TECHNICAL ASSET FINGERPRINT
9ac6425bba1a5395b6d342a6
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: gemini-2.0-flash VERSION 1
RUNTIME: nugit/gemini/gemini-2.0-flash
INTEL_VERIFIED
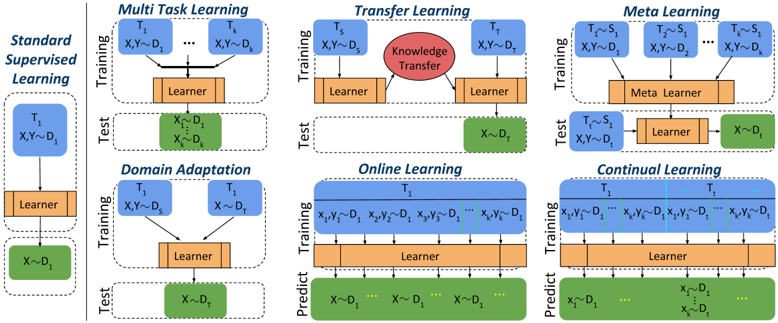
## Diagram: Comparison of Machine Learning Paradigms
### Overview
The image presents a comparative diagram illustrating different machine learning paradigms: Standard Supervised Learning, Multi-Task Learning, Domain Adaptation, Transfer Learning, Online Learning, Meta Learning, and Continual Learning. Each paradigm is depicted with a simplified flow diagram showing the training and testing/prediction phases, highlighting the data used in each phase and the role of the learner.
### Components/Axes
Each paradigm is represented by a diagram consisting of the following components:
* **Training Phase:** Represented by a blue rounded rectangle labeled "Training". Inside, the data used for training is specified in the format "T<sub>i</sub>, X, Y ~ D<sub>i</sub>", where T represents the task, X represents the input data, Y represents the labels, and D represents the data distribution.
* **Learner:** Represented by an orange rectangle labeled "Learner" or "Meta Learner". This represents the model being trained.
* **Testing/Prediction Phase:** Represented by a green rounded rectangle labeled "Test" or "Predict". Inside, the data used for testing/prediction is specified in the format "X ~ D<sub>i</sub>", where X represents the input data and D represents the data distribution.
* **Arrows:** Arrows indicate the flow of data and the learning process.
* **Knowledge Transfer (Transfer Learning):** Represented by a red circle with the text "Knowledge Transfer" inside.
### Detailed Analysis
**1. Standard Supervised Learning:**
* **Training:** T<sub>1</sub>, X, Y ~ D<sub>1</sub>
* **Process:** Data flows from the training set to the learner.
* **Testing:** X ~ D<sub>1</sub>
* **Process:** Trained learner is used to predict on data from the same distribution.
**2. Multi-Task Learning:**
* **Training:** T<sub>1</sub>, X, Y ~ D<sub>1</sub> ... T<sub>k</sub>, X, Y ~ D<sub>k</sub>
* **Process:** Multiple tasks are learned simultaneously by a single learner.
* **Testing:** X<sub>1</sub> ~ D<sub>1</sub> ... X<sub>k</sub> ~ D<sub>k</sub>
* **Process:** The trained learner is tested on data from each of the learned distributions.
**3. Domain Adaptation:**
* **Training:** T<sub>1</sub>, X, Y ~ D<sub>S</sub> and T<sub>1</sub>, X ~ D<sub>T</sub>
* **Process:** The learner is trained on data from a source domain (D<sub>S</sub>) and a target domain (D<sub>T</sub>).
* **Testing:** X ~ D<sub>T</sub>
* **Process:** The trained learner is tested on data from the target domain.
**4. Transfer Learning:**
* **Training:** T<sub>S</sub>, X, Y ~ D<sub>S</sub>
* **Process:** The learner is trained on data from a source domain (D<sub>S</sub>).
* **Knowledge Transfer:** Knowledge is transferred from the source domain to the target domain.
* **Training:** T<sub>T</sub>, X, Y ~ D<sub>T</sub>
* **Process:** The learner is further trained on data from the target domain (D<sub>T</sub>).
* **Testing:** X ~ D<sub>T</sub>
* **Process:** The trained learner is tested on data from the target domain.
