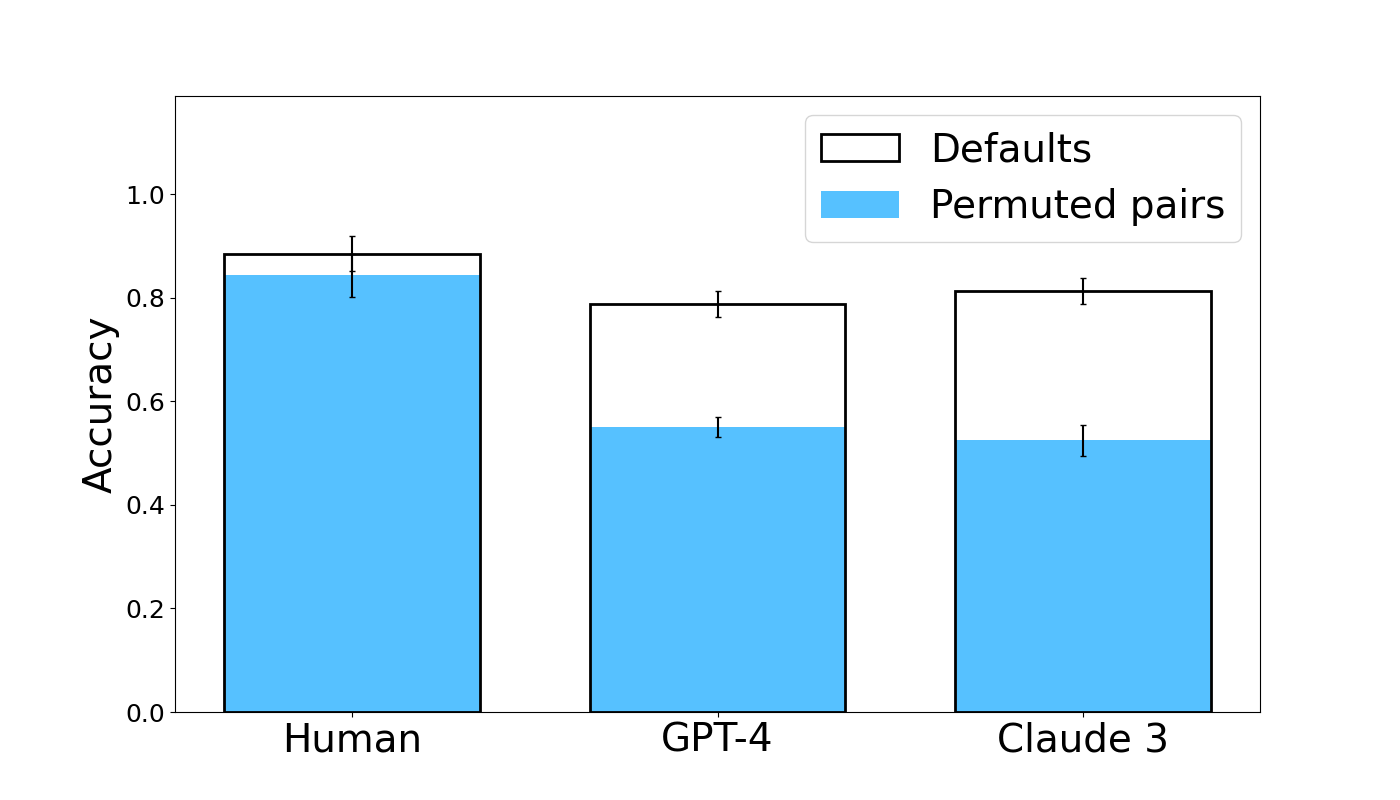
## Bar Chart: Accuracy Comparison Across Entities
### Overview
The chart compares accuracy metrics for three entities (Human, GPT-4, Claude 3) using two methods: Defaults (white bars) and Permuted pairs (blue bars). Accuracy is measured on a scale from 0.0 to 1.0, with error bars indicating variability.
### Components/Axes
- **X-axis**: Categories labeled "Human," "GPT-4," and "Claude 3."
- **Y-axis**: Accuracy values ranging from 0.0 to 1.0.
- **Legend**:
- White bars = Defaults
- Blue bars = Permuted pairs
- **Error bars**: Present for all bars, visually consistent in length.
### Detailed Analysis
1. **Human**:
- Defaults: ~0.85 accuracy (white bar).
- Permuted pairs: ~0.83 accuracy (blue bar).
- Error bars: ±~0.03 for both methods.
2. **GPT-4**:
- Defaults: ~0.75 accuracy (white bar).
- Permuted pairs: ~0.55 accuracy (blue bar).
- Error bars: ±~0.04 for both methods.
3. **Claude 3**:
- Defaults: ~0.78 accuracy (white bar).
- Permuted pairs: ~0.50 accuracy (blue bar).
- Error bars: ±~0.04 for both methods.
### Key Observations
- **Defaults outperform Permuted pairs** in all categories, with the largest gap in GPT-4 (~0.20 difference) and Claude 3 (~0.28 difference).
- **Human accuracy** is highest overall (~0.85 for Defaults), followed by Claude 3 (~0.78) and GPT-4 (~0.75).
- Error bars suggest similar variability across methods and entities.
### Interpretation
The data demonstrates that **Defaults consistently yield higher accuracy** than Permuted pairs, particularly for AI models (GPT-4 and Claude 3). The significant drop in accuracy for permuted pairs in AI systems suggests that pair permutations disrupt their performance more than human judgment. Humans show minimal sensitivity to permutation changes, aligning with expectations of robust cognitive processing. The error bars indicate measurement consistency but do not reveal systematic biases. This pattern highlights the importance of maintaining default configurations for optimal AI performance in tasks requiring pair comparisons.