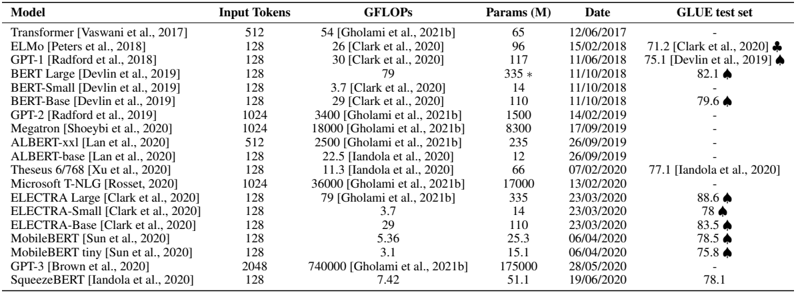
## Table: Comparative Analysis of NLP Models
### Overview
The table presents a comparative analysis of various natural language processing (NLP) models, including their input token capacity, computational efficiency (GFLOPs), parameter count (in millions), release dates, and performance on the GLUE benchmark test set. The data spans models developed between 2017 and 2020, with annotations for specific metrics and symbols.
### Components/Axes
- **Headers**: Model, Input Tokens, GFLOPs, Params (M), Date, GLUE test set.
- **Rows**: Each row corresponds to a distinct model, with data points aligned under respective columns.
- **Symbols**:
- ♣: Indicates a specific metric (e.g., Clark et al., 2020).
- ♠: Denotes a distinct evaluation (e.g., Devlin et al., 2019).
### Detailed Analysis
1. **Model Variants**:
- **Transformer** (Vaswani et al., 2017): 512 input tokens, 54 GFLOPs, 65M parameters, released 12/06/2017, no GLUE score.
- **ELMo** (Peters et al., 2018): 128 input tokens, 26 GFLOPs, 96M parameters, released 15/02/2018, GLUE score 71.2 ♣.
- **GPT-1** (Radford et al., 2018): 128 input tokens, 30 GFLOPs, 117M parameters, released 11/06/2018, GLUE score 75.1 ♠.
- **BERT-Large** (Devlin et al., 2019): 128 input tokens, 79 GFLOPs, 335M parameters (marked with *), released 11/10/2018, GLUE score 82.1 ♠.
- **BERT-Small** (Devlin et al., 2019): 128 input tokens, 3.7 GFLOPs, 14M parameters, released 11/10/2018, no GLUE score.
- **BERT-Base** (Devlin et al., 2019): 128 input tokens, 29 GFLOPs, 110M parameters, released 11/10/2018, GLUE score 79.6 ♠.
- **GPT-2** (Radford et al., 2019): 1024 input tokens, 3400 GFLOPs, 1500M parameters, released 14/02/2019, no GLUE score.
- **Megatron** (Shoeybi et al., 2020): 1024 input tokens, 18,000 GFLOPs, 8300M parameters, released 17/09/2019, no GLUE score.
- **ALBERT-xxl** (Lan et al., 2020): 512 input tokens, 2500 GFLOPs, 235M parameters, released 26/09/2019, no GLUE score.
- **ALBERT-base** (Lan et al., 2020): 128 input tokens, 22.5 GFLOPs, 12M parameters, released 26/09/2019, no GLUE score.
- **Theseus 6/768** (Xu et al., 2020): 128 input tokens, 11.3 GFLOPs, 66M parameters, released 07/02/2020, GLUE score 77.1.
- **Microsoft T-NLG** (Rosset, 2020): 1024 input tokens, 36,000 GFLOPs, 17,000M parameters, released 13/02/2020, no GLUE score.
- **ELECTRA-Large** (Clark et al., 2020): 128 input tokens, 79 GFLOPs, 335M parameters, released 23/03/2020, GLUE score 88.6 ♠.
- **ELECTRA-Small** (Clark et al., 2020): 128 input tokens, 3.7 GFLOPs, 14M parameters, released 23/03/2020, GLUE score 78 ♠.
- **ELECTRA-Base** (Clark et al., 2020): 128 input tokens, 29 GFLOPs, 110M parameters, released 23/03/2020, GLUE score 83.5 ♠.
- **MobileBERT** (Sun et al., 2020): 128 input tokens, 5.36 GFLOPs, 25.3M parameters, released 06/04/2020, GLUE score 78.5 ♠.
- **MobileBERT tiny** (Sun et al., 2020): 128 input tokens, 3.1 GFLOPs, 15.1M parameters, released 06/04/2020, GLUE score 75.8 ♠.
- **GPT-3** (Brown et al., 2020): 2048 input tokens, 740,000 GFLOPs, 175,000M parameters, released 28/05/2020, no GLUE score.
- **SqueezeBERT** (Iandola et al., 2020): 128 input tokens, 7.42 GFLOPs, 51.1M parameters, released 19/06/2020, GLUE score 78.1.
2. **Missing Data**:
- GLUE scores are absent for Transformer, GPT-2, Megatron, ALBERT variants, Theseus, Microsoft T-NLG, and GPT-3.
3. **Parameter Trends**:
- Larger models (e.g., GPT-3, Microsoft T-NLG) exhibit significantly higher parameter counts (175,000M and 17,000M, respectively) compared to smaller models like BERT-Small (14M).
4. **Computational Efficiency**:
- GFLOPs vary widely, with GPT-3 requiring 740,000 GFLOPs and BERT-Small using only 3.7 GFLOPs.
5. **GLUE Performance**:
- ELECTRA-Large achieves the highest GLUE score (88.6 ♠), while MobileBERT tiny scores the lowest (75.8 ♠).
### Key Observations
- **Model Size vs. Performance**: Larger models (e.g., GPT-3, ELECTRA-Large) generally achieve higher GLUE scores, though exceptions exist (e.g., BERT-Large outperforms GPT-1 despite fewer parameters).
- **Efficiency Trade-offs**: Smaller models (e.g., BERT-Small, MobileBERT tiny) use fewer computational resources but show lower GLUE scores.
- **Input Token Capacity**: Models like GPT-2 and GPT-3 support longer sequences (1024–2048 tokens), while most others are limited to 128 tokens.
- **Release Timeline**: Models evolved from 2017 (Transformer) to 2020 (GPT-3), reflecting rapid advancements in NLP.
### Interpretation
The data highlights a trade-off between model size, computational efficiency, and performance. While larger models (e.g., GPT-3) demonstrate superior parameter counts and input capacity, their computational demands (GFLOPs) are substantially higher. Conversely, smaller models (e.g., BERT-Small) offer efficiency but lag in GLUE performance. The absence of GLUE scores for some models (e.g., GPT-3) suggests either unavailability of data or focus on other evaluation metrics. The symbols ♣ and ♠ likely denote distinct evaluation frameworks, emphasizing the need for standardized benchmarks. Overall, the table underscores the diversity of approaches in NLP, balancing scalability, efficiency, and accuracy.