## Line Chart: Accuracy Comparison Across Training Epochs
### Overview
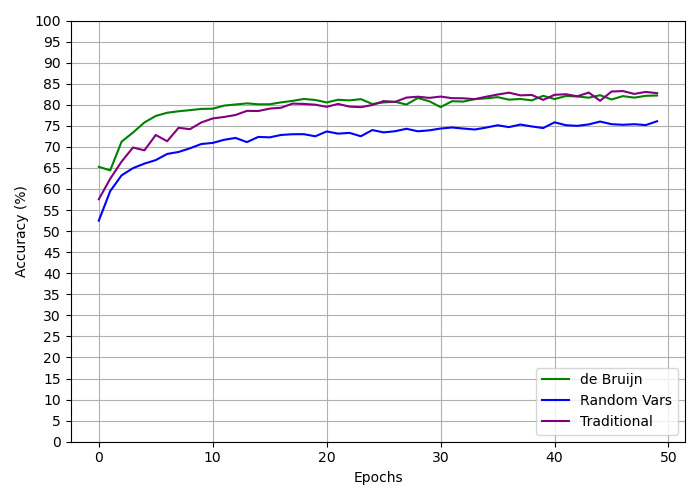
The image is a line chart comparing the accuracy performance of three methods ("de Bruijn," "Random Vars," and "Traditional") over 50 training epochs. Accuracy is measured on the y-axis (0–100%), and epochs are plotted on the x-axis (0–50). All three methods show upward trends, with "de Bruijn" and "Traditional" achieving higher final accuracy than "Random Vars."
### Components/Axes
- **Y-Axis**: Labeled "Accuracy (%)" with gridlines at 5% intervals (0–100).
- **X-Axis**: Labeled "Epochs" with gridlines at 10-epoch intervals (0–50).
- **Legend**: Located in the bottom-right corner, with three entries:
- **Green**: "de Bruijn"
- **Blue**: "Random Vars"
- **Purple**: "Traditional"
### Detailed Analysis
1. **de Bruijn (Green Line)**:
- Starts at ~65% accuracy at epoch 0.
- Rises sharply to ~80% by epoch 10.
- Stabilizes with minor fluctuations (~80–85%) from epoch 20 onward.
- Final accuracy at epoch 50: ~82% (approximate).
2. **Random Vars (Blue Line)**:
- Starts at ~50% accuracy at epoch 0.
- Gradually increases to ~75% by epoch 20.
- Plateaus with minor noise (~75–78%) from epoch 30 onward.
- Final accuracy at epoch 50: ~77% (approximate).
3. **Traditional (Purple Line)**:
- Starts at ~55% accuracy at epoch 0.
- Increases steadily to ~80% by epoch 30.
- Stabilizes with minor oscillations (~80–83%) from epoch 40 onward.
- Final accuracy at epoch 50: ~82% (approximate).
### Key Observations
- **de Bruijn** achieves the highest final accuracy (~82%) and converges faster than the other methods.
- **Traditional** matches de Bruijn’s final accuracy but takes longer to stabilize.
- **Random Vars** underperforms, plateauing at ~77% accuracy.
- All methods show diminishing returns after ~20–30 epochs.
### Interpretation
The data suggests that **de Bruijn** and **Traditional** methods are more effective at improving accuracy over epochs compared to **Random Vars**, which exhibits a lower learning capacity. The convergence of de Bruijn and Traditional toward similar accuracy levels implies that both methods may share underlying strengths, while Random Vars’ randomness limits its performance ceiling. The initial dip in de Bruijn’s line (epoch 0–5) could indicate an adjustment phase or noise in early training. The plateauing trends across all methods suggest that further epochs yield minimal gains, highlighting potential optimization opportunities for all approaches.