概率 (Statistics and Probability)
32. 分数与小数 (Fractions and Decimals)
33. 分数运算 (Fraction Operations)
34. 比和比例 (Ratio and Proportion)
35. 公约数公倍数 (Greatest Common Divisor & Least Common Multiple)
36. 因数与倍数问题 (Factor and Multiple Problem)
37. 质数与合数 (Prime and Composite Numbers)
38. 定义新运算 (New Operation Definition)
39. 除法与除法算式 (Division and Division Expressions)
40. 乘法与乘法算式 (Multiplication and Multiplication Expressions)
41. 等式与方程 (Equality and Equation)
42. 比例问题 (Proportion Problem)
43. 百分率问题 (Percentage Problem)
* **Legend:**
* **Position:** Top center, above the plot area.
* **Items:**
1. **MetaMath-13B:** Blue line with circular markers.
2. **LLaMA2-70B:** Orange line with circular markers.
3. **GPT-4:** Green line with circular markers.
### Detailed Analysis
**Trend Verification & Data Series Analysis:**
1. **GPT-4 (Green Line):**
* **Visual Trend:** The green line is consistently the highest, exhibiting high volatility with sharp peaks and valleys. It frequently reaches or approaches 100% accuracy and rarely drops below 40%.
* **Key Data Points (Approximate):**
* **Peaks (~90-100%):** "圆" (Circle), "和差问题" (Sum and Difference), "植树问题" (Tree Planting), "排列组合" (Permutation and Combination), "分数与小数" (Fractions and Decimals), "比例问题" (Proportion).
* **Notable Lows (~40-50%):** "立体图形综合" (Solid Figure Synthesis), "盈亏问题" (Surplus and Deficit), "时钟问题" (Clock Problem), "质数与合数" (Prime and Composite Numbers).
2. **LLaMA2-70B (Orange Line):**
* **Visual Trend:** The orange line occupies the middle ground, generally between 10% and 50% accuracy, with a few significant spikes. It shows more volatility than MetaMath-13B but less consistent high performance than GPT-4.
* **Key Data Points (Approximate):**
* **Major Spikes:** A very prominent spike to ~90% on "分数与小数" (Fractions and Decimals). Other spikes to ~45-65% on "和差问题" (Sum and Difference), "植树问题" (Tree Planting), "排列组合" (Permutation and Combination), "除法与除法算式" (Division).
* **Typical Range:** Most points cluster between 10% and 35%.
3. **MetaMath-13B (Blue Line):**
* **Visual Trend:** The blue line is consistently the lowest, mostly fluctuating between 0% and 25% accuracy. It has a few moderate peaks but is often near the bottom of the chart.
* **Key Data Points (Approximate):**
* **Highest Points:** ~50% on "平行四边形" (Parallelogram), ~35% on "排列组合" (Permutation and Combination), ~45% on "除法与除法算式" (Division).
* **Frequent Lows:** Hits 0% accuracy on multiple categories, including "梯形" (Trapezoid), "长方体" (Cuboid), "圆锥" (Cone), "归一问题" (Unitary Method), "归总问题" (Total Method), "温度问题" (Temperature Problem), "因数与倍数问题" (Factor and Multiple Problem).
### Key Observations
1. **Clear Performance Hierarchy:** There is a distinct and consistent stratification: GPT-4 > LLaMA2-70B > MetaMath-13B across nearly all categories.
2. **Category-Specific Strengths:** All models show significant performance variation by category. For example, "分数与小数" (Fractions and Decimals) is a relative strength for LLaMA2-70B (its highest point), while "排列组合" (Permutation and Combination) sees strong performance from both GPT-4 and LLaMA2-70B.
3. **High Volatility:** The performance of all models is highly sensitive to the specific type of math problem, as indicated by the jagged, non-smooth lines.
4. **Zero-Performance Categories:** MetaMath-13B scores 0% on several geometry and algebra topics, suggesting complete failure on those specific test sets.
### Interpretation
This chart demonstrates a significant disparity in mathematical reasoning capabilities among the tested LLMs. GPT-4's dominant performance suggests a more robust and generalizable underlying model for mathematical problem-solving across diverse topics. The high volatility for all models indicates that mathematical reasoning is not a monolithic skill; proficiency is highly dependent on the specific problem structure and required operations.
The dramatic spike for LLaMA2-70B on "Fractions and Decimals" is an interesting anomaly. It could indicate that this model was particularly well-trained or fine-tuned on data related to that topic, or that the specific test questions for that category aligned well with its internal representations. Conversely, MetaMath-13B's frequent 0% scores highlight severe limitations or potential alignment issues with certain mathematical concepts.
For a technical document, this data underscores the importance of evaluating AI models on a granular, category-specific basis rather than relying on aggregate scores. It also suggests that while smaller models (like MetaMath-13B) can show competence in specific areas (e.g., basic geometry, division), they lack the broad mathematical understanding exhibited by larger, more advanced models like GPT-4. The results could guide further research into targeted fine-tuning for weaker models or help users select the appropriate model for specific mathematical tasks.
DECODING INTELLIGENCE...