\n
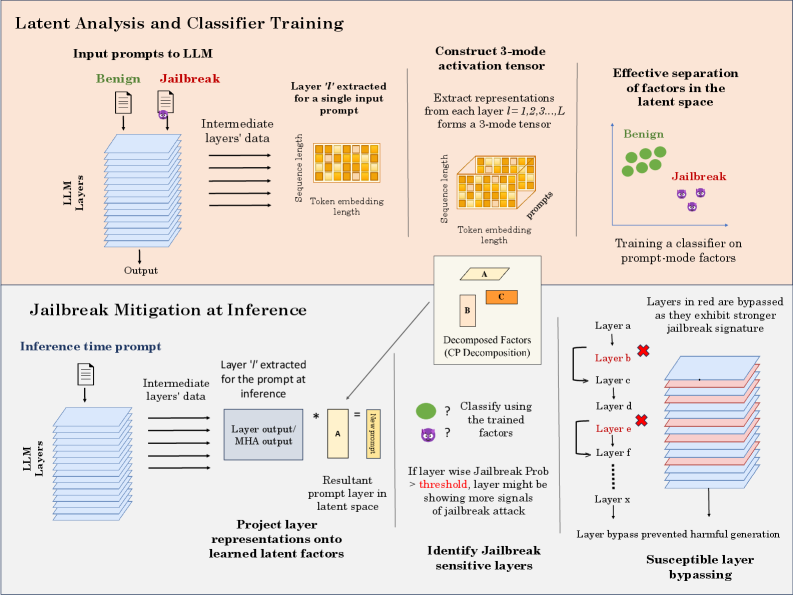
## Diagram: Latent Analysis and Classifier Training & Jailbreak Mitigation at Inference
### Overview
This diagram illustrates a two-part process: first, the latent analysis and training of a classifier to distinguish between benign and jailbreak prompts to a Large Language Model (LLM); and second, the application of this classifier during inference to mitigate jailbreak attacks. The diagram uses a series of stacked blocks representing LLM layers, and visual representations of data transformations.
### Components/Axes
The diagram is divided into two main sections: "Latent Analysis and Classifier Training" (top) and "Jailbreak Mitigation at Inference" (bottom). Each section contains several components:
* **LLM Layers:** Represented as stacked rectangular blocks in teal.
* **Input Prompts:** "Benign" and "Jailbreak" prompts are shown as input to the LLM.
* **Intermediate Layers' Data:** Represented as stacked rectangular blocks in grey.
* **Layer 't' extracted for a single input prompt:** A rectangular block representing a specific layer's output.
* **3-mode activation tensor:** A 3D representation of the extracted layer data.
* **Decomposed Factors (CP Decomposition):** Represented as blocks labeled A, B, and C.
* **Resultant prompt layer in latent space:** A rectangular block representing the projected prompt.
* **Classifier:** Represented as a question mark within a circle.
* **Layers in red are bypassed:** Layers highlighted in red, indicating they are bypassed during inference.
* **Susceptible layer bypassing:** A visual representation of bypassed layers.
The diagram also includes labels for key concepts like "Sequence length", "Token embedding length", "Effective separation of factors in the latent space", "Training a classifier on prompt-mode factors", "Identify Jailbreak sensitive layers", and "Layer bypass prevented harmful generation".
### Detailed Analysis or Content Details
**Latent Analysis and Classifier Training (Top Section):**
1. **Input Prompts:** Two types of input prompts are shown: "Benign" (green checkmark) and "Jailbreak" (red lock).
2. **LLM Layers:** The LLM is represented by a stack of teal blocks.
3. **Intermediate Layers' Data:** The output of the LLM layers is represented by a stack of grey blocks.
4. **Layer 't' extracted for a single input prompt:** A single layer's output is extracted for analysis. The dimensions are labeled "Sequence length" and "Token embedding length".
5. **Construct 3-mode activation tensor:** The extracted layer data is transformed into a 3-mode tensor, visualized as a 3D block with dimensions "Sequence length", "Token embedding length", and "prompts".
6. **Decomposed Factors (CP Decomposition):** The 3-mode tensor is decomposed into factors A, B, and C.
7. **Effective separation of factors in the latent space:** Benign prompts are represented as green dots clustered together, while Jailbreak prompts are represented as red dots clustered separately. This indicates successful separation in the latent space.
8. **Training a classifier on prompt-mode factors:** The decomposed factors are used to train a classifier to distinguish between benign and jailbreak prompts.
**Jailbreak Mitigation at Inference (Bottom Section):**
1. **Inference time prompt:** A single prompt is input to the LLM during inference.
2. **LLM Layers:** The LLM is again represented by a stack of teal blocks.
3. **Intermediate Layers' Data:** The output of the LLM layers is represented by a stack of grey blocks.
4. **Layer output/MHA output:** The output of a specific layer is extracted.
5. **Resultant prompt layer in latent space:** The layer output is projected onto the learned latent factors.
6. **Classify using the trained factors:** The projected prompt is classified using the trained classifier. A question mark indicates the classification result.
7. **If layer wise Jailbreak Prob > threshold, layer might be showing more signals of jailbreak attack:** A conditional statement indicating that if the jailbreak probability for a layer exceeds a threshold, the layer is considered susceptible to jailbreak attacks.
8. **Layers in red are bypassed:** Layers identified as susceptible to jailbreak attacks are bypassed (highlighted in red).
9. **Layer bypass prevented harmful generation:** The diagram states that bypassing these layers prevents harmful generation.
### Key Observations
* The diagram highlights the importance of latent space analysis for identifying and mitigating jailbreak attacks.
* The use of CP decomposition to extract factors from the LLM layers is a key step in the process.
* The classifier is trained to distinguish between benign and jailbreak prompts based on these factors.
* During inference, the classifier is used to identify susceptible layers, which are then bypassed to prevent harmful generation.
* The diagram visually emphasizes the separation of benign and jailbreak prompts in the latent space.
### Interpretation
The diagram demonstrates a method for enhancing the security of LLMs against jailbreak attacks. By analyzing the latent representations of prompts, the system can identify layers that are vulnerable to manipulation and bypass them during inference. This approach aims to prevent the generation of harmful or unintended outputs. The use of CP decomposition suggests a dimensionality reduction technique to simplify the analysis of the high-dimensional latent space. The classifier acts as a gatekeeper, identifying potentially harmful prompts and triggering the bypassing mechanism. The diagram suggests a proactive approach to security, rather than relying solely on reactive measures. The conditional statement regarding the jailbreak probability threshold indicates a tunable parameter for controlling the sensitivity of the mitigation system. The diagram does not provide specific numerical data or performance metrics, but it clearly outlines the conceptual framework for a jailbreak mitigation strategy. The diagram is a conceptual illustration and does not provide details on the specific algorithms or implementation details used.