**5. Online Learning:**
* **Training:** T<sub>1</sub>, x<sub>1</sub>, y<sub>1</sub> ~ D<sub>1</sub>, x<sub>2</sub>, y<sub>2</sub> ~ D<sub>1</sub>, x<sub>3</sub>, y<sub>3</sub> ~ D<sub>1</sub> ... x<sub>k</sub>, y<sub>k</sub> ~ D<sub>1</sub>
* **Process:** The learner is trained sequentially on data points.
* **Prediction:** X ~ D<sub>1</sub> ... X ~ D<sub>1</sub> ...
* **Process:** The trained learner is used to predict on data from the same distribution.
**6. Meta Learning:**
* **Training:** T<sub>1</sub> ~ S<sub>1</sub>, X, Y ~ D<sub>1</sub>, T<sub>2</sub> ~ S<sub>1</sub>, X, Y ~ D<sub>2</sub> ... T<sub>k</sub> ~ S<sub>1</sub>, X, Y ~ D<sub>k</sub>
* **Process:** A meta-learner learns from a distribution of tasks.
* **Testing:** T ~ S<sub>1</sub>, X, Y ~ D<sub>t</sub>
* **Process:** The meta-learner is tested on a new task from the same distribution.
* **Learner:** A learner is trained on the new task.
* **Testing:** X ~ D<sub>t</sub>
* **Process:** The trained learner is tested on data from the new task's distribution.
**7. Continual Learning:**
* **Training:** T<sub>1</sub>, x<sub>1</sub>, y<sub>1</sub> ~ D<sub>1</sub> ... x<sub>k</sub>, y<sub>k</sub> ~ D<sub>1</sub>, T<sub>t</sub>, x<sub>1</sub>, y<sub>1</sub> ~ D<sub>1</sub> ... x<sub>k</sub>, y<sub>k</sub> ~ D<sub>1</sub>
* **Process:** The learner is trained sequentially on data points from different tasks.
* **Prediction:** X ~ D<sub>1</sub> ... X ~ D<sub>1</sub> ...
* **Process:** The trained learner is used to predict on data from the same distribution.
### Key Observations
* **Data Distribution:** The diagrams highlight the importance of data distribution (D) in different learning paradigms. Standard supervised learning assumes the training and testing data come from the same distribution. Domain adaptation and transfer learning deal with different distributions.
* **Task Variation:** Multi-task learning and meta-learning involve multiple tasks (T), while standard supervised learning focuses on a single task.
* **Learning Process:** The diagrams illustrate the different learning processes involved in each paradigm, such as simultaneous learning (multi-task), knowledge transfer (transfer learning), and sequential learning (online and continual learning).
### Interpretation
The diagram provides a high-level overview of different machine learning paradigms and their key characteristics. It emphasizes the importance of data distribution, task variation, and the learning process in each paradigm. The diagrams are useful for understanding the differences between these paradigms and for choosing the appropriate paradigm for a given problem.
* **Standard Supervised Learning:** Serves as the baseline, where the model learns from labeled data and is tested on data from the same distribution.
* **Multi-Task Learning:** Improves generalization by learning multiple related tasks simultaneously.
* **Domain Adaptation:** Addresses the problem of distribution shift between training and testing data.
* **Transfer Learning:** Leverages knowledge gained from a source domain to improve learning in a target domain.
* **Online Learning:** Adapts to new data as it becomes available, making it suitable for dynamic environments.
* **Meta Learning:** Learns how to learn, enabling fast adaptation to new tasks.
* **Continual Learning:** Learns new tasks without forgetting previously learned ones.
DECODING INTELLIGENCE...
EXPERT: gemini-3.1-flash-lite-preview-free VERSION 1
RUNTIME: google-free/gemini-3.1-flash-lite-preview
INTEL_VERIFIED
## Diagram: Comparison of Machine Learning Paradigms
### Overview
This image is a comparative diagram illustrating seven distinct machine learning paradigms. It uses a consistent visual language to represent data inputs, model training, and testing/prediction phases. The diagram serves as a taxonomy, showing how different paradigms handle data distributions ($D$), tasks ($T$), and knowledge transfer.
### Components/Axes
The diagram uses a standardized color-coded system:
* **Blue Boxes:** Represent input data, tasks, and distributions ($T$, $X, Y \sim D$).
* **Orange Boxes:** Represent the "Learner" or "Meta Learner" (the model).
