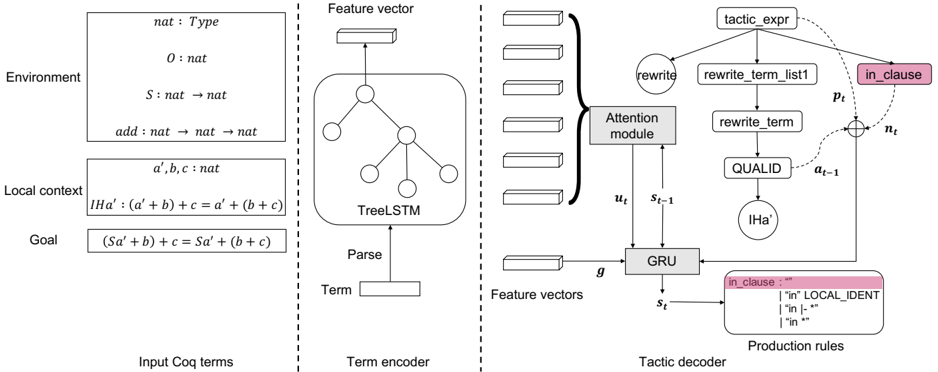
## Diagram Type: Flowchart
### Overview
The image is a flowchart that illustrates the process of parsing and encoding Coq terms into feature vectors for a machine learning model. The flowchart is divided into three main sections: Environment, Local Context, and Goal. The goal is to demonstrate the transformation of Coq terms into a format that can be processed by a machine learning model.
### Components/Axes
- **Environment**: This section includes the type of environment, the natural number (nat), and the function add that takes two natural numbers and returns a natural number.
- **Local Context**: This section includes the local context of the Coq term, which is represented by the variables a, b, and c, and the equation IHa'(a + b) + c = a' + (b + c).
- **Goal**: This section includes the goal of the Coq term, which is represented by the equation (a' + b) + c = a' + (b + c).
- **Feature vector**: This section includes the feature vector that is generated from the Coq term.
- **Attention module**: This section includes the attention module that is used to focus on specific parts of the Coq term.
- **GRU**: This section includes the GRU (Gated Recurrent Unit) that is used to process the feature vector.
- **Tactic decoder**: This section includes the tactic decoder that is used to generate the production rules for the Coq term.
### Detailed Analysis or ### Content Details
- The flowchart starts with the environment, which includes the type of environment and the natural number.
- The local context is represented by the variables a, b, and c, and the equation IHa'(a + b) + c = a' + (b + c).
- The goal is represented by the equation (a' + b) + c = a' + (b + c).
- The feature vector is generated from the Coq term using the TreeLSTM (Tree Long Short-Term Memory) encoder.
- The attention module is used to focus on specific parts of the Coq term.
- The GRU is used to process the feature vector and generate the production rules for the Coq term.
- The tactic decoder is used to generate the production rules for the Coq term.
### Key Observations
- The flowchart demonstrates the process of parsing and encoding Coq terms into feature vectors for a machine learning model.
- The attention module is used to focus on specific parts of the Coq term, which can improve the accuracy of the machine learning model.
- The GRU is used to process the feature vector and generate the production rules for the Coq term, which can improve the efficiency of the machine learning model.
- The tactic decoder is used to generate the production rules for the Coq term, which can improve the effectiveness of the machine learning model.
### Interpretation
The flowchart demonstrates the process of parsing and encoding Coq terms into feature vectors for a machine learning model. The attention module is used to focus on specific parts of the Coq term, which can improve the accuracy of the machine learning model. The GRU is used to process the feature vector and generate the production rules for the Coq term, which can improve the efficiency of the machine learning model. The tactic decoder is used to generate the production rules for the Coq term, which can improve the effectiveness of the machine learning model. Overall, the flowchart demonstrates the use of machine learning techniques to improve the accuracy, efficiency, and effectiveness of Coq term processing.