TECHNICAL ASSET FINGERPRINT
9bfc0d5703337883bfe236bb
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: gemini-2.0-flash VERSION 1
RUNTIME: nugit/gemini/gemini-2.0-flash
INTEL_VERIFIED
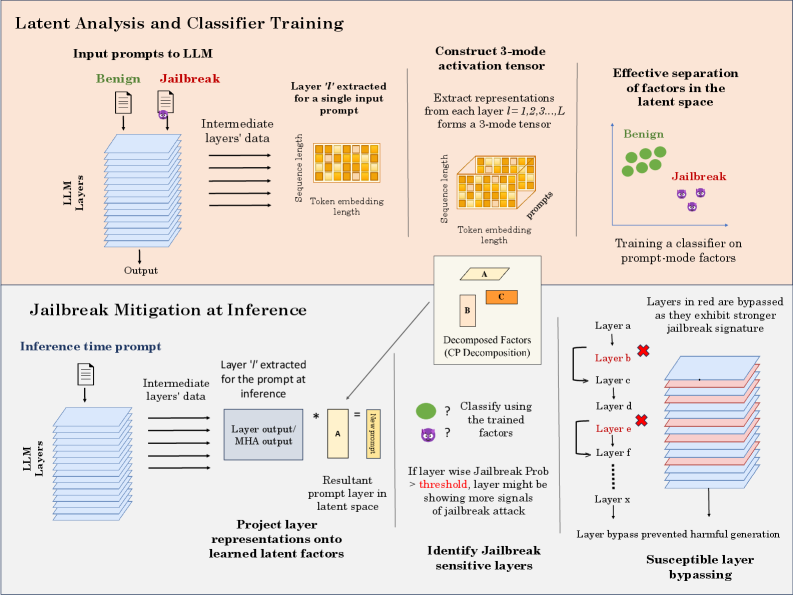
## Diagram: Latent Analysis and Classifier Training and Jailbreak Mitigation at Inference
### Overview
The image presents a diagram illustrating two main processes: "Latent Analysis and Classifier Training" and "Jailbreak Mitigation at Inference." The first process describes how a classifier is trained to distinguish between benign and jailbreak prompts based on latent factors extracted from an LLM. The second process outlines a method for mitigating jailbreak attempts during inference by identifying and bypassing sensitive layers.
### Components/Axes
**Latent Analysis and Classifier Training (Top Section):**
* **Input prompts to LLM:** Shows two input prompts, one labeled "Benign" (represented by a green document icon) and the other "Jailbreak" (represented by a purple document icon with a lock).
* **LLM Layers:** A stack of blue layers representing the layers of the Large Language Model (LLM).
* **Intermediate layers' data:** Arrows indicate data flow from the input prompts through the LLM layers.
* **Layer 'l' extracted for a single input prompt:** A yellow rectangle representing the extracted layer, labeled with "Sequence length" and "Token embedding length."
* **Construct 3-mode activation tensor:** A 3D cube composed of smaller yellow cubes, representing the activation tensor. Labeled with "Sequence length," "prompts," and "Token embedding length."
* **Effective separation of factors in the latent space:** A scatter plot showing two clusters: "Benign" (green circles) and "Jailbreak" (purple figures).
* **Decomposed Factors (CP Decomposition):** Three rectangles labeled A, B, and C. A is yellow, B is light red, and C is orange.
* **Training a classifier on prompt-mode factors:** Text indicating the purpose of the scatter plot.
**Jailbreak Mitigation at Inference (Bottom Section):**
* **Inference time prompt:** A document icon representing the input prompt.
* **LLM Layers:** A stack of blue layers representing the LLM layers.
* **Intermediate layers' data:** Arrows indicate data flow from the input prompt through the LLM layers.
* **Layer 'l' extracted for the prompt at inference:** A rectangle labeled "Layer output/MHA output."
* **Project layer representations onto learned latent factors:** Text describing the process.
