TECHNICAL ASSET FINGERPRINT
9b6e0941ba58de6dac26d9f1
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: gemini-2.5-flash-free VERSION 1
RUNTIME: google-free/gemini-2.5-flash
INTEL_VERIFIED
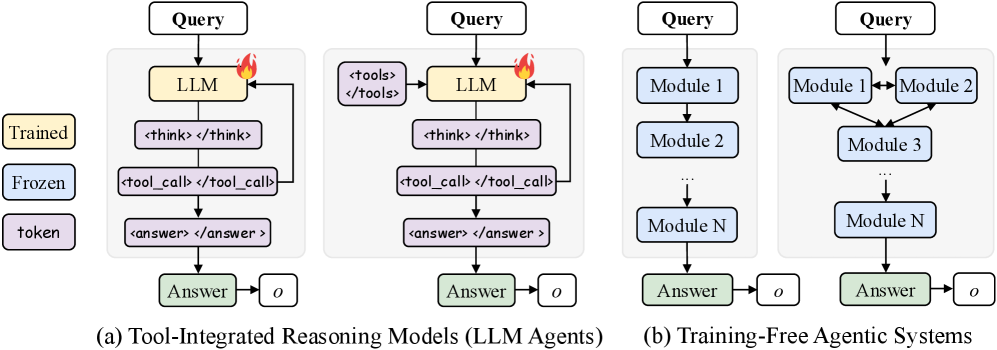
## Diagram: Architectures of Agentic Systems
### Overview
This image presents a technical diagram illustrating two primary categories of agentic systems: (a) Tool-Integrated Reasoning Models (LLM Agents) and (b) Training-Free Agentic Systems. Each category is further broken down into two distinct architectural examples, showcasing different internal flows and component interactions. The diagram uses color-coding to denote the state or type of each component (Trained, Frozen, or token) and includes a legend to clarify these distinctions.
### Components/Axes
The diagram is structured with a legend on the top-left and two main sections labeled (a) and (b) at the bottom.
**Legend (top-left):**
* A yellow rounded rectangle labeled "Trained"
* A light blue rounded rectangle labeled "Frozen"
* A purple rounded rectangle labeled "token"
**Common Elements across all diagrams:**
* **Input:** A white rounded rectangle at the top of each flow, labeled "Query".
* **Output:** A green rounded rectangle at the bottom of each flow, labeled "Answer".
* **Final Output Object:** A white square with slightly rounded corners, labeled "o", connected by an arrow from the "Answer" box.
* **System Boundary:** Each set of internal components for a system is enclosed within a light grey shaded background.
### Detailed Analysis
The image is divided into two main sections, (a) and (b), each containing two sub-diagrams.
**Section (a): Tool-Integrated Reasoning Models (LLM Agents)**
This section is located on the left side of the image.
* **Sub-diagram (a.1) - Leftmost LLM Agent:**
* **Flow:**
1. An arrow points from the "Query" (white) input to an "LLM" (yellow) component.
2. The "LLM" box has a small red flame icon at its top-right, indicating it is trainable or actively being used in a dynamic, adaptable manner.
3. An arrow points from the "LLM" to a purple box labeled ``.
4. An arrow points from `` to a purple box labeled `<tool_call> </tool_call>`.
5. A feedback loop arrow points from the bottom of `<tool_call> </tool_call>` back to the right side of the "LLM" box.
6. An arrow points from `<tool_call> </tool_call>` to a purple box labeled `<answer> </answer>`.
7. An arrow points from `<answer> </answer>` to the "Answer" (green) output.
8. An arrow points from "Answer" to the final output object "o" (white).
* **Component Colors:** "LLM" is yellow (Trained). `<think>`, `<tool_call>`, and `<answer>` are purple (token). "Answer" is green.
* **Sub-diagram (a.2) - Rightmost LLM Agent (within section a):**
* **Flow:**
1. An arrow points from the "Query" (white) input to an "LLM" (yellow) component.
2. An arrow points from `<tools>` (purple) to the "LLM" (yellow) component.
3. The "LLM" box has a small red flame icon at its top-right.
4. An arrow points from the "LLM" to a purple box labeled ``.
5. An arrow points from `` to a purple box labeled `<tool_call> </tool_call>`.
6. A feedback loop arrow points from the bottom of `<tool_call> </tool_call>` back to the right side of the "LLM" box.
7. An arrow points from `<tool_call> </tool_call>` to a purple box labeled `<answer> </answer>`.
8. An arrow points from `<answer> </answer>` to the "Answer" (green) output.
9. An arrow points from "Answer" to the final output object "o" (white).
* **Component Colors:** "LLM" is yellow (Trained). `<tools>`, `<think>`, `<tool_call>`, and `<answer>` are purple (token). "Answer" is green.
**Section (b): Training-Free Agentic Systems**
This section is located on the right side of the image.
