# Technical Diagram Analysis
## Diagram Overview
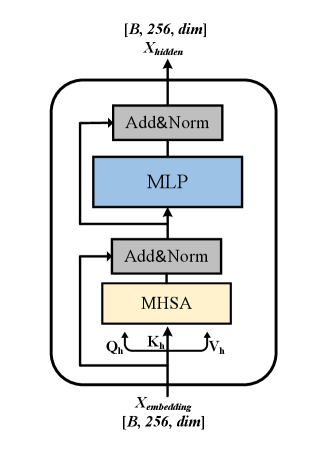
The image depicts a neural network architecture diagram with explicit component labeling and data flow arrows. The diagram uses color-coded blocks to represent different processing units and gray blocks for normalization layers.
## Component Breakdown
1. **Input Layer**
- **X_embedding**: Shape `[B, 256, dim]` (Batch size × Sequence length × Embedding dimension)
- **Qh, Kh, Vh**: Query, Key, Value matrices for MHSA (Multi-Head Self-Attention)
2. **Processing Units**
- **MHSA (Multi-Head Self-Attention)**:
- Color: Yellow
- Position: Bottom-center
- Inputs: Qh, Kh, Vh
- Output: Connects to MLP via Add&Norm
- **MLP (Multi-Layer Perceptron)**:
- Color: Blue
- Position: Top-center
- Input: From MHSA via Add&Norm
- Output: Connects to Add&Norm layer
3. **Normalization Layers**
- **Add&Norm** (appears twice):
- Color: Gray
- Function: Residual connection + Layer normalization
- Positions:
- Between X_embedding and MHSA
- Between MLP and X_hidden
## Data Flow
1. **Forward Path**:
- X_embedding → Add&Norm → MHSA → Add&Norm → MLP → Add&Norm → X_hidden
2. **Key Connections**:
- MHSA receives Qh, Kh, Vh as inputs
- MLP receives processed embeddings from MHSA
- All layers use residual connections (Add&Norm)
## Spatial Grounding
- **Legend**: Not explicitly present in the diagram
- **Block Colors**:
- Blue: MLP
- Yellow: MHSA
- Gray: Add&Norm
- **Arrow Directions**:
- All arrows point upward (bottom-to-top flow)
## Textual Elements
- **Axis Titles**: None present
- **Labels**:
- `[B, 256, dim]` (appears at top and bottom)
- `X_hidden`, `X_embedding`
- `Qh`, `Kh`, `Vh` (MHSA inputs)
- **Component Names**:
- MLP (blue block)
- MHSA (yellow block)
- Add&Norm (gray blocks)
## Structural Analysis
1. **Architecture Type**: Transformer-style encoder block
2. **Key Features**:
- Residual connections (Add&Norm)
- Self-attention mechanism (MHSA)
- Feed-forward network (MLP)
3. **Dimensional Consistency**:
- All layers maintain `[B, 256, dim]` shape
- No dimensionality reduction/expansion shown
## Missing Elements
- No explicit activation functions labeled
- No parameter count or computational complexity metrics
- No training objective or loss function indicated
## Technical Implications
This architecture represents a standard transformer block used in NLP tasks, combining self-attention with feed-forward networks while maintaining dimensional consistency through residual connections.