* **Resultant prompt layer in latent space:** A rectangle labeled "New prompt."
* **Identify Jailbreak sensitive layers:** Text describing the goal of this section.
* **Classify using the trained factors:** Question marks next to a green circle and a purple figure, indicating classification.
* **If layer wise Jailbreak Prob > threshold, layer might be showing more signals of jailbreak attack:** Text describing the condition for identifying jailbreak-sensitive layers.
* **Susceptible layer bypassing:** Text describing the outcome of the process.
* **Layers in red are bypassed as they exhibit stronger jailbreak signature:** Text explaining the bypassing mechanism.
* **Layer bypass prevented harmful generation:** Text describing the benefit of layer bypassing.
* **Layer B, Layer E:** Layers marked in red with a cross, indicating they are bypassed.
* **Layer a, Layer c, Layer d, Layer f, Layer x:** Layers in blue.
### Detailed Analysis or ### Content Details
**Latent Analysis and Classifier Training:**
1. **Input Prompts:** The diagram starts with two types of input prompts: "Benign" and "Jailbreak." These prompts are fed into the LLM.
2. **LLM Layers:** The prompts pass through multiple layers of the LLM, represented by a stack of blue rectangles.
3. **Layer Extraction:** For a single input prompt, a specific layer 'l' is extracted. This layer is represented as a yellow rectangle, characterized by "Sequence length" and "Token embedding length."
4. **3-Mode Activation Tensor:** Representations from each layer (l = 1, 2, 3, ..., L) are extracted and formed into a 3-mode tensor. This tensor is visualized as a 3D cube.
5. **Factor Separation:** The process aims to achieve effective separation of factors in the latent space. This is visualized as a scatter plot where "Benign" prompts cluster separately from "Jailbreak" prompts.
6. **Classifier Training:** A classifier is trained on these prompt-mode factors to distinguish between benign and jailbreak attempts.
7. **Decomposed Factors:** The factors are decomposed into components A, B, and C.
**Jailbreak Mitigation at Inference:**
1. **Inference Time Prompt:** An input prompt is provided to the LLM during inference.
2. **LLM Layers:** The prompt passes through the LLM layers.
3. **Layer Extraction:** A specific layer 'l' is extracted for the prompt at inference. This layer's output is labeled "Layer output/MHA output."
4. **Projection onto Latent Factors:** The layer representations are projected onto learned latent factors.
5. **Resultant Prompt Layer:** This projection results in a "New prompt" layer in latent space.
6. **Jailbreak Detection:** The system classifies whether the prompt is a jailbreak attempt using the trained factors.
7. **Layer Bypassing:** If the layer-wise jailbreak probability exceeds a threshold, the layer is identified as jailbreak-sensitive and bypassed. Layers in red (Layer B, Layer E) are bypassed because they exhibit a stronger jailbreak signature.
8. **Harmful Generation Prevention:** Layer bypassing prevents harmful generation by avoiding the use of jailbreak-sensitive layers.
### Key Observations
* The diagram illustrates a two-stage process: training a classifier to detect jailbreak attempts and then using this classifier to mitigate jailbreak attempts during inference.
* The key idea is to identify and bypass layers that are highly sensitive to jailbreak attacks.
* The use of latent factor analysis allows for the separation of benign and jailbreak prompts in the latent space.
### Interpretation
The diagram presents a method for enhancing the safety and reliability of Large Language Models (LLMs) by mitigating jailbreak attempts. The approach involves training a classifier to distinguish between benign and malicious prompts based on latent factors extracted from the LLM's layers. During inference, the system identifies layers that are highly sensitive to jailbreak attacks and bypasses them, preventing the generation of harmful or inappropriate content.
The diagram highlights the importance of understanding the internal representations of LLMs and using this knowledge to improve their robustness. By identifying and mitigating jailbreak-sensitive layers, the system can effectively reduce the risk of malicious use and ensure that the LLM is used responsibly. The use of CP decomposition to decompose the factors into components A, B, and C suggests a method for further analyzing and understanding the underlying factors that contribute to jailbreak vulnerability.
