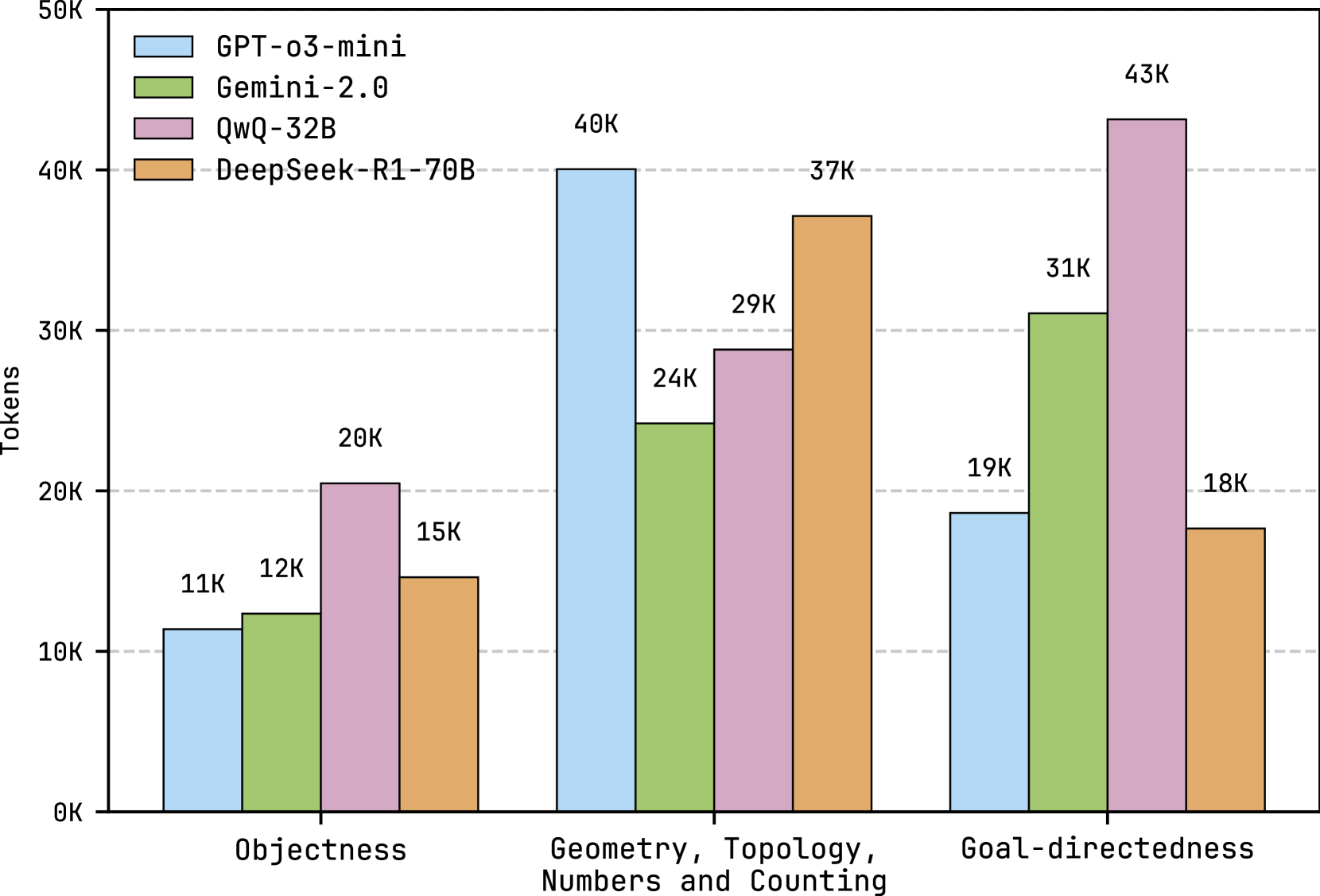
## Grouped Bar Chart: Token Usage by AI Model Across Cognitive Tasks
### Overview
This image is a grouped bar chart comparing the token usage (in thousands) of four different AI models across three distinct cognitive task categories. The chart visually demonstrates how different models allocate computational resources (measured in tokens) when processing tasks related to object recognition, geometric/mathematical reasoning, and goal-directed planning.
### Components/Axes
* **Chart Type:** Grouped vertical bar chart.
* **Y-Axis:** Labeled "Tokens". The scale runs from 0K to 50K, with major gridlines at 10K, 20K, 30K, 40K, and 50K. The "K" denotes thousands.