* **Green Boxes:** Represent the "Test" or "Predict" phase outputs.
* **Red Oval:** Represents "Knowledge Transfer" (specific to Transfer Learning).
* **Dashed Boxes:** Grouping elements into "Training" and "Test/Predict" phases.
* **Arrows:** Indicate the direction of data flow and influence.
### Detailed Analysis
#### 1. Standard Supervised Learning (Far Left)
* **Training:** A single blue box ($T_1, X, Y \sim D_1$) feeds into an orange "Learner" box.
* **Test:** The Learner feeds into a green box ($X \sim D_1$).
* **Trend:** Linear, single-task flow.
#### 2. Multi Task Learning (Top Left of Grid)
* **Training:** Multiple blue boxes ($T_1, X, Y \sim D_1$ through $T_k, X, Y \sim D_k$) feed into a single orange "Learner" box.
* **Test:** The Learner feeds into a green box containing multiple outputs ($X_1 \sim D_1$ ... $X_k \sim D_k$).
* **Trend:** Many-to-one training, one-to-many testing.
#### 3. Transfer Learning (Top Middle of Grid)
* **Training:** Two distinct blue boxes ($T_S, X, Y \sim D_S$ and $T_T, X, Y \sim D_T$). The first feeds into a Learner. A red oval labeled "Knowledge Transfer" connects the first Learner to a second Learner, which also receives input from the second blue box.
* **Test:** The second Learner feeds into a green box ($X \sim D_T$).
* **Trend:** Sequential dependency where knowledge from a source task ($S$) informs the target task ($T$).
#### 4. Meta Learning (Top Right of Grid)
* **Training:** Multiple blue boxes ($T_1 \sim S_1$ through $T_k \sim S_1$) feed into an orange "Meta Learner" box.
* **Test:** The Meta Learner feeds into a second orange "Learner" box. This Learner also receives input ($T_t, X, Y \sim D_t$) and outputs to a green box ($X \sim D_t$).
* **Trend:** Hierarchical; the Meta Learner trains the Learner.
#### 5. Domain Adaptation (Bottom Left of Grid)
* **Training:** Two blue boxes ($T_1, X, Y \sim D_S$ and $T_1, X \sim D_T$) feed into a single orange "Learner" box.
* **Test:** The Learner feeds into a green box ($X \sim D_T$).
* **Trend:** Merging source and target domains to solve a single task.
#### 6. Online Learning (Bottom Middle of Grid)
* **Training:** A large blue block ($T_1$) containing a sequence of data ($x_1, y_1 \sim D_1$ ... $x_k, y_k \sim D_1$) feeds into a single orange "Learner" box.
* **Predict:** The Learner feeds into a green box ($X \sim D_1$ ... $X \sim D_1$).
* **Trend:** Sequential, continuous data stream processing.
#### 7. Continual Learning (Bottom Right of Grid)
* **Training:** A large blue block ($T_1$ ... $T_t$) containing a sequence of data ($x_1, y_1 \sim D_1$ ... $x_k, y_k \sim D_t$) feeds into a single orange "Learner" box.
* **Predict:** The Learner feeds into a green box ($x_1 \sim D_1$ ... $x_k \sim D_t$).
* **Trend:** Sequential data processing across changing distributions/tasks over time.
### Key Observations
* **Learner Centrality:** The "Learner" (orange box) is the constant component across all paradigms, acting as the processing engine.
* **Data Distribution Evolution:** The notation $D_1$ vs $D_S/D_T$ highlights the shift from static environments (Standard) to environments where the source and target distributions differ (Transfer/Domain Adaptation).
* **Sequential vs. Parallel:** Online and Continual learning are visually distinct from the others by using a wide, continuous blue block to represent the temporal nature of the data stream.
### Interpretation
This diagram provides a high-level conceptual map of how machine learning models are structured based on their learning objectives.
* **Standard Supervised Learning** is the baseline, assuming a static, single-task environment.
* **Multi-Task and Meta Learning** expand the scope of the training phase to handle multiple tasks simultaneously or learn *how* to learn.
* **Transfer Learning and Domain Adaptation** address the problem of distribution shift, where the training data (source) does not perfectly match the testing data (target).
* **Online and Continual Learning** address the temporal dimension, where data arrives sequentially, and the model must adapt without forgetting previous information (a key challenge in Continual Learning).
