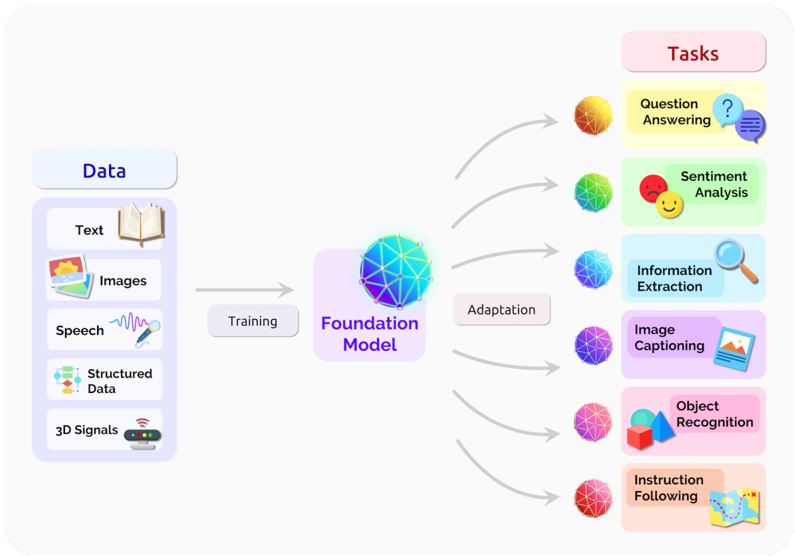
## Diagram: Foundation Model Training and Adaptation Pipeline
### Overview
The image is a conceptual diagram illustrating the workflow of a foundation model in artificial intelligence. It depicts a pipeline where diverse data types are used to train a central foundation model, which is then adapted to perform a variety of specific downstream tasks. The flow moves from left to right.
### Components/Axes
The diagram is organized into three main vertical sections:
1. **Left Section: Data**
* **Header:** A light blue rounded rectangle labeled "Data".
* **Content:** A vertical list of five data types, each with an icon and a label:
* **Text:** Icon of an open book.
* **Images:** Icon of a landscape photograph.
* **Speech:** Icon of a sound wave.
* **Structured Data:** Icon of a flowchart or organizational chart.
* **3D Signals:** Icon of a sensor device emitting waves.
* **Flow:** A gray arrow labeled "Training" points from this section to the central "Foundation Model".
2. **Center Section: Foundation Model**
* **Header:** A light purple rounded rectangle labeled "Foundation Model".
* **Content:** A large, colorful, geometric sphere composed of interconnected triangles in shades of blue, green, and purple. This represents the trained model.
* **Flow:** A gray arrow labeled "Adaptation" points from this section to the right-hand "Tasks" section.
3. **Right Section: Tasks**
* **Header:** A light pink rounded rectangle labeled "Tasks".
* **Content:** A vertical list of six task types. Each task is represented by a smaller, uniquely colored geometric sphere (matching the style of the central model) and a labeled box with an associated icon.
* **Question Answering:** Yellow sphere. Yellow box with a question mark and speech bubble icon.
* **Sentiment Analysis:** Green sphere. Green box with a happy/sad face icon.
* **Information Extraction:** Blue sphere. Blue box with a magnifying glass icon.
* **Image Captioning:** Purple sphere. Purple box with a landscape photo icon.
* **Object Recognition:** Pink sphere. Pink box with geometric shape icons (cube, sphere, pyramid).
* **Instruction Following:** Red sphere. Red box with a map and compass icon.
### Detailed Analysis
The diagram explicitly defines a two-stage process:
1. **Training Stage:** A foundation model is created by training on a broad, multimodal dataset comprising text, images, speech, structured data, and 3D signals.
2. **Adaptation Stage:** The single, general-purpose foundation model is then specialized or adapted to perform distinct, focused tasks. The visual metaphor shows the large central model "branching out" into smaller, task-specific versions (the colored spheres).
### Key Observations
* **Multimodality:** The input data is explicitly multimodal, covering language, vision, audio, and structured information.
* **One-to-Many Relationship:** A single foundation model serves as the basis for multiple, diverse applications.
* **Visual Consistency:** The geometric sphere motif is used for both the central model and the task-specific models, visually reinforcing that the tasks are derivatives or specializations of the core model.
* **Color Coding:** Each task on the right is assigned a unique color (yellow, green, blue, purple, pink, red), which is consistently applied to its sphere, label box, and icon background.
### Interpretation
This diagram illustrates the core paradigm of modern AI development centered around foundation models. It argues that the most efficient path to building capable AI systems is not to create separate models for each task from scratch. Instead, the process involves:
1. **Consolidation:** Investing resources to train a single, large, generalist model on a vast and varied dataset. This model learns broad representations and capabilities.
2. **Specialization:** Efficiently adapting this generalist model to specific applications (like sentiment analysis or object recognition) through techniques like fine-tuning or prompt engineering.
The pipeline suggests efficiency, scalability, and knowledge transfer. The foundation model acts as a repository of general knowledge and reasoning patterns, which can be quickly molded for specific purposes, reducing the data and compute needed for each individual task compared to training specialized models in isolation. The inclusion of "3D Signals" and "Instruction Following" points to an ambition for models that understand the physical world and can follow complex human directives.