* **X-Axis:** Represents three distinct task categories:
1. **Objectness** (Left group)
2. **Geometry, Topology, Numbers and Counting** (Center group)
3. **Goal-directedness** (Right group)
* **Legend:** Positioned in the top-left corner of the chart area. It maps colors to four AI models:
* **Light Blue:** GPT-o3-mini
* **Light Green:** Gemini-2.0
* **Pink/Lavender:** QwQ-32B
* **Orange/Tan:** DeepSeek-R1-70B
* **Data Labels:** Each bar has a numerical label at its top indicating the exact token count (e.g., "11K", "40K").
### Detailed Analysis
The chart presents the following specific data points, verified by cross-referencing bar color with the legend:
**1. Objectness Task Category (Left Group):**
* **GPT-o3-mini (Light Blue):** 11K tokens. This is the lowest value in this category.
* **Gemini-2.0 (Light Green):** 12K tokens.
* **QwQ-32B (Pink):** 20K tokens. This is the highest value in this category.
* **DeepSeek-R1-70B (Orange):** 15K tokens.
* **Trend:** Token usage is relatively low across all models for this task, with QwQ-32B using nearly double the tokens of GPT-o3-mini.
**2. Geometry, Topology, Numbers and Counting Task Category (Center Group):**
* **GPT-o3-mini (Light Blue):** 40K tokens. This is the highest value in this category.
* **Gemini-2.0 (Light Green):** 24K tokens.
* **QwQ-32B (Pink):** 29K tokens.
* **DeepSeek-R1-70B (Orange):** 37K tokens.
* **Trend:** This category shows the highest overall token consumption. GPT-o3-mini and DeepSeek-R1-70B show significantly higher usage than the other two models.
**3. Goal-directedness Task Category (Right Group):**
* **GPT-o3-mini (Light Blue):** 19K tokens.
* **Gemini-2.0 (Light Green):** 31K tokens.
* **QwQ-32B (Pink):** 43K tokens. This is the highest single value in the entire chart.
* **DeepSeek-R1-70B (Orange):** 18K tokens. This is the lowest value in this category.
* **Trend:** This category shows the greatest variance between models. QwQ-32B's token usage is exceptionally high, while GPT-o3-mini and DeepSeek-R1-70B are comparatively low.
### Key Observations
1. **Model-Specific Patterns:**
* **QwQ-32B (Pink)** consistently uses a high number of tokens, leading in two categories ("Objectness" and "Goal-directedness") and peaking at 43K.
* **GPT-o3-mini (Light Blue)** shows extreme variability: it is the most efficient (lowest tokens) for "Objectness" and "Goal-directedness" but the most resource-intensive for "Geometry...".
* **DeepSeek-R1-70B (Orange)** is the second-highest user for "Geometry..." (37K) but the lowest for "Goal-directedness" (18K).
* **Gemini-2.0 (Light Green)** shows moderate, middle-of-the-pack usage across all tasks.
2. **Task Complexity Implication:** The "Geometry, Topology, Numbers and Counting" category elicits the highest average token usage from the models, suggesting it may be the most computationally demanding task type among the three.
3. **Notable Outlier:** The 43K token usage by QwQ-32B for "Goal-directedness" is a significant outlier, being 12K tokens higher than the next highest value in that category (Gemini-2.0 at 31K) and more than double the usage of two other models.
### Interpretation
This chart provides a comparative analysis of computational cost (token usage) for different AI models on specific cognitive benchmarks. The data suggests that:
* **Task-Dependent Efficiency:** No single model is the most token-efficient across all task types. Model performance in terms of resource usage is highly dependent on the nature of the problem. A model efficient at object recognition may be inefficient at geometric reasoning.
* **Potential Correlation with Model Size/Architecture:** The model names hint at different scales (e.g., "32B", "70B" parameters). The high token usage of QwQ-32B and DeepSeek-R1-70B on certain tasks could correlate with larger model sizes engaging in more extensive internal reasoning chains, though this is an inference beyond the explicit data.
* **Benchmarking Insight:** For researchers or engineers, this data is crucial for understanding the operational costs of deploying these models. Choosing a model for a "Goal-directedness" task would involve a trade-off: QwQ-32B might offer higher capability (implied by its high token usage, suggesting deeper processing) at a much higher computational cost than GPT-o3-mini or DeepSeek-R1-70B.
* **The "Geometry..." Task as a Differentiator:** This category acts as a strong differentiator, separating models into high-usage (GPT-o3-mini, DeepSeek-R1-70B) and moderate-usage (Gemini-2.0, QwQ-32B) groups, which may reflect different underlying approaches to mathematical and spatial reasoning.
In essence, the chart moves beyond simple accuracy scores to reveal the hidden "cost" of AI reasoning in terms of token consumption, highlighting that model selection must consider both performance and efficiency for specific application domains.