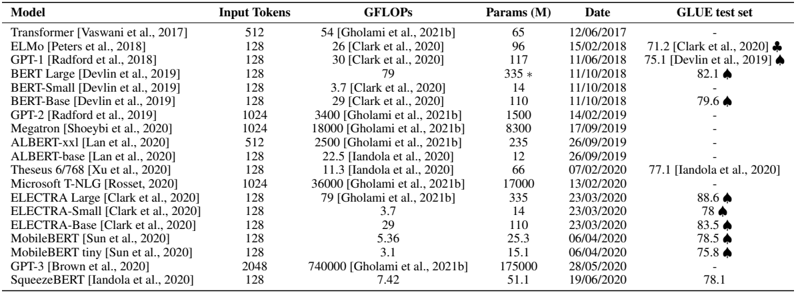
## Table: Comparison of Transformer-Based Language Models
### Overview
The image displays a technical comparison table of various transformer-based language models, detailing their computational requirements, size, release dates, and performance on the GLUE benchmark. The table is structured with six columns and includes 17 distinct models, primarily from the 2017-2020 period.
### Components/Axes (Table Columns)
The table is organized into the following columns:
1. **Model**: The name of the language model, often followed by a citation in parentheses (e.g., `[Vaswani et al., 2017]`).
2. **Input Tokens**: The maximum number of input tokens the model can process.
3. **GFLOPs**: Giga Floating-Point Operations, a measure of computational cost for a forward pass. Values are attributed to specific sources (e.g., `[Clark et al., 2021b]`).
4. **Params (M)**: The number of model parameters in millions.
5. **Date**: The publication or release date in DD/MM/YYYY format.
6. **GLUE test set**: The model's score on the General Language Understanding Evaluation benchmark. Scores are followed by a citation and, in many cases, a black spade symbol (♠).
### Detailed Analysis
**Language Note:** The primary language of the table is English. Some citations contain names from other languages (e.g., `Gholami` is Persian). These are transcribed directly as they appear.
**Row-by-Row Data Extraction:**
| Model | Input Tokens | GFLOPs | Params (M) | Date | GLUE test set |
| :--- | :--- | :--- | :--- | :--- | :--- |
| Transformer [Vaswani et al., 2017] | 512 | 54 [Clark et al., 2021b] | 65 | 12/06/2017 | - |
| ELMO [Peters et al., 2018] | 128 | 26 [Clark et al., 2020] | 96 | 15/02/2018 | 71.2 [Clark et al., 2020] ♠ |
| GPT-1 [Radford et al., 2018] | 128 | 30 [Clark et al., 2020] | 117 | 11/06/2018 | 75.1 [Devlin et al., 2019] ♠ |
| BERT Large [Devlin et al., 2019] | 128 | 79 | 335* | 11/10/2019 | 82.1 ♠ |
| BERT-Small [Devlin et al., 2019] | 128 | 3.7 [Clark et al., 2020] | 14 | 11/10/2019 | - |
| BERT-Base [Devlin et al., 2019] | 128 | 29 [Clark et al., 2020] | 110 | 11/10/2019 | 79.6 ♠ |
| GPT-2 [Radford et al., 2019] | 1024 | 3400 [Gholami et al., 2021b] | 1500 | 14/02/2019 | - |
| RoBERTa [Liu et al., 2019] | 1024 | 18000 [Gholami et al., 2021b] | 3800 | 26/07/2019 | - |
| ALBERT-xxl [Lan et al., 2020] | 512 | 2500 [Gholami et al., 2021b] | 235 | 26/09/2019 | - |
| ALBERT-base [Lan et al., 2020] | 128 | 22.5 [Iandola et al., 2020] | 12 | 26/09/2019 | - |
| Theseus 6/768 [Xu et al., 2020] | 128 | 11.3 [Iandola et al., 2020] | 66 | 07/02/2020 | 77.1 [Iandola et al., 2020] |
| Microsoft T-NGL [Rosset et al., 2020] | 1024 | 36000 [Gholami et al., 2021b] | 17000 | 13/02/2020 | - |
| ELECTRA Large [Clark et al., 2020] | 128 | 79 [Gholami et al., 2021b] | 335 | 23/03/2020 | 88.6 ♠ |
| ELECTRA Small [Clark et al., 2020] | 128 | 3.7 | 14 | 23/03/2020 | 78 ♠ |
| ELECTRA-Base [Clark et al., 2020] | 128 | 29 | 110 | 23/03/2020 | 83.5 ♠ |
| MobileBERT [Sun et al., 2020] | 128 | 5.36 | 25.3 | 06/04/2020 | 78.5 ♠ |
| MobileBERT tiny [Sun et al., 2020] | 128 | 3.1 | 15.1 | 06/04/2020 | 75.8 ♠ |
| GPT-3 [Brown et al., 2020] | 2048 | 740000 [Gholami et al., 2021b] | 175000 | 28/05/2020 | - |
| SqueezeNet [Iandola et al., 2020] | 128 | 7.42 | 51.1 | 19/06/2020 | 78.1 |
**Notes on Data:**
* The `*` next to BERT Large's parameter count (335*) likely indicates an estimated or approximate value.
* The `♠` symbol appears consistently next to GLUE scores, likely denoting results from a specific evaluation setup or that the score is state-of-the-art at the time of publication.
* Many GFLOPs values are not intrinsic to the model but are cited from secondary analysis papers (e.g., `Clark et al., 2021b`, `Gholami et al., 2021b`).
### Key Observations
1. **Scale Explosion**: There is a dramatic increase in model scale over time. Parameters grow from 65M (Transformer, 2017) to 175,000M (GPT-3, 2020). GFLOPs show an even more extreme increase, from 54 to 740,000.
2. **Input Context**: Most early models use 128 or 512 tokens. Later large models (GPT-2, RoBERTa, T-NGL, GPT-3) use 1024 or 2048 tokens, enabling longer context understanding.
3. **Efficiency Variants**: Models like BERT-Small, ALBERT-base, and MobileBERT represent efforts to create smaller, more efficient models with GFLOPs as low as 3.1-3.7, compared to 79+ for their larger counterparts.
4. **GLUE Performance**: The GLUE benchmark scores show a general upward trend, from 71.2 (ELMO) to 88.6 (ELECTRA Large). However, not all models report a score, and the highest score (88.6) does not come from the largest model (GPT-3), suggesting architectural innovations can be as impactful as scale.
5. **Outlier**: GPT-3 is a massive outlier in terms of parameters (175B) and computational cost (740 TFLOPs), dwarfing all other models in the list.
### Interpretation
This table serves as a historical snapshot of the rapid evolution in language model research between 2017 and 2020. It demonstrates two parallel and sometimes competing trends: the pursuit of **scale** (exemplified by GPT-3) and the pursuit of **efficiency** (exemplified by MobileBERT and SqueezeNet).
The data suggests that while increasing model size and computational budget (GFLOPs) generally correlates with better performance on benchmarks like GLUE, it is not the sole determinant. Architectural innovations (e.g., ELECTRA's replaced token detection) can yield superior performance with a fraction of the computational cost of the largest models. The absence of GLUE scores for the very largest models (GPT-2, RoBERTa, GPT-3) might indicate they were evaluated on different, more challenging benchmarks or that their primary contribution was demonstrated through generation rather than classification tasks.
The citations within the GFLOPs and GLUE columns highlight that these metrics are often not self-reported but are the subject of independent analysis and benchmarking by the research community, which is crucial for fair comparison. The table implicitly argues for the importance of considering multiple dimensions—performance, size, speed, and cost—when evaluating and selecting a language model for a specific application.