DECODING INTELLIGENCE...
EXPERT: nemotron-free VERSION 1
RUNTIME: free/nvidia/nemotron-nano-12b-v2-vl:free
INTEL_VERIFIED
## Diagram: Latent Analysis and Classifier Training for Jailbreak Mitigation
### Overview
The diagram illustrates a two-phase process for detecting and mitigating jailbreak attacks in large language models (LLMs). It combines latent space analysis, classifier training, and inference-time mitigation strategies to identify and bypass harmful prompt-mode factors.
---
### Components/Axes
1. **Top Section: Latent Analysis and Classifier Training**
- **Input Prompts to LLM**:
- Two input types: *Benign* (green) and *Jailbreak* (red) prompts.
- Arrows show data flow through *LLM Layers* to an *Output*.
- **Intermediate Layers' Data**:
- Extracted from a specific layer (`Layer 'l'`) for a single input prompt.
- Visualized as a 2D grid with dimensions: *Sequence length* (rows) and *Token embedding length* (columns).
- **3-Mode Activation Tensor**:
- Constructed by extracting representations from all layers (`l=1,2,3,...,L`).
- Forms a 3D tensor with dimensions: *Sequence length*, *Token embedding length*, and *Layer depth*.
- **Effective Separation of Factors**:
- Visualized as clusters in latent space: *Benign* (green dots) and *Jailbreak* (purple dots).
- A classifier is trained on *prompt-mode factors* to distinguish these clusters.
2. **Bottom Section: Jailbreak Mitigation at Inference**
- **Inference-Time Prompt**:
- Input prompt processed through *LLM Layers*.
- Intermediate data extracted from `Layer 'l'` and multiplied by matrix **A** to form a *New Prompt Layer*.
- **Decomposed Factors (CP Decomposition)**:
- Visualized as a 3D tensor decomposed into factors **A**, **B**, and **C**.
- **Project Layer Representations**:
- Outputs are projected onto *learned latent factors* for classification.
- **Identify Jailbreak-Sensitive Layers**:
- If `Jailbreak Prob > threshold`, the layer is flagged as sensitive.
- **Susceptible Layer Bypassing**:
- Layers marked in red (e.g., `Layer b`, `Layer e`) are bypassed during inference to prevent harmful outputs.
---
### Detailed Analysis
- **Latent Space Separation**:
- Benign and jailbreak prompts are separated in latent space, enabling classifier training on prompt-mode factors.
- **3-Mode Tensor Construction**:
- Captures multi-dimensional interactions between sequence position, token embeddings, and layer depth.
- **Inference Mitigation**:
- Matrix **A** transforms intermediate layer outputs into a new prompt layer, which is analyzed for jailbreak signals.
- Layers with high jailbreak probability are bypassed to avoid harmful outputs.
---
### Key Observations
1. **Layer Sensitivity**:
- Certain layers (marked in red) exhibit stronger jailbreak signatures and are bypassed during inference.
2. **Classifier Training**:
- The classifier uses prompt-mode factors derived from the 3-mode tensor to distinguish benign from jailbreak inputs.
3. **Decomposition**:
- CP decomposition breaks down the activation tensor into interpretable factors (**A**, **B**, **C**), aiding in mitigation.
---
### Interpretation
This diagram demonstrates a defense mechanism against jailbreak attacks by leveraging latent space analysis. During training, the model learns to separate benign and malicious prompts in latent space. At inference, it dynamically identifies sensitive layers and bypasses them to prevent harmful outputs. The use of CP decomposition suggests an emphasis on interpretability, allowing the system to isolate and neutralize jailbreak signals effectively. The red-marked layers likely represent critical points where jailbreak attempts manifest, making them prime candidates for bypassing.
DECODING INTELLIGENCE...