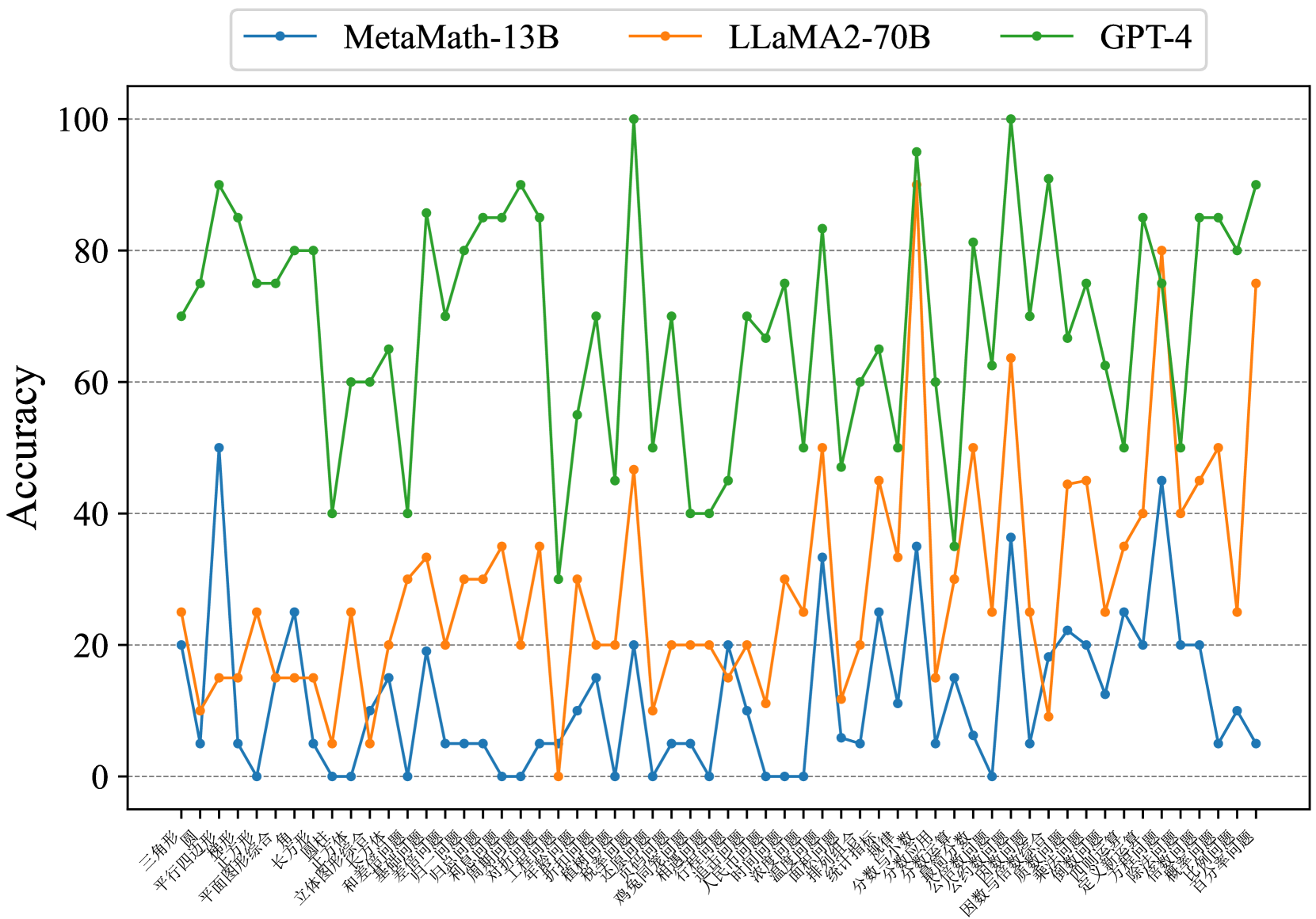
## Line Chart: Model Accuracy Comparison Across Tasks
### Overview
The chart compares the accuracy performance of three AI models (MetaMath-13B, LLaMA2-70B, GPT-4) across multiple tasks represented by Chinese characters on the x-axis. Accuracy is measured on a 0-100 scale on the y-axis. The chart shows significant variability in performance across different tasks for each model.
### Components/Axes
- **Y-axis**: Accuracy (0-100 scale with 20-unit increments)
- **X-axis**: Chinese task labels (e.g., "三角形", "平行四边形", "长方形") - likely representing different mathematical or logical reasoning tasks
- **Legend**:
- Blue line: MetaMath-13B
- Orange line: LLaMA2-70B
- Green line: GPT-4
- **Positioning**: Legend at top-center, data lines spanning full width
### Detailed Analysis
1. **GPT-4 (Green Line)**:
- Consistently highest performer (60-90 range)
- Shows moderate fluctuations but maintains >60 accuracy on all tasks
- Peaks at ~95 for several tasks (e.g., "平行四边形", "长方形")
- Lowest point ~40 for "平面图形综合"
2. **LLaMA2-70B (Orange Line)**:
- Moderate performance (0-80 range)
- High variability with sharp spikes and drops
- Peaks at ~80 for "平行四边形" and "长方形"
- Drops to 0 for "平面图形综合" and "长方形"
3. **MetaMath-13B (Blue Line)**:
- Most erratic performance (0-50 range)
- Sharp spikes to 50 for "平行四边形" and "长方形"
- Frequent drops to 0 for "平面图形综合" and "长方形"
- Only task with >30 accuracy: "平行四边形" (~45)
### Key Observations
- GPT-4 demonstrates superior and more consistent performance across all tasks
- LLaMA2-70B shows moderate capability but significant task-dependent variability
- MetaMath-13B exhibits extreme performance swings, suggesting potential task-specific limitations
- "平面图形综合" task causes all models to drop to 0 accuracy
- "长方形" task shows divergent performance patterns across models
### Interpretation
The data suggests GPT-4 maintains the most reliable performance across diverse mathematical tasks, while LLaMA2-70B and MetaMath-13B show significant task-dependent limitations. The extreme drops to 0 accuracy for certain tasks indicate potential architectural limitations in handling specific problem types. The Chinese task labels (e.g., "三角形" = triangle, "平行四边形" = parallelogram) suggest the models were tested on geometric reasoning problems, with GPT-4 demonstrating superior geometric reasoning capabilities. The performance disparities highlight important considerations for model selection based on task requirements and the need for robustness in mathematical reasoning applications.