The diagram effectively demonstrates the progression of complexity in modern AI, moving from isolated, static problems to integrated, dynamic, and adaptive systems.
DECODING INTELLIGENCE...
EXPERT: nemotron-free VERSION 1
RUNTIME: free/nvidia/nemotron-nano-12b-v2-vl:free
INTEL_VERIFIED
## Diagram: Machine Learning Paradigms Comparison
### Overview
The diagram illustrates six machine learning paradigms (Standard Supervised Learning, Domain Adaptation, Online Learning, Multi-Task Learning, Transfer Learning, and Meta Learning) through a structured layout of training, test, and learner components. Arrows indicate data flow, knowledge transfer, and task relationships.
### Components/Axes
- **Left Column**:
- **Standard Supervised Learning**: Single task `T₁` with training data `X,Y ~ D₁` and test data `X ~ D₁`.
- **Domain Adaptation**: Training on `T₁` with source domain `X,Y ~ Dₛ` and target domain `X ~ Dₜ`.
- **Online Learning**: Continuous training on `T₁` with sequential data `X₁,Y₁ ~ D₁` to `Xₖ,Yₖ ~ D₁`, predicting `X ~ D₁`.
- **Right Column**:
- **Multi-Task Learning**: Shared learner for tasks `T₁` to `Tₖ` with data `X,Y ~ D₁` to `X,Y ~ Dₖ`.
- **Transfer Learning**: Knowledge transfer (red oval) from source task `Tₛ` (`X,Y ~ Dₛ`) to target task `Tₜ` (`X,Y ~ Dₜ`).
- **Meta Learning**: Meta learner handling tasks `T₁` to `Tₖ` with shared structure `X,Y ~ D₁` to `X,Y ~ Dₖ`, testing on `X ~ Dₜ`.
- **Color Coding**:
- Blue: Training data (`X,Y ~ D`).
- Green: Test data (`X ~ D`).
- Orange: Learner component.
- Red: Knowledge transfer (Transfer Learning only).
### Detailed Analysis
1. **Standard Supervised Learning**:
- Simple pipeline: Training (`T₁`) → Learner → Test (`X ~ D₁`).
- No adaptation or transfer; assumes static, task-specific data.
2. **Domain Adaptation**:
- Addresses domain shift: Training on source domain `Dₛ` → Learner → Test on target domain `Dₜ`.
3. **Online Learning**:
- Sequential data ingestion: `X₁,Y₁ ~ D₁` to `Xₖ,Yₖ ~ D₁` → Learner → Predictions on `X ~ D₁`.
- Emphasizes real-time adaptation to streaming data.
4. **Multi-Task Learning**:
- Shared learner across tasks `T₁` to `Tₖ` with distinct datasets `D₁` to `Dₖ`.
- Leverages cross-task knowledge for improved generalization.
5. **Transfer Learning**:
- Explicit knowledge transfer (red oval) from source task `Tₛ` to target task `Tₜ`.
- Source task `Tₛ` trains on `Dₛ`; target task `Tₜ` tests on `Dₜ`.
6. **Meta Learning**:
- Meta learner generalizes across tasks `T₁` to `Tₖ` with shared structure.
- Tests on unseen task `Tₜ` with data `X ~ Dₜ`.
### Key Observations
- **Hierarchy of Complexity**: Paradigms progress from simple (Standard Supervised) to complex (Meta Learning).
- **Knowledge Reuse**: Transfer Learning and Meta Learning explicitly model knowledge reuse across tasks/domains.
- **Dynamic Data Handling**: Online Learning and Domain Adaptation address non-stationary or domain-shifted data.
- **Shared Learners**: Multi-Task and Meta Learning use shared architectures for efficiency.
### Interpretation
The diagram highlights the evolution of machine learning from task-specific models to adaptive, generalizable frameworks. Transfer Learning and Meta Learning emphasize leveraging prior knowledge, while Domain Adaptation and Online Learning focus on real-world data challenges. The red "Knowledge Transfer" oval in Transfer Learning underscores its role as a bridge between source and target tasks. Meta Learning’s "Meta Learner" abstracts task-specific patterns, enabling rapid adaptation to new tasks. This progression reflects the field’s shift toward robustness, efficiency, and scalability in dynamic environments.
DECODING INTELLIGENCE...