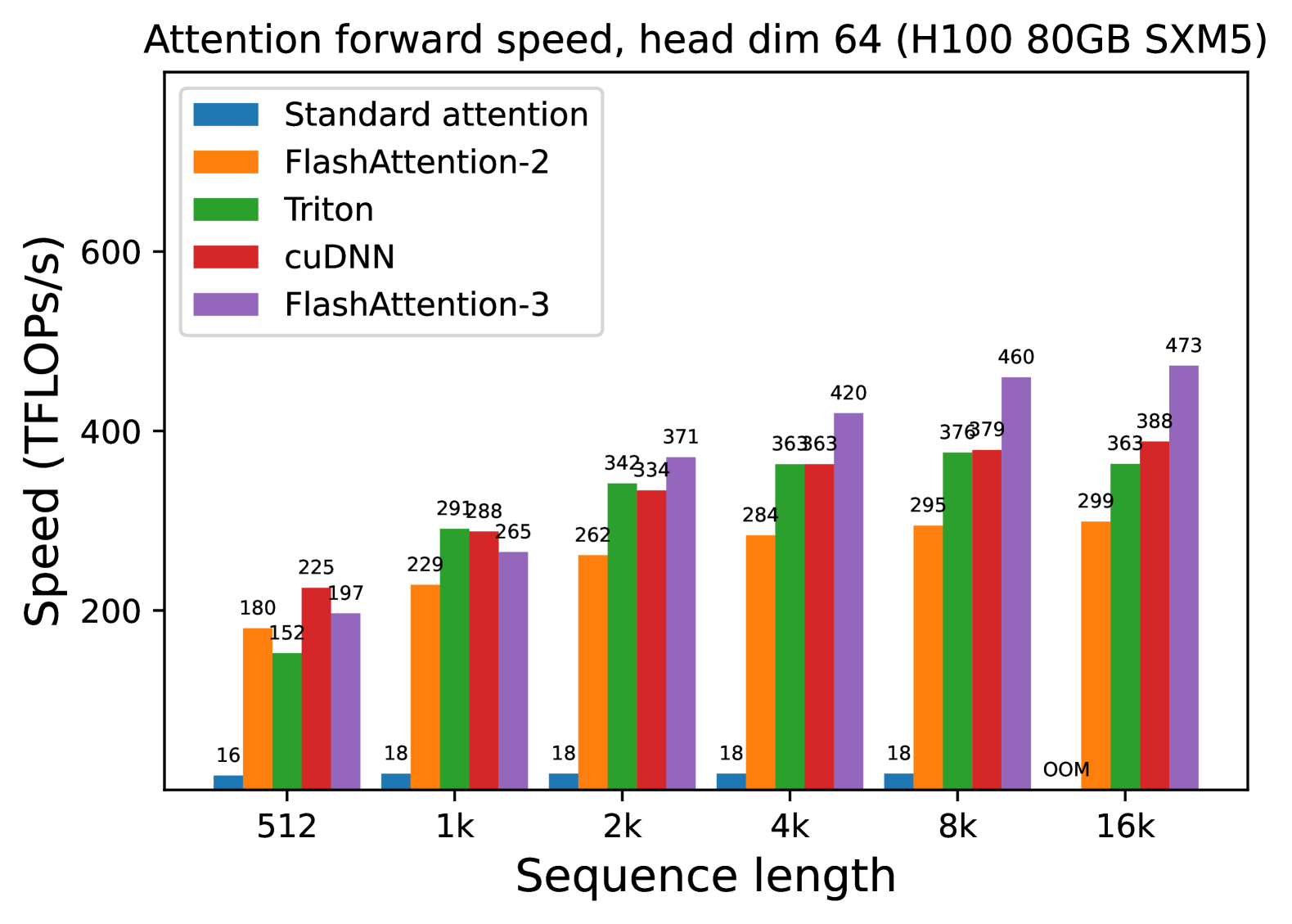
# Chart Analysis: Attention Forward Speed (Head Dim 64, H100 80GB SXM5)
## Chart Components
- **Title**: "Attention forward speed, head dim 64 (H100 80GB SXM5)"
- **X-Axis**: "Sequence length" with categories: `512`, `1k`, `2k`, `4k`, `8k`, `16k`
- **Y-Axis**: "Speed (TFLOPs/s)" ranging from 0 to 600
- **Legend**:
- `Standard attention` (blue)
- `FlashAttention-2` (orange)
- `Triton` (green)
- `cuDNN` (red)
- `FlashAttention-3` (purple)
## Data Points
| Sequence Length | Standard attention | FlashAttention-2 | Triton | cuDNN | FlashAttention-3 |
|-----------------|--------------------|------------------|--------|-------|------------------|
| 512 | 16 | 180 | 152 | 225 | 197 |
| 1k | 18 | 229 | 288 | 288 | 265 |
| 2k | 18 | 262 | 342 | 334 | 371 |
| 4k | 18 | 284 | 363 | 363 | 420 |
| 8k | 18 | 295 | 376 | 379 | 460 |
| 16k | OOM | 299 | 363 | 388 | 473 |
## Key Observations
1. **Performance Trends**:
- `FlashAttention-3` consistently achieves the highest speed across all sequence lengths.
- `Standard attention` fails at `16k` (marked as "OOM" for out-of-memory).
- `cuDNN` and `Triton` show comparable performance, with `Triton` slightly outperforming `cuDNN` at longer sequences.
- `FlashAttention-2` lags behind other methods but remains stable.
2. **Speed Scaling**:
- All methods exhibit increased speed with longer sequence lengths, except `Standard attention` at `16k`.
- `FlashAttention-3` demonstrates the steepest improvement, reaching `473 TFLOPs/s` at `16k`.
3. **Memory Constraints**:
- `Standard attention` is the only method unable to handle `16k` sequences due to memory limitations.