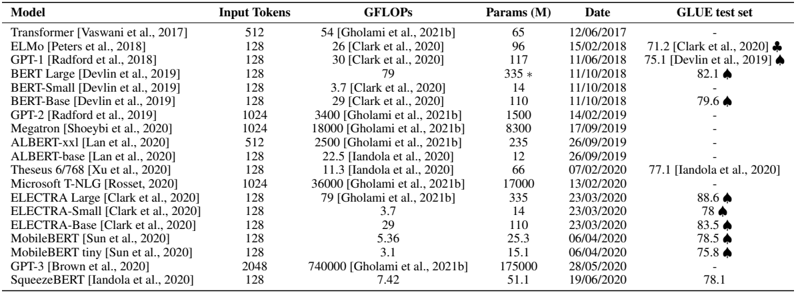
## Data Table: Model Performance Metrics
### Overview
The image presents a data table comparing the performance metrics of various language models. The table includes information on the model name, input tokens, GFLOPs, number of parameters, date, and GLUE test set performance.
### Components/Axes
The table has the following columns:
* **Model**: Name of the language model, along with the publication reference.
* **Input Tokens**: Number of input tokens used by the model.
* **GFLOPs**: Giga Floating Point Operations per second, a measure of computational cost.
* **Params (M)**: Number of parameters in millions.
* **Date**: Date of the model's publication or evaluation.
* **GLUE test set**: Performance on the GLUE (General Language Understanding Evaluation) benchmark.
### Detailed Analysis or ### Content Details
Here's a breakdown of the data for each model:
* **Transformer [Vaswani et al., 2017]**: Input Tokens: 512, GFLOPs: 54 [Gholami et al., 2021b], Params (M): 65, Date: 12/06/2017, GLUE test set: -
* **ELMo [Peters et al., 2018]**: Input Tokens: 128, GFLOPs: 26 [Clark et al., 2020], Params (M): 96, Date: 15/02/2018, GLUE test set: 71.2 [Clark et al., 2020]
* **GPT-1 [Radford et al., 2018]**: Input Tokens: 128, GFLOPs: 30 [Clark et al., 2020], Params (M): 117, Date: 11/06/2018, GLUE test set: 75.1 [Devlin et al., 2019]
* **BERT Large [Devlin et al., 2019]**: Input Tokens: 128, GFLOPs: 79, Params (M): 335 *, Date: 11/10/2018, GLUE test set: 82.1
* **BERT-Small [Devlin et al., 2019]**: Input Tokens: 128, GFLOPs: 3.7 [Clark et al., 2020], Params (M): 14, Date: 11/10/2018, GLUE test set: -
* **BERT-Base [Devlin et al., 2019]**: Input Tokens: 128, GFLOPs: 29 [Clark et al., 2020], Params (M): 110, Date: 11/10/2018, GLUE test set: 79.6
* **GPT-2 [Radford et al., 2019]**: Input Tokens: 1024, GFLOPs: 3400 [Gholami et al., 2021b], Params (M): 1500, Date: 14/02/2019, GLUE test set: -
* **Megatron [Shoeybi et al., 2020]**: Input Tokens: 1024, GFLOPs: 18000 [Gholami et al., 2021b], Params (M): 8300, Date: 17/09/2019, GLUE test set: -
* **ALBERT-xxl [Lan et al., 2020]**: Input Tokens: 512, GFLOPs: 2500 [Gholami et al., 2021b], Params (M): 235, Date: 26/09/2019, GLUE test set: -
* **ALBERT-base [Lan et al., 2020]**: Input Tokens: 128, GFLOPs: 22.5 [Iandola et al., 2020], Params (M): 12, Date: 26/09/2019, GLUE test set: -
* **Theseus 6/768 [Xu et al., 2020]**: Input Tokens: 128, GFLOPs: 11.3 [Iandola et al., 2020], Params (M): 66, Date: 07/02/2020, GLUE test set: 77.1 [Iandola et al., 2020]
* **Microsoft T-NLG [Rosset, 2020]**: Input Tokens: 1024, GFLOPs: 36000 [Gholami et al., 2021b], Params (M): 17000, Date: 13/02/2020, GLUE test set: -
* **ELECTRA Large [Clark et al., 2020]**: Input Tokens: 128, GFLOPs: 79 [Gholami et al., 2021b], Params (M): 335, Date: 23/03/2020, GLUE test set: 88.6
* **ELECTRA-Small [Clark et al., 2020]**: Input Tokens: 128, GFLOPs: 3.7, Params (M): 14, Date: 23/03/2020, GLUE test set: 78
* **ELECTRA-Base [Clark et al., 2020]**: Input Tokens: 128, GFLOPs: 29, Params (M): 110, Date: 23/03/2020, GLUE test set: 83.5
* **MobileBERT [Sun et al., 2020]**: Input Tokens: 128, GFLOPs: 5.36, Params (M): 25.3, Date: 06/04/2020, GLUE test set: 78.5
* **MobileBERT tiny [Sun et al., 2020]**: Input Tokens: 128, GFLOPs: 3.1, Params (M): 15.1, Date: 06/04/2020, GLUE test set: 75.8
* **GPT-3 [Brown et al., 2020]**: Input Tokens: 2048, GFLOPs: 740000 [Gholami et al., 2021b], Params (M): 175000, Date: 28/05/2020, GLUE test set: -
* **SqueezeBERT [Iandola et al., 2020]**: Input Tokens: 128, GFLOPs: 7.42, Params (M): 51.1, Date: 19/06/2020, GLUE test set: 78.1
### Key Observations
* GPT-3 has significantly higher GFLOPs and parameters compared to other models.
* The GLUE test set performance varies across different models.
* The table includes models published between 2017 and 2020.
### Interpretation
The data table provides a snapshot of the landscape of language models, highlighting the trade-offs between model size (parameters), computational cost (GFLOPs), and performance on a specific benchmark (GLUE). The evolution of models is evident, with newer models like GPT-3 having substantially larger sizes and computational requirements. The GLUE test set results offer a way to compare the models' general language understanding capabilities, although it's important to note that this is just one metric and may not fully capture the nuances of each model's performance. The absence of GLUE test set scores for some models suggests that these models may not have been evaluated on this particular benchmark or that the results were not available at the time of publication. The asterisk next to the parameter count for BERT Large suggests a possible annotation or caveat regarding that specific value.