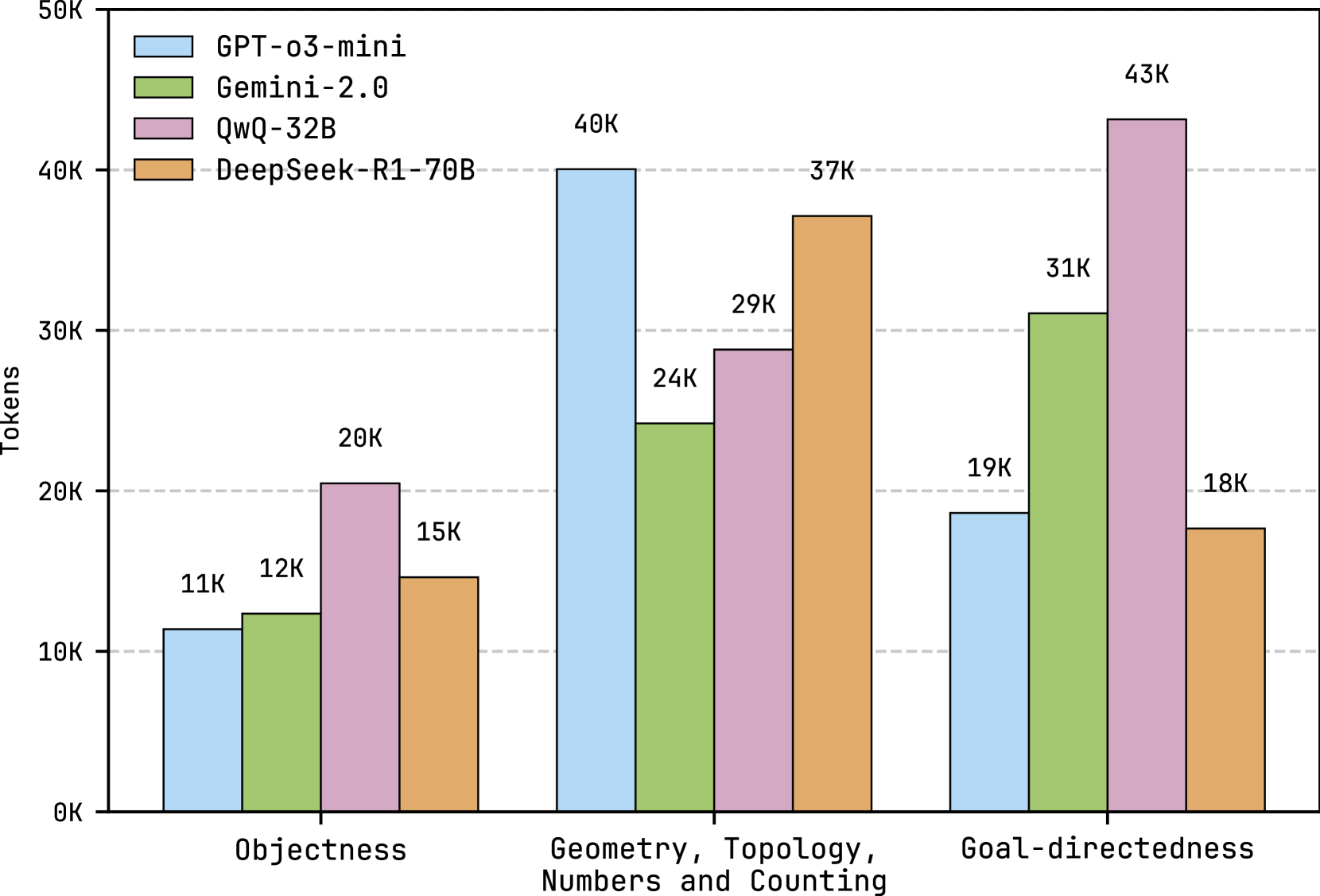
\n
## Bar Chart: Model Performance Across Cognitive Dimensions
### Overview
This bar chart compares the performance of four large language models (GPT-03-mini, Gemini-2.0, QwQ-32B, and DeepSeek-R1-70B) across three cognitive dimensions: Objectness, Geometry/Topology/Numbers/Counting, and Goal-directedness. Performance is measured in tokens.
### Components/Axes
* **X-axis:** Cognitive Dimensions - Objectness, Geometry, Topology, Numbers and Counting, Goal-directedness.
* **Y-axis:** Tokens - Scale ranges from 0K to 50K, with tick marks at 10K intervals.
* **Legend:** Located in the top-left corner.
* Blue: GPT-03-mini
* Green: Gemini-2.0
* Purple: QwQ-32B
* Orange: DeepSeek-R1-70B
### Detailed Analysis
The chart consists of three groups of four bars, one for each model within each cognitive dimension.
**Objectness:**
* GPT-03-mini: Approximately 11K tokens.
* Gemini-2.0: Approximately 12K tokens.
* QwQ-32B: Approximately 20K tokens.
* DeepSeek-R1-70B: Approximately 15K tokens.
**Geometry, Topology, Numbers and Counting:**
* GPT-03-mini: Approximately 24K tokens.
* Gemini-2.0: Approximately 40K tokens.
* QwQ-32B: Approximately 29K tokens.
* DeepSeek-R1-70B: Approximately 37K tokens.
**Goal-directedness:**
* GPT-03-mini: Approximately 19K tokens.
* Gemini-2.0: Approximately 31K tokens.
* QwQ-32B: Approximately 18K tokens.
* DeepSeek-R1-70B: Approximately 43K tokens.
### Key Observations
* DeepSeek-R1-70B consistently demonstrates the highest token count across all three cognitive dimensions.
* Gemini-2.0 performs strongly in Geometry, Topology, Numbers and Counting and Goal-directedness, exceeding the other models in these areas.
* QwQ-32B shows the best performance in Objectness.
* GPT-03-mini consistently exhibits the lowest token counts across all dimensions.
### Interpretation
The data suggests that DeepSeek-R1-70B is the most capable model across these cognitive dimensions, as measured by token count. Gemini-2.0 excels in areas requiring spatial reasoning (Geometry, Topology) and planning (Goal-directedness). QwQ-32B shows a relative strength in recognizing and understanding objects. GPT-03-mini appears to be the least performant model in this comparison.
The use of "tokens" as a metric is interesting. It likely represents the amount of computational effort or the complexity of the model's internal representation when processing information related to each cognitive dimension. Higher token counts could indicate a more detailed or nuanced understanding, or simply a more verbose processing style.
The choice of these three cognitive dimensions – Objectness, Geometry/Topology/Numbers/Counting, and Goal-directedness – suggests an attempt to evaluate the models' abilities in areas crucial for general intelligence. Objectness relates to the ability to identify and categorize objects, Geometry/Topology/Numbers/Counting assesses spatial reasoning and mathematical skills, and Goal-directedness evaluates the capacity for planning and achieving objectives.