* **Sub-diagram (b.1) - Leftmost Training-Free System:**
* **Flow:**
1. An arrow points from the "Query" (white) input to "Module 1" (light blue).
2. An arrow points from "Module 1" to "Module 2" (light blue).
3. A vertical ellipsis "..." with arrows above and below indicates a sequence of intermediate modules.
4. An arrow points from the ellipsis to "Module N" (light blue).
5. An arrow points from "Module N" to the "Answer" (green) output.
6. An arrow points from "Answer" to the final output object "o" (white).
* **Component Colors:** "Module 1", "Module 2", and "Module N" are light blue (Frozen). "Answer" is green. No flame icon is present.
* **Sub-diagram (b.2) - Rightmost Training-Free System (within section b):**
* **Flow:**
1. An arrow points from the "Query" (white) input to "Module 1" (light blue) and also to "Module 2" (light blue).
2. A double-headed arrow connects "Module 1" and "Module 2", indicating bidirectional communication.
3. Arrows point from both "Module 1" and "Module 2" downwards to "Module 3" (light blue).
4. A vertical ellipsis "..." with arrows above and below indicates a sequence of intermediate modules.
5. An arrow points from the ellipsis to "Module N" (light blue).
6. An arrow points from "Module N" to the "Answer" (green) output.
7. An arrow points from "Answer" to the final output object "o" (white).
* **Component Colors:** "Module 1", "Module 2", "Module 3", and "Module N" are light blue (Frozen). "Answer" is green. No flame icon is present.
### Key Observations
* **Color-Coding Significance:** The legend clearly defines the state of components: "Trained" (yellow) for the core LLM, "Frozen" (light blue) for fixed modules, and "token" (purple) for intermediate outputs or structured prompts within LLM agents.
* **Trainability vs. Fixed Modules:** LLM Agents (a) feature a "Trained" LLM with a flame icon, implying adaptability or fine-tuning. Training-Free Agentic Systems (b) use "Frozen" modules, indicating pre-defined, unchangeable components.
* **LLM Agent Internal Process:** LLM Agents demonstrate an iterative reasoning process involving explicit "tokens" for thinking (`<think>`), tool invocation (`<tool_call>`), and answer formulation (`<answer>`), with a feedback loop from tool calls back to the LLM.
* **Tool Integration:** Sub-diagram (a.2) explicitly shows `<tools>` as an input to the LLM, highlighting a mechanism for providing external capabilities to the LLM's reasoning.
* **Training-Free System Modularity:** Training-Free systems (b) emphasize modularity, with flows ranging from simple sequential execution (b.1) to more complex, interconnected module interactions (b.2).
* **Consistent Output:** All four architectures ultimately produce an "Answer" and an associated output object "o", suggesting a common goal despite diverse internal mechanisms.
### Interpretation
The diagram provides a clear conceptual distinction between two major paradigms for designing intelligent agents.
**Tool-Integrated Reasoning Models (LLM Agents)** represent a paradigm where a central, adaptable Large Language Model (LLM) acts as the primary orchestrator and reasoner. The "Trained" (yellow) LLM with the flame icon signifies its dynamic nature, capable of learning, adapting, or being fine-tuned. The use of "token" (purple) tags like `<think>`, `<tool_call>`, and `<answer>` suggests that the LLM generates structured internal thoughts or prompts to guide its own reasoning process. The feedback loop from `<tool_call>` back to the LLM is crucial, enabling iterative refinement: the LLM can call a tool, observe its output, and then use that information to further refine its thinking or make subsequent tool calls. This architecture is highly flexible and can handle complex, open-ended tasks by leveraging the LLM's emergent reasoning capabilities and its ability to interact with external tools. The explicit `<tools>` input in (a.2) further emphasizes the LLM's role in integrating and utilizing external functionalities.
**Training-Free Agentic Systems**, in contrast, represent a more traditional, modular approach. The "Frozen" (light blue) modules indicate that these components have fixed functionalities and are not subject to runtime training or adaptation. This paradigm is suitable for tasks where the sub-problems are well-defined and can be encapsulated within specialized, pre-built modules. Sub-diagram (b.1) illustrates a straightforward sequential pipeline, where information flows linearly through a series of modules, each performing a specific step. Sub-diagram (b.2) demonstrates a more sophisticated modular design, allowing for parallel processing or bidirectional communication between modules (e.g., "Module 1" and "Module 2") before converging into a subsequent processing chain. This approach offers greater control, transparency, and potentially higher reliability for specific tasks, as the behavior of each module is predictable.
In essence, the diagram highlights a trade-off: LLM Agents offer adaptability and emergent intelligence through a central, trainable model, often at the cost of full transparency and predictability. Training-Free Agentic Systems offer predictability and control through a composition of fixed, specialized modules, potentially at the cost of adaptability to novel situations. Both approaches aim to process a "Query" and yield an "Answer" with an associated output "o", indicating that the choice of architecture depends on the specific requirements of the agent's task, including the need for flexibility, interpretability, and performance.
DECODING INTELLIGENCE...